|
此版本仍在开发中,尚未被视为稳定版本。最新的快照版本请使用 Spring AI 1.0.0-SNAPSHOT! |
ETL 管道
提取、转换和加载 (ETL) 框架是检索增强生成 (RAG) 用例中数据处理的主干。
ETL 管道编排从原始数据源到结构化向量存储的流程,确保数据处于最佳格式,以便 AI 模型进行检索。
RAG 用例是文本,通过从数据主体中检索相关信息来提高生成输出的质量和相关性,从而增强生成模型的功能。
API 概述
ETL 管道创建、转换和存储Document实例。
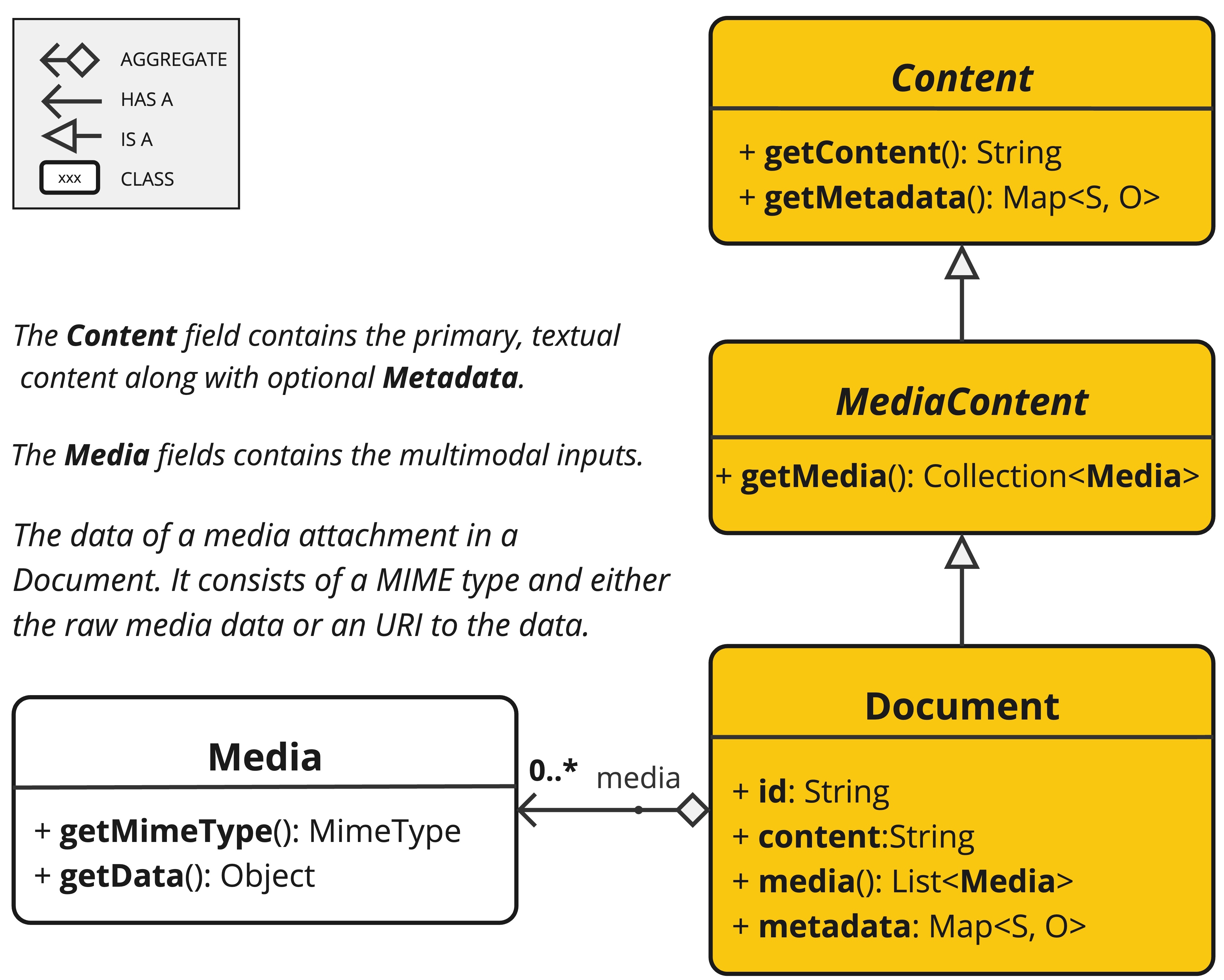
