|
此版本仍在开发中,尚未被视为稳定版本。对于最新的稳定版本,请使用 Spring Batch 文档 5.1.2! |
|
此版本仍在开发中,尚未被视为稳定版本。对于最新的稳定版本,请使用 Spring Batch 文档 5.1.2! |
与大多数企业应用程序样式一样,数据库是 批。但是,由于 系统必须使用的数据集。如果 SQL 语句返回 100 万行,则 结果集可能会将所有返回的结果保存在内存中,直到读取完所有行。 Spring Batch 为此问题提供了两种类型的解决方案:
基于游标的实现ItemReader
使用数据库游标通常是大多数批处理开发人员的默认方法。
因为它是数据库对 “流” 关系数据问题的解决方案。这
Java 类本质上是一种面向对象的机制,用于操作
光标。A 维护当前数据行的游标。调用 a 会将此光标移动到下一行。Spring Batch 基于游标的实现在初始化时打开一个游标,并将游标向前移动一行
每次调用 ,都会返回一个可用于处理的映射对象。然后调用该方法以确保释放所有资源。Spring 核心通过使用回调模式来完全映射
中的所有行 a 和 close 在将控制权返回给方法调用方之前。
但是,在 Batch 中,这必须等到步骤完成。下图显示了
基于游标的工作原理的通用图。请注意,虽然示例
使用 SQL(因为 SQL 是如此广为人知),任何技术都可以实现基本的
方法。ResultSetResultSetnextResultSetItemReaderreadcloseJdbcTemplateResultSetItemReader
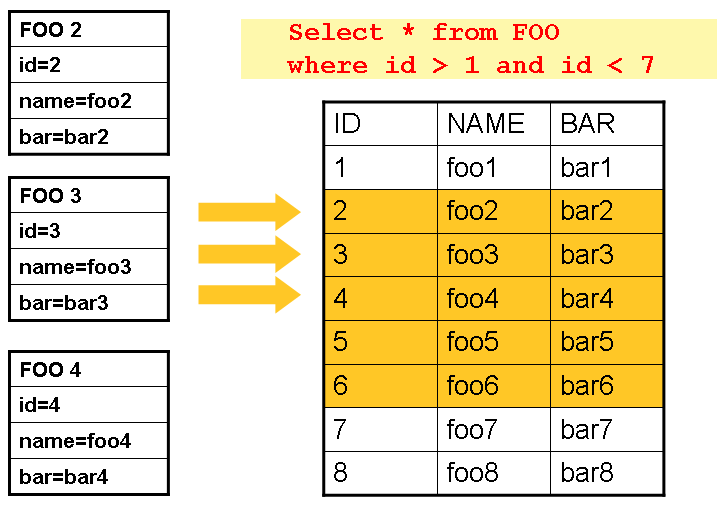
此示例说明了基本模式。给定一个 'FOO' 表,它有三列: , , 和 ,选择 ID 大于 1 但小于 7 的所有行。这
将光标的开头(第 1 行)放在 ID 2 上。此行的结果应为
完全映射的对象。再次调用会将光标移动到下一行
,即 ID 为 3 的 。这些读取的结果在每个 之后写出,允许对对象进行垃圾回收(假设没有实例变量
维护对它们的引用)。IDNAMEBARFooread()Fooread
JdbcCursorItemReader
JdbcCursorItemReader是基于游标的技术的 JDBC 实现。它有效
直接与 a 一起使用,并且需要针对连接运行 SQL 语句
从 .以下数据库架构用作示例:ResultSetDataSource
CREATE TABLE CUSTOMER (
ID BIGINT IDENTITY PRIMARY KEY,
NAME VARCHAR(45),
CREDIT FLOAT
);许多人喜欢对每一行使用域对象,因此以下示例使用
映射对象的接口的实现:RowMapperCustomerCredit
public class CustomerCreditRowMapper implements RowMapper<CustomerCredit> {
public static final String ID_COLUMN = "id";
public static final String NAME_COLUMN = "name";
public static final String CREDIT_COLUMN = "credit";
public CustomerCredit mapRow(ResultSet rs, int rowNum) throws SQLException {
CustomerCredit customerCredit = new CustomerCredit();
customerCredit.setId(rs.getInt(ID_COLUMN));
customerCredit.setName(rs.getString(NAME_COLUMN));
customerCredit.setCredit(rs.getBigDecimal(CREDIT_COLUMN));
return customerCredit;
}
}由于 共享 关键接口 ,因此 对于
请参阅如何使用 读取此数据以对其进行对比的示例
使用 .对于此示例,假设 中有 1,000 行
数据库。第一个示例使用 :JdbcCursorItemReaderJdbcTemplateJdbcTemplateItemReaderCUSTOMERJdbcTemplate
//For simplicity sake, assume a dataSource has already been obtained
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
List customerCredits = jdbcTemplate.query("SELECT ID, NAME, CREDIT from CUSTOMER",
new CustomerCreditRowMapper());运行上述代码片段后,该列表包含 1000 个对象。在查询方法中,从 获取连接,对它运行提供的 SQL,并调用
.将此方法与以下示例中所示的 , 的方法进行对比:customerCreditsCustomerCreditDataSourcemapRowResultSetJdbcCursorItemReader
JdbcCursorItemReader itemReader = new JdbcCursorItemReader();
