|
This version is still in development and is not considered stable yet. For the latest stable version, please use Spring Batch Documentation 5.1.2! |
|
This version is still in development and is not considered stable yet. For the latest stable version, please use Spring Batch Documentation 5.1.2! |
Like most enterprise application styles, a database is the central storage mechanism for batch. However, batch differs from other application styles due to the sheer size of the datasets with which the system must work. If a SQL statement returns 1 million rows, the result set probably holds all returned results in memory until all rows have been read. Spring Batch provides two types of solutions for this problem:
Cursor-based ItemReader Implementations
Using a database cursor is generally the default approach of most batch developers,
because it is the database’s solution to the problem of 'streaming' relational data. The
Java ResultSet class is essentially an object oriented mechanism for manipulating a
cursor. A ResultSet maintains a cursor to the current row of data. Calling next on a
ResultSet moves this cursor to the next row. The Spring Batch cursor-based ItemReader
implementation opens a cursor on initialization and moves the cursor forward one row for
every call to read, returning a mapped object that can be used for processing. The
close method is then called to ensure all resources are freed up. The Spring core
JdbcTemplate gets around this problem by using the callback pattern to completely map
all rows in a ResultSet and close before returning control back to the method caller.
However, in batch, this must wait until the step is complete. The following image shows a
generic diagram of how a cursor-based ItemReader works. Note that, while the example
uses SQL (because SQL is so widely known), any technology could implement the basic
approach.
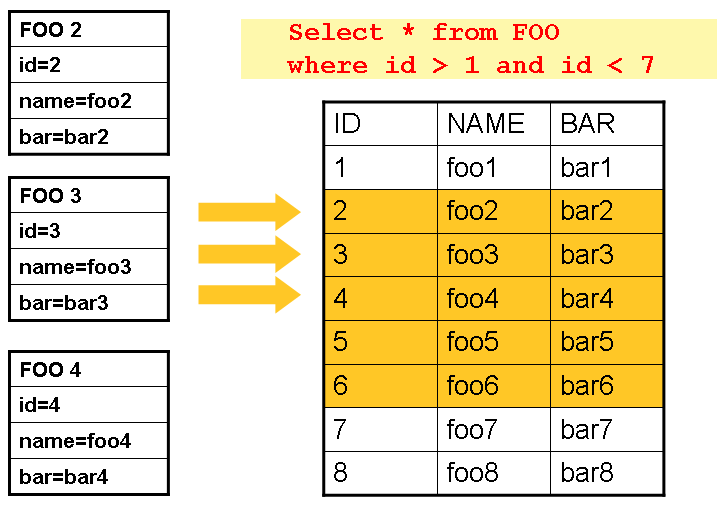
This example illustrates the basic pattern. Given a 'FOO' table, which has three columns:
ID, NAME, and BAR, select all rows with an ID greater than 1 but less than 7. This
puts the beginning of the cursor (row 1) on ID 2. The result of this row should be a
completely mapped Foo object. Calling read() again moves the cursor to the next row,
which is the Foo with an ID of 3. The results of these reads are written out after each
read, allowing the objects to be garbage collected (assuming no instance variables are
maintaining references to them).
JdbcCursorItemReader
JdbcCursorItemReader is the JDBC implementation of the cursor-based technique. It works
directly with a ResultSet and requires an SQL statement to run against a connection
obtained from a DataSource. The following database schema is used as an example:
CREATE TABLE CUSTOMER (
ID BIGINT IDENTITY PRIMARY KEY,
NAME VARCHAR(45),
CREDIT FLOAT
);Many people prefer to use a domain object for each row, so the following example uses an
implementation of the RowMapper interface to map a CustomerCredit object:
public class CustomerCreditRowMapper implements RowMapper<CustomerCredit> {
public static final String ID_COLUMN = "id";
public static final String NAME_COLUMN = "name";
public static final String CREDIT_COLUMN = "credit";
public CustomerCredit mapRow(ResultSet rs, int rowNum) throws SQLException {
CustomerCredit customerCredit = new CustomerCredit();
customerCredit.setId(rs.getInt(ID_COLUMN));
customerCredit.setName(rs.getString(NAME_COLUMN));
customerCredit.setCredit(rs.getBigDecimal(CREDIT_COLUMN));
return customerCredit;
}
}Because JdbcCursorItemReader shares key interfaces with JdbcTemplate, it is useful to
see an example of how to read in this data with JdbcTemplate, in order to contrast it
with the ItemReader. For the purposes of this example, assume there are 1,000 rows in
the CUSTOMER database. The first example uses JdbcTemplate:
//For simplicity sake, assume a dataSource has already been obtained
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
List customerCredits = jdbcTemplate.query("SELECT ID, NAME, CREDIT from CUSTOMER",
new CustomerCreditRowMapper());After running the preceding code snippet, the customerCredits list contains 1,000
CustomerCredit objects. In the query method, a connection is obtained from the
DataSource, the provided SQL is run against it, and the mapRow method is called for
each row in the ResultSet. Contrast this with the approach of the
JdbcCursorItemReader, shown in the following example:
JdbcCursorItemReader itemReader = new JdbcCursorItemReader();
itemReader.setDataSource(dataSource);
itemReader.setSql("SELECT ID, NAME, CREDIT from CUSTOMER");
itemReader.setRowMapper(new CustomerCreditRowMapper());
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close();After running the preceding code snippet, the counter equals 1,000. If the code above had
put the returned customerCredit into a list, the result would have been exactly the
same as with the JdbcTemplate example. However, the big advantage of the ItemReader
is that it allows items to be 'streamed'. The read method can be called once, the item
can be written out by an ItemWriter, and then the next item can be obtained with
read. This allows item reading and writing to be done in 'chunks' and committed
periodically, which is the essence of high performance batch processing. Furthermore, it
is easily configured for injection into a Spring Batch Step.