这Document类包含文本、元数据和可选的 AdditionAll 媒体类型,如图像、音频和视频。
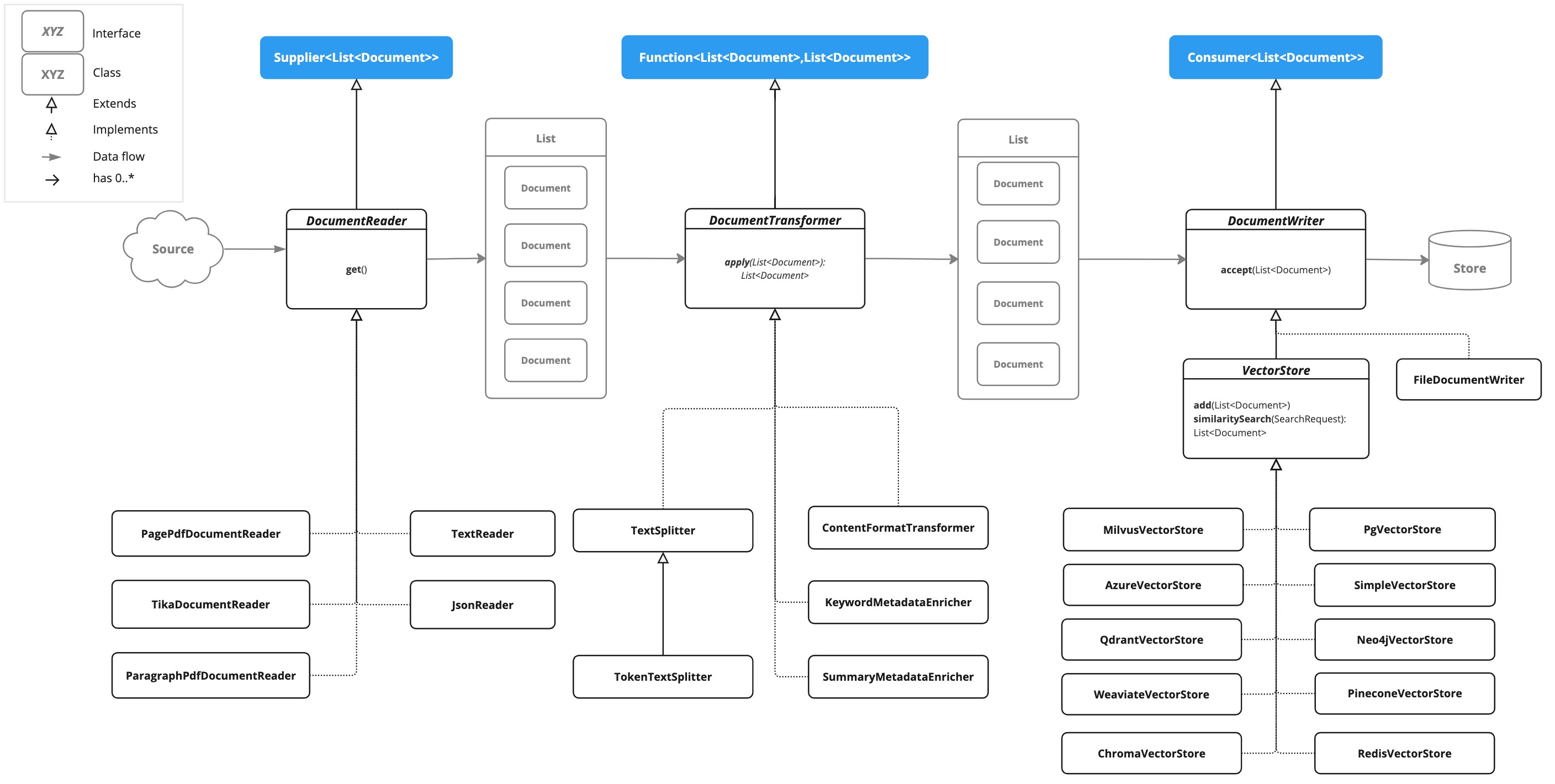
ETL 管道有三个主要组件:
-
DocumentReader实现Supplier<List<Document>> -
DocumentTransformer实现Function<List<Document>, List<Document>> -
DocumentWriter实现Consumer<List<Document>>
这Document类内容是在 PDF、文本文件和其他文档类型的帮助下创建的DocumentReader.