itemReader.setDataSource(dataSource);
itemReader.setSql("SELECT ID, NAME, CREDIT from CUSTOMER");
itemReader.setRowMapper(new CustomerCreditRowMapper());
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close();运行上述代码片段后,计数器等于 1,000。如果上面的代码有
将 return 放入列表中,结果将恰好是
与示例相同。但是,它的最大优点是它允许 “流” 项。该方法可以调用一次,项
可以由 写出 ,然后可以使用 获得下一项。这允许以 'chunks' 的形式完成项目读取和写入并提交
定期,这是高性能批处理的本质。此外,它
很容易配置为注入 Spring Batch 。customerCreditJdbcTemplateItemReaderreadItemWriterreadStep
-
Java
-
XML
下面的示例展示了如何在 Java 中将 an 注入到 a 中:ItemReaderStep
@Bean
public JdbcCursorItemReader<CustomerCredit> itemReader() {
return new JdbcCursorItemReaderBuilder<CustomerCredit>()
.dataSource(this.dataSource)
.name("creditReader")
.sql("select ID, NAME, CREDIT from CUSTOMER")
.rowMapper(new CustomerCreditRowMapper())
.build();
}下面的示例演示如何将 an 注入到 XML 中:ItemReaderStep
<bean id="itemReader" class="org.spr...JdbcCursorItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="sql" value="select ID, NAME, CREDIT from CUSTOMER"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>其他属性
因为在 Java 中打开游标有很多不同的选项,所以有很多
属性,如下所述
桌子:JdbcCursorItemReader
忽略警告 |
确定是记录 SQLWarnings 还是导致异常。
默认值为 (意味着记录警告)。 |
fetchSize (获取大小) |
为 JDBC 驱动程序提供有关应获取的行数的提示
当 .默认情况下,不会给出任何提示。 |
最大行数 |
设置基础可以的最大行数限制
hold 在任何时候。 |
查询超时 |
将驱动程序等待对象的秒数设置为
跑。如果超出限制,则抛出 a。(请咨询您的Drivers
vendor 文档了解详情)。 |
verifyCursorPosition |
因为 持有的相同内容被传递给
的 ,用户可以称呼自己,这
可能会导致读取器的内部计数出现问题。将此值设置为 causes
如果调用后光标位置与之前不同,则引发异常。 |
saveState |
指示是否应将读取器的状态保存在 提供的 中。默认值为 . |
driverSupportsAbsolute |
指示 JDBC 驱动程序是否支持
在 .对于支持 的 JDBC 驱动程序,建议将其设置为 ,因为它可以提高性能。
尤其是在处理大型数据集时某个步骤失败时。默认为 。 |
setUseSharedExtendedConnection |
指示连接
used for cursor 应该被所有其他处理使用,从而共享相同的
交易。如果此项设置为 ,则游标将以其自己的连接打开
并且不参与为其余步骤处理启动的任何事务。
如果将此标志设置为 then 则必须将 DataSource 包装在 an 中以防止连接关闭,并且
在每次提交后释放。当您将此选项设置为 时,语句用于
Open the Cursor 是使用 'READ_ONLY' 和 'HOLD_CURSORS_OVER_COMMIT' 选项创建的。
这允许在事务启动和在
步骤处理。要使用此功能,您需要一个支持此功能的数据库和一个 JDBC
支持 JDBC 3.0 或更高版本的驱动程序。默认为 。 |
StoredProcedureItemReader
有时需要使用存储过程来获取游标数据。其工作原理类似于 ,不同之处在于,它
运行查询以获取游标时,它会运行返回游标的存储过程。
存储过程可以通过三种不同的方式返回游标:StoredProcedureItemReaderJdbcCursorItemReader
-
作为返回值(由 SQL Server、Sybase、DB2、Derby 和 MySQL 使用)。
ResultSet -
作为作为 out 参数返回的 ref 游标(由 Oracle 和 PostgreSQL 使用)。
-
作为存储函数调用的返回值。
-
Java
-
XML
以下 Java 示例配置使用与 前面的例子:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
return reader;