-
Java
-
XML
The following example shows how to inject an ItemReader into a Step in Java:
@Bean
public JdbcCursorItemReader<CustomerCredit> itemReader() {
return new JdbcCursorItemReaderBuilder<CustomerCredit>()
.dataSource(this.dataSource)
.name("creditReader")
.sql("select ID, NAME, CREDIT from CUSTOMER")
.rowMapper(new CustomerCreditRowMapper())
.build();
}The following example shows how to inject an ItemReader into a Step in XML:
<bean id="itemReader" class="org.spr...JdbcCursorItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="sql" value="select ID, NAME, CREDIT from CUSTOMER"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>Additional Properties
Because there are so many varying options for opening a cursor in Java, there are many
properties on the JdbcCursorItemReader that can be set, as described in the following
table:
ignoreWarnings |
Determines whether or not SQLWarnings are logged or cause an exception.
The default is |
fetchSize |
Gives the JDBC driver a hint as to the number of rows that should be fetched
from the database when more rows are needed by the |
maxRows |
Sets the limit for the maximum number of rows the underlying |
queryTimeout |
Sets the number of seconds the driver waits for a |
verifyCursorPosition |
Because the same |
saveState |
Indicates whether or not the reader’s state should be saved in the
|
driverSupportsAbsolute |
Indicates whether the JDBC driver supports
setting the absolute row on a |
setUseSharedExtendedConnection |
Indicates whether the connection
used for the cursor should be used by all other processing, thus sharing the same
transaction. If this is set to |
StoredProcedureItemReader
Sometimes it is necessary to obtain the cursor data by using a stored procedure. The
StoredProcedureItemReader works like the JdbcCursorItemReader, except that, instead
of running a query to obtain a cursor, it runs a stored procedure that returns a cursor.
The stored procedure can return the cursor in three different ways:
-
As a returned
ResultSet(used by SQL Server, Sybase, DB2, Derby, and MySQL). -
As a ref-cursor returned as an out parameter (used by Oracle and PostgreSQL).
-
As the return value of a stored function call.
-
Java
-
XML
The following Java example configuration uses the same 'customer credit' example as earlier examples:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
return reader;
}The following XML example configuration uses the same 'customer credit' example as earlier examples:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>The preceding example relies on the stored procedure to provide a ResultSet as a
returned result (option 1 from earlier).
If the stored procedure returned a ref-cursor (option 2), then we would need to provide
the position of the out parameter that is the returned ref-cursor.
-
Java
-
XML
The following example shows how to work with the first parameter being a ref-cursor in Java:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
reader.setRefCursorPosition(1);
return reader;
}The following example shows how to work with the first parameter being a ref-cursor in XML:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>If the cursor was returned from a stored function (option 3), we would need to set the
property "function" to true. It defaults to false.
-
Java
-
XML
The following example shows property to true in Java:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
reader.setFunction(true);
return reader;
}The following example shows property to true in XML:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="function" value="true"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>In all of these cases, we need to define a RowMapper as well as a DataSource and the
actual procedure name.
If the stored procedure or function takes in parameters, then they must be declared and
set by using the parameters property. The following example, for Oracle, declares three
parameters. The first one is the out parameter that returns the ref-cursor, and the
second and third are in parameters that takes a value of type INTEGER.