要构建简单的 ETL 管道,您可以将每种类型的实例链接在一起。

假设我们有这三种 ETL 类型的以下实例
-
PagePdfDocumentReader的实现DocumentReader -
TokenTextSplitter的实现DocumentTransformer -
VectorStore的实现DocumentWriter
要执行将数据基本加载到 Vector Database 中以用于 Retrieval Augmented Generation 模式的作,请使用以下 Java 函数样式语法代码。
vectorStore.accept(tokenTextSplitter.apply(pdfReader.get()));或者,您可以使用对域更自然地表达的方法名称
vectorStore.write(tokenTextSplitter.split(pdfReader.read()));ETL 接口
ETL 管道由以下接口和实现组成。 详细的 ETL 类图显示在 ETL 类图部分中。
文档阅读器
提供来自不同来源的文档源。
public interface DocumentReader extends Supplier<List<Document>> {
default List<Document> read() {
return get();
}
}文档Transformer
在处理工作流中转换一批文档。
public interface DocumentTransformer extends Function<List<Document>, List<Document>> {
default List<Document> transform(List<Document> transform) {
return apply(transform);
}
}
文档读者
JSON 格式
这JsonReader处理 JSON 文档,并将其转换为Document对象。
例
@Component
class MyJsonReader {
private final Resource resource;
MyJsonReader(@Value("classpath:bikes.json") Resource resource) {
this.resource = resource;
}
List<Document> loadJsonAsDocuments() {
JsonReader jsonReader = new JsonReader(this.resource, "description", "content");
return jsonReader.get();
}
}构造函数选项
这JsonReader提供了几个构造函数选项:
-
JsonReader(Resource resource) -
JsonReader(Resource resource, String… jsonKeysToUse) -
JsonReader(Resource resource, JsonMetadataGenerator jsonMetadataGenerator, String… jsonKeysToUse)
参数
-
resource: 弹簧Resource对象指向 JSON 文件。 -
jsonKeysToUse:JSON 中的键数组,应用作结果中的文本内容Document对象。 -
jsonMetadataGenerator:可选JsonMetadataGenerator为每个Document.
行为
这JsonReader按如下方式处理 JSON 内容:
-
它可以处理 JSON 数组和单个 JSON 对象。
-
对于每个 JSON 对象(在数组或单个对象中):
-
它根据指定的
jsonKeysToUse. -
如果未指定键,则使用整个 JSON 对象作为内容。
-
它使用提供的
JsonMetadataGenerator(如果未提供,则为空)。 -
它会创建一个
Document对象。
-
使用 JSON 指针
这JsonReader现在支持使用 JSON 指针检索 JSON 文档的特定部分。此功能允许您轻松地从复杂的 JSON 结构中提取嵌套数据。
示例 JSON 结构
[
{
"id": 1,
"brand": "Trek",
"description": "A high-performance mountain bike for trail riding."
},
{
"id": 2,
"brand": "Cannondale",
"description": "An aerodynamic road bike for racing enthusiasts."
}
]在此示例中,如果JsonReader配置了"description"作为jsonKeysToUse,它将创建Document对象,其中 content 是数组中每辆 bike 的 “description” 字段的值。
发短信
这TextReader处理纯文本文档,将它们转换为Document对象。
例
@Component
class MyTextReader {
private final Resource resource;
MyTextReader(@Value("classpath:text-source.txt") Resource resource) {
this.resource = resource;
}
List<Document> loadText() {
TextReader textReader = new TextReader(this.resource);
textReader.getCustomMetadata().put("filename", "text-source.txt");
return textReader.read();
}
}配置
-
setCharset(Charset charset):设置用于读取文本文件的字符集。默认值为 UTF-8。 -
getCustomMetadata():返回一个可变映射,您可以在其中为文档添加自定义元数据。
行为
这TextReader按如下方式处理文本内容:
-
它将文本文件的全部内容读取到一个
Document对象。 -
文件的内容将成为
Document. -
元数据会自动添加到
Document:-
charset:用于读取文件的字符集(默认值:“UTF-8”)。 -
source:源文本文件的文件名。
-
-
通过
getCustomMetadata()包含在Document.