}以下 XML 示例配置使用与前面相同的 'customer credit' 示例 例子:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>前面的示例依赖于存储过程以
返回结果(前面的选项 1)。ResultSet
如果存储过程返回 (选项 2),那么我们需要提供
返回的 out 参数的位置。ref-cursorref-cursor
-
Java
-
XML
以下示例显示了如何使用第一个参数作为 Java:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
reader.setRefCursorPosition(1);
return reader;
}以下示例显示了如何使用第一个参数作为 XML:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>如果游标是从存储函数返回的(选项 3),我们需要将
property “function” 设置为 .它默认为 .truefalse
-
Java
-
XML
以下示例显示了 Java 中的 property to:true
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
reader.setFunction(true);
return reader;
}以下示例显示了 XML 中的属性 to:true
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="function" value="true"/>
<property name="rowMapper">
<bean class="org.springframework.batch.samples.domain.CustomerCreditRowMapper"/>
</property>
</bean>在所有这些情况下,我们都需要定义 a 以及 a 和
实际过程名称。RowMapperDataSource
如果存储过程或函数接受参数,则必须声明它们并
set (设置)。以下示例(对于 Oracle)声明了三个
参数。第一个是返回 ref-cursor 的参数,而
第二个和第三个是采用 type 为 的值的 in parameters 。parametersoutINTEGER
-
Java
-
XML
以下示例演示如何在 Java 中使用参数:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
List<SqlParameter> parameters = new ArrayList<>();
parameters.add(new SqlOutParameter("newId", OracleTypes.CURSOR));
parameters.add(new SqlParameter("amount", Types.INTEGER);
parameters.add(new SqlParameter("custId", Types.INTEGER);
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("spring.cursor_func");
reader.setParameters(parameters);
reader.setRefCursorPosition(1);
reader.setRowMapper(rowMapper());
reader.setPreparedStatementSetter(parameterSetter());
return reader;
}以下示例演示如何在 XML 中使用参数:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="spring.cursor_func"/>
<property name="parameters">
<list>
<bean class="org.springframework.jdbc.core.SqlOutParameter">
<constructor-arg index="0" value="newid"/>
<constructor-arg index="1">
<util:constant static-field="oracle.jdbc.OracleTypes.CURSOR"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="amount"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="custid"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
</list>
</property>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper" ref="rowMapper"/>
<property name="preparedStatementSetter" ref="parameterSetter"/>
</bean>除了参数声明之外,我们还需要指定一个 implementation 来设置调用的参数值。这与