-
Java
-
XML
The following example shows how to work with parameters in Java:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
List<SqlParameter> parameters = new ArrayList<>();
parameters.add(new SqlOutParameter("newId", OracleTypes.CURSOR));
parameters.add(new SqlParameter("amount", Types.INTEGER);
parameters.add(new SqlParameter("custId", Types.INTEGER);
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("spring.cursor_func");
reader.setParameters(parameters);
reader.setRefCursorPosition(1);
reader.setRowMapper(rowMapper());
reader.setPreparedStatementSetter(parameterSetter());
return reader;
}The following example shows how to work with parameters in XML:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="spring.cursor_func"/>
<property name="parameters">
<list>
<bean class="org.springframework.jdbc.core.SqlOutParameter">
<constructor-arg index="0" value="newid"/>
<constructor-arg index="1">
<util:constant static-field="oracle.jdbc.OracleTypes.CURSOR"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="amount"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="custid"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
</list>
</property>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper" ref="rowMapper"/>
<property name="preparedStatementSetter" ref="parameterSetter"/>
</bean>In addition to the parameter declarations, we need to specify a PreparedStatementSetter
implementation that sets the parameter values for the call. This works the same as for
the JdbcCursorItemReader above. All the additional properties listed in
Additional Properties apply to the StoredProcedureItemReader as well.
ignoreWarnings |
Determines whether or not SQLWarnings are logged or cause an exception.
The default is |
fetchSize |
Gives the JDBC driver a hint as to the number of rows that should be fetched
from the database when more rows are needed by the |
maxRows |
Sets the limit for the maximum number of rows the underlying |
queryTimeout |
Sets the number of seconds the driver waits for a |
verifyCursorPosition |
Because the same |
saveState |
Indicates whether or not the reader’s state should be saved in the
|
driverSupportsAbsolute |
Indicates whether the JDBC driver supports
setting the absolute row on a |
setUseSharedExtendedConnection |
Indicates whether the connection
used for the cursor should be used by all other processing, thus sharing the same
transaction. If this is set to |
Paging ItemReader Implementations
An alternative to using a database cursor is running multiple queries where each query fetches a portion of the results. We refer to this portion as a page. Each query must specify the starting row number and the number of rows that we want returned in the page.
JdbcPagingItemReader
One implementation of a paging ItemReader is the JdbcPagingItemReader. The
JdbcPagingItemReader needs a PagingQueryProvider responsible for providing the SQL
queries used to retrieve the rows making up a page. Since each database has its own
strategy for providing paging support, we need to use a different PagingQueryProvider
for each supported database type. There is also the SqlPagingQueryProviderFactoryBean
that auto-detects the database that is being used and determine the appropriate
PagingQueryProvider implementation. This simplifies the configuration and is the
recommended best practice.
The SqlPagingQueryProviderFactoryBean requires that you specify a select clause and a
from clause. You can also provide an optional where clause. These clauses and the
required sortKey are used to build an SQL statement.
It is important to have a unique key constraint on the sortKey to guarantee that
no data is lost between executions.
|
After the reader has been opened, it passes back one item per call to read in the same
basic fashion as any other ItemReader. The paging happens behind the scenes when
additional rows are needed.
-
Java
-
XML
The following Java example configuration uses a similar 'customer credit' example as the
cursor-based ItemReaders shown previously:
@Bean
public JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider() {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name, credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
return provider;
}The following XML example configuration uses a similar 'customer credit' example as the
cursor-based ItemReaders shown previously:
<bean id="itemReader" class="org.spr...JdbcPagingItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="queryProvider">
<bean class="org.spr...SqlPagingQueryProviderFactoryBean">
<property name="selectClause" value="select id, name, credit"/>
<property name="fromClause" value="from customer"/>
<property name="whereClause" value="where status=:status"/>
<property name="sortKey" value="id"/>
</bean>
</property>
<property name="parameterValues">
<map>
<entry key="status" value="NEW"/>
</map>
</property>
<property name="pageSize" value="1000"/>
<property name="rowMapper" ref="customerMapper"/>
</bean>This configured ItemReader returns CustomerCredit objects using the RowMapper,
which must be specified. The 'pageSize' property determines the number of entities read
from the database for each query run.
The 'parameterValues' property can be used to specify a Map of parameter values for the
query. If you use named parameters in the where clause, the key for each entry should
match the name of the named parameter. If you use a traditional '?' placeholder, then the
key for each entry should be the number of the placeholder, starting with 1.
JpaPagingItemReader
Another implementation of a paging ItemReader is the JpaPagingItemReader. JPA does
not have a concept similar to the Hibernate StatelessSession, so we have to use other
features provided by the JPA specification. Since JPA supports paging, this is a natural
choice when it comes to using JPA for batch processing. After each page is read, the
entities become detached and the persistence context is cleared, to allow the entities to
be garbage collected once the page is processed.
The JpaPagingItemReader lets you declare a JPQL statement and pass in a
EntityManagerFactory. It then passes back one item per call to read in the same basic
fashion as any other ItemReader. The paging happens behind the scenes when additional
entities are needed.