笔记
-
这
TextReader将整个文件内容读取到内存中,因此它可能不适合非常大的文件。 -
如果您需要将文本拆分为较小的块,您可以使用文本拆分器,例如
TokenTextSplitter阅读文档后:
List<Document> documents = textReader.get();
List<Document> splitDocuments = new TokenTextSplitter().apply(this.documents);-
Reader 使用 Spring 的
Resourceabstraction 的 API 中读取,允许它从各种来源(类路径、文件系统、URL 等)读取。 -
自定义元数据可以添加到读者使用
getCustomMetadata()方法。
Markdown
这MarkdownDocumentReader处理 Markdown 文档,将它们转换为Document对象。
例
@Component
class MyMarkdownReader {
private final Resource resource;
MyMarkdownReader(@Value("classpath:code.md") Resource resource) {
this.resource = resource;
}
List<Document> loadMarkdown() {
MarkdownDocumentReaderConfig config = MarkdownDocumentReaderConfig.builder()
.withHorizontalRuleCreateDocument(true)
.withIncludeCodeBlock(false)
.withIncludeBlockquote(false)
.withAdditionalMetadata("filename", "code.md")
.build();
MarkdownDocumentReader reader = new MarkdownDocumentReader(this.resource, config);
return reader.get();
}
}这MarkdownDocumentReaderConfig允许您自定义 MarkdownDocumentReader 的行为:
-
horizontalRuleCreateDocument:设置为true,Markdown 中的水平线将创建新的Document对象。 -
includeCodeBlock:设置为true,则代码块将包含在相同的Document作为周围的文本。什么时候false,代码块创建单独的Document对象。 -
includeBlockquote:设置为true,blockquotes 将包含在相同的Document作为周围的文本。什么时候false,块引用创建单独的Document对象。 -
additionalMetadata:允许您将自定义元数据添加到所有创建的Document对象。
示例文档:code.md
This is a Java sample application:
```java
package com.example.demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
}
```
Markdown also provides the possibility to `use inline code formatting throughout` the entire sentence.
---
Another possibility is to set block code without specific highlighting:
```
./mvnw spring-javaformat:apply
```行为:MarkdownDocumentReader 处理 Markdown 内容并根据配置创建 Document 对象:
-
标题将成为 Document 对象中的元数据。
-
段落成为 Document 对象的内容。
-
代码块可以分隔到它们自己的 Document 对象中,也可以包含在周围的文本中。
-
块引用可以分隔到它们自己的 Document 对象中,也可以包含在周围的文本中。
-
水平线可用于将内容拆分为单独的 Document 对象。
Reader 在 Document 对象的内容中保留内联代码、列表和文本样式等格式。
PDF 页面
这PagePdfDocumentReader使用 Apache PdfBox 库解析 PDF 文档
使用 Maven 或 Gradle 将依赖项添加到您的项目中。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>或发送到您的 Gradlebuild.gradlebuild 文件。
dependencies {
implementation 'org.springframework.ai:spring-ai-pdf-document-reader'
}例
@Component
public class MyPagePdfDocumentReader {
List<Document> getDocsFromPdf() {
PagePdfDocumentReader pdfReader = new PagePdfDocumentReader("classpath:/sample1.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
return pdfReader.read();
}
}PDF 段落
这ParagraphPdfDocumentReader使用 PDF 目录(例如 TOC)信息将输入 PDF 拆分为文本段落并输出单个Document每段。
注意:并非所有 PDF 文档都包含 PDF 目录。
依赖
使用 Maven 或 Gradle 将依赖项添加到您的项目中。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>或发送到您的 Gradlebuild.gradlebuild 文件。
dependencies {
implementation 'org.springframework.ai:spring-ai-pdf-document-reader'
}例
@Component
public class MyPagePdfDocumentReader {
List<Document> getDocsFromPdfWithCatalog() {
ParagraphPdfDocumentReader pdfReader = new ParagraphPdfDocumentReader("classpath:/sample1.pdf",
PdfDocumentReaderConfig.builder()
.withPageTopMargin(0)
.withPageExtractedTextFormatter(ExtractedTextFormatter.builder()
.withNumberOfTopTextLinesToDelete(0)
.build())
.withPagesPerDocument(1)
.build());
return pdfReader.read();
}
}蒂卡 (DOCX, PPTX, HTML...