以上。Additional Properties 中列出的所有其他属性也适用于 。PreparedStatementSetterJdbcCursorItemReaderStoredProcedureItemReader
忽略警告 |
确定是记录 SQLWarnings 还是导致异常。
默认值为 (意味着记录警告)。 |
fetchSize (获取大小) |
为 JDBC 驱动程序提供有关应获取的行数的提示
当 .默认情况下,不会给出任何提示。 |
最大行数 |
设置基础可以的最大行数限制
hold 在任何时候。 |
查询超时 |
将驱动程序等待对象的秒数设置为
跑。如果超出限制,则抛出 a。(请咨询您的Drivers
vendor 文档了解详情)。 |
verifyCursorPosition |
因为 持有的相同内容被传递给
的 ,用户可以称呼自己,这
可能会导致读取器的内部计数出现问题。将此值设置为 causes
如果调用后光标位置与之前不同,则引发异常。 |
saveState |
指示是否应将读取器的状态保存在 提供的 中。默认值为 . |
driverSupportsAbsolute |
指示 JDBC 驱动程序是否支持
在 .对于支持 的 JDBC 驱动程序,建议将其设置为 ,因为它可以提高性能。
尤其是在处理大型数据集时某个步骤失败时。默认为 。 |
setUseSharedExtendedConnection |
指示连接
used for cursor 应该被所有其他处理使用,从而共享相同的
交易。如果此项设置为 ,则游标将以其自己的连接打开
并且不参与为其余步骤处理启动的任何事务。
如果将此标志设置为 then 则必须将 DataSource 包装在 an 中以防止连接关闭,并且
在每次提交后释放。当您将此选项设置为 时,语句用于
Open the Cursor 是使用 'READ_ONLY' 和 'HOLD_CURSORS_OVER_COMMIT' 选项创建的。
这允许在事务启动和在
步骤处理。要使用此功能,您需要一个支持此功能的数据库和一个 JDBC
支持 JDBC 3.0 或更高版本的驱动程序。默认为 。 |
分页实现ItemReader
使用数据库游标的另一种方法是运行多个查询,其中每个查询 获取结果的一部分。我们将此部分称为页面。每个查询必须 指定 起始行号 和我们希望在页面中返回的行数。
JdbcPagingItemReader
分页的一种实现是 .需要 a 负责提供 SQL
用于检索构成页面的行的查询。由于每个数据库都有自己的
策略来提供分页支持,我们需要对每个支持的数据库类型使用不同的数据库类型。还有一种是自动检测正在使用的数据库并确定适当的实现。这简化了配置,并且是
推荐的最佳实践。ItemReaderJdbcPagingItemReaderJdbcPagingItemReaderPagingQueryProviderPagingQueryProviderSqlPagingQueryProviderFactoryBeanPagingQueryProvider
这需要您指定一个子句和一个子句。您还可以提供可选子句。这些条款和
required 用于构建 SQL 语句。SqlPagingQueryProviderFactoryBeanselectfromwheresortKey
在 上有一个唯一的 key constraint 是很重要的,以保证
执行之间不会丢失任何数据。sortKey |
打开读取器后,它会将每次调用传回一个项目
基本时尚 .分页发生在幕后,当
需要额外的行。readItemReader
-
Java
-
XML
以下 Java 示例配置使用与
cursor-based 如前所述:ItemReaders
@Bean
public JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider() {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name, credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
return provider;
}以下 XML 示例配置使用与
cursor-based 如前所述:ItemReaders
<bean id="itemReader" class="org.spr...JdbcPagingItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="queryProvider">
<bean class="org.spr...SqlPagingQueryProviderFactoryBean">
<property name="selectClause" value="select id, name, credit"/>
<property name="fromClause" value="from customer"/>
<property name="whereClause" value="where status=:status"/>
<property name="sortKey" value="id"/>
</bean>
</property>
<property name="parameterValues">
<map>
<entry key="status" value="NEW"/>
</map>