-
Java
-
XML
The following Java example configuration uses the same 'customer credit' example as the JDBC reader shown previously:
@Bean
public JpaPagingItemReader itemReader() {
return new JpaPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.entityManagerFactory(entityManagerFactory())
.queryString("select c from CustomerCredit c")
.pageSize(1000)
.build();
}The following XML example configuration uses the same 'customer credit' example as the JDBC reader shown previously:
<bean id="itemReader" class="org.spr...JpaPagingItemReader">
<property name="entityManagerFactory" ref="entityManagerFactory"/>
<property name="queryString" value="select c from CustomerCredit c"/>
<property name="pageSize" value="1000"/>
</bean>This configured ItemReader returns CustomerCredit objects in the exact same manner as
described for the JdbcPagingItemReader above, assuming the CustomerCredit object has the
correct JPA annotations or ORM mapping file. The 'pageSize' property determines the
number of entities read from the database for each query execution.
It is important to have a unique key constraint on the sortKey to guarantee that
no data is lost between executions.
|
Database ItemWriters
While both flat files and XML files have a specific ItemWriter instance, there is no exact equivalent
in the database world. This is because transactions provide all the needed functionality.
ItemWriter implementations are necessary for files because they must act as if they’re transactional,
keeping track of written items and flushing or clearing at the appropriate times.
Databases have no need for this functionality, since the write is already contained in a
transaction. Users can create their own DAOs that implement the ItemWriter interface or
use one from a custom ItemWriter that’s written for generic processing concerns. Either
way, they should work without any issues. One thing to look out for is the performance
and error handling capabilities that are provided by batching the outputs. This is most
common when using hibernate as an ItemWriter but could have the same issues when using
JDBC batch mode. Batching database output does not have any inherent flaws, assuming we
are careful to flush and there are no errors in the data. However, any errors while
writing can cause confusion, because there is no way to know which individual item caused
an exception or even if any individual item was responsible, as illustrated in the
following image:
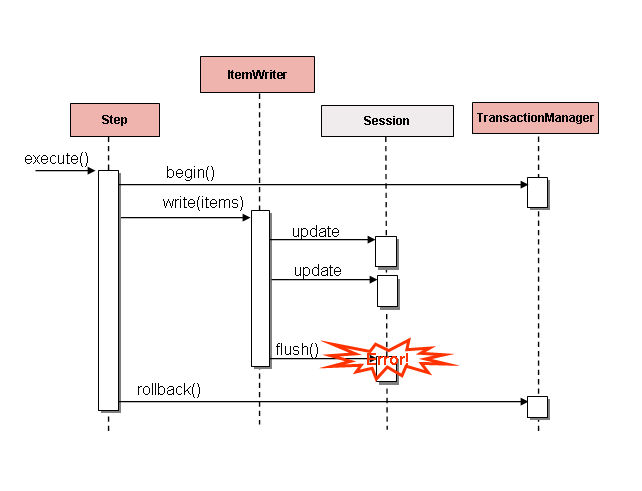
If items are buffered before being written, any errors are not thrown until the buffer is
flushed just before a commit. For example, assume that 20 items are written per chunk,
and the 15th item throws a DataIntegrityViolationException. As far as the Step
is concerned, all 20 item are written successfully, since there is no way to know that an
error occurs until they are actually written. Once Session#flush() is called, the
buffer is emptied and the exception is hit. At this point, there is nothing the Step
can do. The transaction must be rolled back. Normally, this exception might cause the
item to be skipped (depending upon the skip/retry policies), and then it is not written
again. However, in the batched scenario, there is no way to know which item caused the
issue. The whole buffer was being written when the failure happened. The only way to
solve this issue is to flush after each item, as shown in the following image:
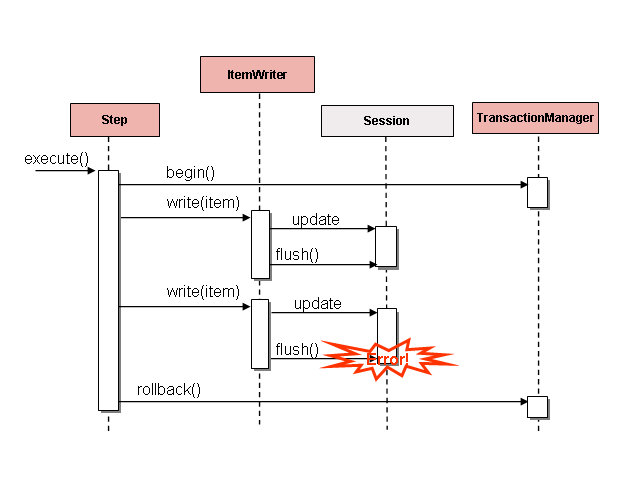
This is a common use case, especially when using Hibernate, and the simple guideline for
implementations of ItemWriter is to flush on each call to write(). Doing so allows
for items to be skipped reliably, with Spring Batch internally taking care of the
granularity of the calls to ItemWriter after an error.