这TikaDocumentReader使用 Apache Tika 从各种文档格式(如 PDF、DOC/DOCX、PPT/PPTX 和 HTML)中提取文本。有关受支持格式的完整列表,请参阅 Tika 文档。
依赖
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>或发送到您的 Gradlebuild.gradlebuild 文件。
dependencies {
implementation 'org.springframework.ai:spring-ai-tika-document-reader'
}例
@Component
class MyTikaDocumentReader {
private final Resource resource;
MyTikaDocumentReader(@Value("classpath:/word-sample.docx")
Resource resource) {
this.resource = resource;
}
List<Document> loadText() {
TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(this.resource);
return tikaDocumentReader.read();
}
}变形金刚
TokenTextSplitter
这TokenTextSplitter是TextSplitter它使用 CL100K_BASE 编码根据令牌计数将文本拆分为块。
用法
@Component
class MyTokenTextSplitter {
public List<Document> splitDocuments(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter();
return splitter.apply(documents);
}
public List<Document> splitCustomized(List<Document> documents) {
TokenTextSplitter splitter = new TokenTextSplitter(1000, 400, 10, 5000, true);
return splitter.apply(documents);
}
}构造函数选项
这TokenTextSplitter提供两个构造函数选项:
-
TokenTextSplitter():使用默认设置创建拆分器。 -
TokenTextSplitter(int defaultChunkSize, int minChunkSizeChars, int minChunkLengthToEmbed, int maxNumChunks, boolean keepSeparator)
参数
-
defaultChunkSize:每个文本块的目标大小(以 tokens 为单位)(默认值:800)。 -
minChunkSizeChars:每个文本块的最小大小(以字符为单位)(默认值:350)。 -
minChunkLengthToEmbed:要包含的 chunk 的最小长度(默认值:5)。 -
maxNumChunks:从文本生成的最大块数(默认值:10000)。 -
keepSeparator:是否在块中保留分隔符(如换行符)(默认:true)。
行为
这TokenTextSplitter按如下方式处理文本内容:
-
它使用 CL100K_BASE 编码将输入文本编码为标记。
-
它根据
defaultChunkSize. -
对于每个块:
-
它将块解码回文本。
-
它尝试在
minChunkSizeChars. -
如果找到断点,它会在该点截断块。
-
它会修剪块,并根据
keepSeparator设置。 -
如果生成的块长度大于
minChunkLengthToEmbed,则会将其添加到输出中。
-
-
此过程将一直持续,直到处理完所有令牌或
maxNumChunks到达。 -
如果文本长度超过
minChunkLengthToEmbed.
例
Document doc1 = new Document("This is a long piece of text that needs to be split into smaller chunks for processing.",
Map.of("source", "example.txt"));
Document doc2 = new Document("Another document with content that will be split based on token count.",
Map.of("source", "example2.txt"));
TokenTextSplitter splitter = new TokenTextSplitter();
List<Document> splitDocuments = this.splitter.apply(List.of(this.doc1, this.doc2));
for (Document doc : splitDocuments) {
System.out.println("Chunk: " + doc.getContent());
System.out.println("Metadata: " + doc.getMetadata());
}关键字元数据扩充器
这KeywordMetadataEnricher是一个DocumentTransformer它使用生成式 AI 模型从文档内容中提取关键字并将其添加为元数据。
用法
@Component
class MyKeywordEnricher {
private final ChatModel chatModel;
MyKeywordEnricher(ChatModel chatModel) {
this.chatModel = chatModel;
}
List<Document> enrichDocuments(List<Document> documents) {
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(this.chatModel, 5);
return enricher.apply(documents);
}
}构造 函数
这KeywordMetadataEnricherconstructor 接受两个参数:
-
ChatModel chatModel:用于生成关键字的 AI 模型。 -
int keywordCount:要为每个文档提取的关键字数。
行为
这KeywordMetadataEnricher按如下方式处理文档:
-
对于每个输入文档,它将使用文档的内容创建一个提示。
-
它会将此提示发送到提供的
ChatModel生成关键字。 -
生成的关键字将添加到文档元数据的键 “excerpt_keywords” 下。
-
将返回扩充的文档。
定制
可以通过修改KEYWORDS_TEMPLATEconstant 的 Expression 中。默认模板为:
\{context_str}. Give %s unique keywords for this document. Format as comma separated. Keywords:哪里{context_str}替换为文档内容,并且%s替换为指定的关键字 count。
例
ChatModel chatModel = // initialize your chat model
KeywordMetadataEnricher enricher = new KeywordMetadataEnricher(chatModel, 5);
Document doc = new Document("This is a document about artificial intelligence and its applications in modern technology.");
List<Document> enrichedDocs = enricher.apply(List.of(this.doc));
Document enrichedDoc = this.enrichedDocs.get(0);