</property>
<property name="pageSize" value="1000"/>
<property name="rowMapper" ref="customerMapper"/>
</bean>此配置使用 、
必须指定。'pageSize' 属性确定读取的实体数量
从数据库进行每个查询运行。ItemReaderCustomerCreditRowMapper
'parameterValues' 属性可用于为
查询。如果在子句中使用命名参数,则每个条目的键应
匹配命名参数的名称。如果您使用传统的 '?' 占位符,则
key 应该是占位符的编号,从 1 开始。Mapwhere
JpaPagingItemReader
分页的另一种实现是 .JPA 执行
没有类似于 Hibernate 的概念,所以我们不得不使用其他
功能。由于 JPA 支持分页,因此这是很自然的
在使用 JPA 进行批处理时的选择。读取每个页面后,
实体将分离,并且持久化上下文将被清除,以允许实体
在页面处理完毕后进行垃圾回收。ItemReaderJpaPagingItemReaderStatelessSession
允许您声明 JPQL 语句并传入 .然后,它每次调用传回一个项目以读取相同的基本
时尚和其他任何 .分页发生在幕后,当额外的
entities 是必需的。JpaPagingItemReaderEntityManagerFactoryItemReader
-
Java
-
XML
以下 Java 示例配置使用与 前面显示的 JDBC 读取器:
@Bean
public JpaPagingItemReader itemReader() {
return new JpaPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.entityManagerFactory(entityManagerFactory())
.queryString("select c from CustomerCredit c")
.pageSize(1000)
.build();
}以下 XML 示例配置使用与 前面显示的 JDBC 读取器:
<bean id="itemReader" class="org.spr...JpaPagingItemReader">
<property name="entityManagerFactory" ref="entityManagerFactory"/>
<property name="queryString" value="select c from CustomerCredit c"/>
<property name="pageSize" value="1000"/>
</bean>此 configured 以与
,假设对象具有
正确的 JPA 注释或 ORM 映射文件。'pageSize' 属性确定
每次查询执行从数据库中读取的实体数。ItemReaderCustomerCreditJdbcPagingItemReaderCustomerCredit
在 上有一个唯一的 key constraint 是很重要的,以保证
执行之间不会丢失任何数据。sortKey |
数据库 ItemWriters
虽然平面文件和 XML 文件都有特定的实例,但没有完全相同的实例
在数据库世界中。这是因为交易提供了所有需要的功能。 实现对于 Files 来说是必需的,因为它们必须像事务一样运行,
跟踪写入的项目并在适当的时候进行冲洗或清理。
数据库不需要此功能,因为写入已经包含在
交易。用户可以创建自己的 DAO 来实现接口或
使用自定义中为通用处理问题编写的 ONE。也
方式,它们应该可以正常工作。需要注意的一件事是性能
以及通过批处理输出提供的错误处理功能。这是最
在使用 Hibernate 时很常见,但在使用
JDBC 批处理模式。批处理数据库输出没有任何固有的缺陷,假设我们
请小心刷新,并且数据中没有错误。但是,任何
写入可能会引起混淆,因为无法知道是哪个单独的项目引起的
异常,或者即使任何单个项目负责,如
下图:ItemWriterItemWriterItemWriterItemWriterItemWriter
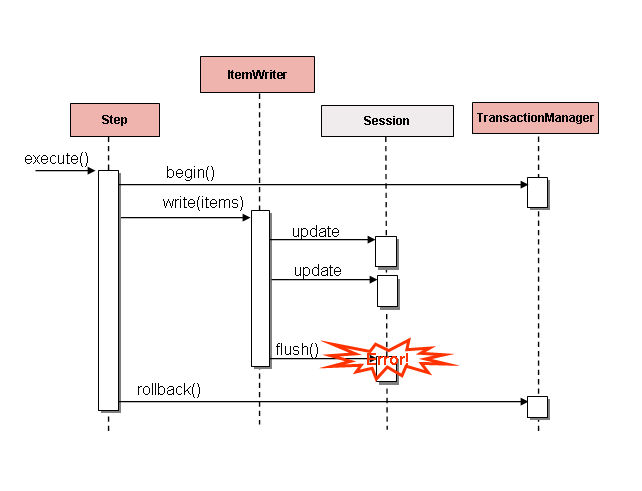
如果在写入之前缓冲了项,则在缓冲区
flushed 的 SET 文件。例如,假设每个块写入 20 个项目,
第 15 项抛出 .就 而言,所有 20 项都写入成功了,因为没有办法知道
错误会发生,直到它们被实际写入为止。调用 None 后,
buffer 被清空并命中异常。在这一点上,他们无能为力。必须回滚事务。通常,此异常可能会导致
要跳过的项目(取决于跳过/重试策略),然后不写入
再。但是,在批处理场景中,无法知道是哪个项目导致了
问题。发生故障时,正在写入整个缓冲区。唯一的方法
解决此问题是在每个项后刷新,如下图所示:DataIntegrityViolationExceptionStepSession#flush()Step
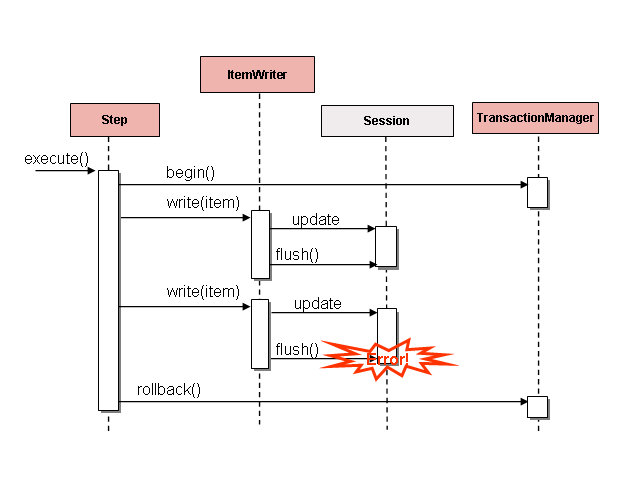
这是一个常见的用例,尤其是在使用 Hibernate 时,以及
的实现 is 在每次调用 .这样做允许
为了可靠地跳过项目,Spring Batch 在内部负责
在错误后调用 的粒度。ItemWriterwrite()ItemWriter