String keywords = (String) this.enrichedDoc.getMetadata().get("excerpt_keywords");
System.out.println("Extracted keywords: " + keywords);摘要元数据Enricher
这SummaryMetadataEnricher是一个DocumentTransformer使用生成式 AI 模型为文档创建摘要并将其添加为元数据。它可以为当前文档以及相邻文档(上一个和下一个)生成摘要。
用法
@Configuration
class EnricherConfig {
@Bean
public SummaryMetadataEnricher summaryMetadata(OpenAiChatModel aiClient) {
return new SummaryMetadataEnricher(aiClient,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT));
}
}
@Component
class MySummaryEnricher {
private final SummaryMetadataEnricher enricher;
MySummaryEnricher(SummaryMetadataEnricher enricher) {
this.enricher = enricher;
}
List<Document> enrichDocuments(List<Document> documents) {
return this.enricher.apply(documents);
}
}构造 函数
这SummaryMetadataEnricher提供两个构造函数:
-
SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes) -
SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes, String summaryTemplate, MetadataMode metadataMode)
参数
-
chatModel:用于生成摘要的 AI 模型。 -
summaryTypes:一个SummaryType枚举值,指示要生成的摘要 (PREVIOUS、CURRENT、NEXT)。 -
summaryTemplate:用于生成摘要的自定义模板(可选)。 -
metadataMode:指定在生成摘要时如何处理文档元数据(可选)。
行为
这SummaryMetadataEnricher按如下方式处理文档:
-
对于每个输入文档,它将使用文档的内容和指定的摘要模板创建一个提示。
-
它会将此提示发送到提供的
ChatModel以生成摘要。 -
根据指定的
summaryTypes,它会将以下元数据添加到每个文档中:-
section_summary:当前文档的摘要。 -
prev_section_summary:上一个文档的摘要(如果可用且已请求)。 -
next_section_summary:下一个文档的摘要(如果可用且已请求)。
-
-
将返回扩充的文档。
定制
可以通过提供自定义summaryTemplate.默认模板为:
"""
Here is the content of the section:
{context_str}
Summarize the key topics and entities of the section.
Summary:
"""例
ChatModel chatModel = // initialize your chat model
SummaryMetadataEnricher enricher = new SummaryMetadataEnricher(chatModel,
List.of(SummaryType.PREVIOUS, SummaryType.CURRENT, SummaryType.NEXT));
Document doc1 = new Document("Content of document 1");
Document doc2 = new Document("Content of document 2");
List<Document> enrichedDocs = enricher.apply(List.of(this.doc1, this.doc2));
// Check the metadata of the enriched documents
for (Document doc : enrichedDocs) {
System.out.println("Current summary: " + doc.getMetadata().get("section_summary"));
System.out.println("Previous summary: " + doc.getMetadata().get("prev_section_summary"));
System.out.println("Next summary: " + doc.getMetadata().get("next_section_summary"));
}提供的示例演示了预期的行为:
-
对于包含两个文档的列表,两个文档都会收到一个
section_summary. -
第一个文档接收
next_section_summary但是没有prev_section_summary. -
第二个文档接收
prev_section_summary但是没有next_section_summary. -
这
section_summary与prev_section_summary的 2 个文件。 -
这
next_section_summary与section_summary的 2 个文件。
作家
文件
这FileDocumentWriter是一个DocumentWriter实现写入Document对象添加到文件中。
用法
@Component
class MyDocumentWriter {
public void writeDocuments(List<Document> documents) {
FileDocumentWriter writer = new FileDocumentWriter("output.txt", true, MetadataMode.ALL, false);
writer.accept(documents);
}
}构造 函数
这FileDocumentWriter提供三个构造函数:
-
FileDocumentWriter(String fileName) -
FileDocumentWriter(String fileName, boolean withDocumentMarkers) -
FileDocumentWriter(String fileName, boolean withDocumentMarkers, MetadataMode metadataMode, boolean append)
参数
-
fileName:要将文档写入到的文件的名称。 -
withDocumentMarkers:是否在输出中包含文档标记(默认值:false)。 -
metadataMode:指定要写入文件的文档内容(默认值:MetadataMode.NONE)。 -
append:如果为 true,则数据将写入文件末尾而不是开头(默认值:false)。
行为
这FileDocumentWriter按如下方式处理文档:
-
它将打开指定文件名的 FileWriter。
-
对于输入列表中的每个文档:
-
如果
withDocumentMarkers为 true,则它会写入一个包含文档索引和页码的文档标记。 -
它根据指定的
metadataMode.
-
-
写入所有文档后,文件将关闭。
文档标记
什么时候withDocumentMarkers设置为 true,则 Writer 将按以下格式包含每个文档的标记:
### Doc: [index], pages:[start_page_number,end_page_number]矢量存储
提供与各种矢量存储的集成。 有关完整列表,请参阅 Vector DB 文档。