|
此版本仍在开发中,尚未被视为稳定版本。最新的快照版本请使用 Spring AI 1.0.0-SNAPSHOT! |
Ollama 聊天
使用 Ollama,您可以在本地运行各种大型语言模型 (LLM) 并从中生成文本。
Spring AI 通过 API 支持 Ollama 聊天完成功能。OllamaChatModel
| Ollama 还提供与 OpenAI API 兼容的端点。 OpenAI API 兼容性部分介绍了如何使用 Spring AI OpenAI 连接到 Ollama 服务器。 |
先决条件
您首先需要访问 Ollama 实例。有几个选项,包括:
-
通过 Kubernetes 服务绑定绑定到 Ollama 实例。
您可以从 Ollama 模型库中提取要在应用程序中使用的模型:
ollama pull <model-name>您还可以提取数千个免费的 GGUF 紧贴脸模型中的任何一个:
ollama pull hf.co/<username>/<model-repository>或者,您可以启用选项以自动下载任何需要的模型:Auto-pull Models (自动拉取模型)。
自动配置
Spring AI 为 Ollama 聊天集成提供了 Spring Boot 自动配置。
要启用它,请将以下依赖项添加到项目的 Maven 或 Gradle 构建文件中:pom.xmlbuild.gradle
-
Maven
-
Gradle
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>dependencies {
implementation 'org.springframework.ai:spring-ai-ollama-spring-boot-starter'
}| 请参阅 Dependency Management 部分,将 Spring AI BOM 添加到您的构建文件中。 |
基本属性
prefix 是用于配置与 Ollama 的连接的属性前缀。spring.ai.ollama
财产 |
描述 |
违约 |
spring.ai.ollama.base-url |
运行 Ollama API 服务器的基 URL。 |
以下是用于初始化 Ollama 集成和自动拉取模型的属性。
财产 |
描述 |
违约 |
spring.ai.ollama.init.pull-model-strategy |
是否在启动时拉取模型以及如何拉取模型。 |
|
spring.ai.ollama.init.timeout |
等待拉取模型的时间。 |
|
spring.ai.ollama.init.max重试 |
模型拉取操作的最大重试次数。 |
|
spring.ai.ollama.init.chat.include |
在初始化任务中包含此类型的模型。 |
|
spring.ai.ollama.init.chat.additional-models |
除了通过 default properties 配置的模型之外,还需要初始化其他模型。 |
|
聊天属性
prefix 是配置 Ollama 聊天模型的属性 prefix。
它包括 Ollama 请求(高级)参数,例如 、 和 Ollama 模型属性。spring.ai.ollama.chat.optionsmodelkeep-aliveformatoptions
以下是 Ollama 聊天模型的高级请求参数:
财产 |
描述 |
违约 |
spring.ai.ollama.chat.enabled |
启用 Ollama 聊天模型。 |
真 |
spring.ai.ollama.chat.options.model |
要使用的受支持模型的名称。 |
米斯特拉尔 |
spring.ai.ollama.chat.options.format |
返回响应的格式。目前,唯一接受的值是 |
- |
spring.ai.ollama.chat.options.keep_alive |
控制模型在请求后加载到内存中的时间 |
5 分钟 |
其余属性基于 Ollama Valid Parameters and Values 和 Ollama Types。默认值基于 Ollama Types Defaults。options
财产 |
描述 |
违约 |
spring.ai.ollama.chat.options.numa |
是否使用 NUMA。 |
假 |
spring.ai.ollama.chat.options.num-ctx |
设置用于生成下一个标记的上下文窗口的大小。 |
2048 |
spring.ai.ollama.chat.options.num-batch |
提示处理最大批量大小。 |
512 |
spring.ai.ollama.chat.options.num-gpu |
要发送到 GPU 的层数。在 macOS 上,默认为 1 表示启用 Metal 支持,默认为 0 表示禁用。此处的 1 表示应动态设置 NumGPU |
-1 |
spring.ai.ollama.chat.options.main-gpu |
使用多个 GPU 时,此选项控制将哪个 GPU 用于小张量,对于不值得在所有 GPU 之间拆分计算的开销。有问题的 GPU 将使用稍多的 VRAM 来存储暂存缓冲区以获得临时结果。 |
0 |
spring.ai.ollama.chat.options.low-vram |
- |
假 |
spring.ai.ollama.chat.options.f16-kv |
- |
真 |
spring.ai.ollama.chat.options.logits-all |
返回所有令牌的 logit,而不仅仅是最后一个令牌。要使 completions 返回 logprobs,这必须为 true。 |
- |
spring.ai.ollama.chat.options.vocab-only |
仅加载词汇表,而不加载权重。 |
- |
spring.ai.ollama.chat.options.use-mmap |
默认情况下,模型会映射到内存中,这允许系统根据需要仅加载模型的必要部分。但是,如果模型大于 RAM 总量,或者系统的可用内存不足,则使用 mmap 可能会增加分页的风险,从而对性能产生负面影响。禁用 mmap 会导致加载时间变慢,但如果您不使用 mlock,则可能会减少分页。请注意,如果模型大于 RAM 总量,则关闭 mmap 将完全阻止模型加载。 |
零 |
spring.ai.ollama.chat.options.use-mlock |
将模型锁定在内存中,防止在内存映射时将其换出。这可以提高性能,但会牺牲内存映射的一些优势,因为它需要更多的 RAM 来运行,并且可能会在模型加载到 RAM 时减慢加载时间。 |
假 |
spring.ai.ollama.chat.options.num-thread |
设置计算期间要使用的线程数。默认情况下,Ollama 将检测此参数以获得最佳性能。建议将此值设置为系统具有的物理 CPU 内核数(而不是内核的逻辑数)。0 = 让运行时决定 |
0 |
spring.ai.ollama.chat.options.num-keep |
- |
4 |
spring.ai.ollama.chat.options.seed |
设置用于生成的随机数种子。将此设置为特定数字将使模型为同一提示生成相同的文本。 |
-1 |
spring.ai.ollama.chat.options.num-predict |
生成文本时要预测的最大令牌数。(-1 = 无限生成,-2 = 填充上下文) |
-1 |
spring.ai.ollama.chat.options.top-k |
降低产生无意义的可能性。较高的值(例如 100)将给出更多样化的答案,而较低的值(例如 10)将更保守。 |
40 |
spring.ai.ollama.chat.options.top-p |
与 top-k 一起使用。较高的值(例如 0.95)将导致文本更加多样化,而较低的值(例如 0.5)将生成更集中和保守的文本。 |
0.9 |
spring.ai.ollama.chat.options.tfs-z |
无尾采样用于减少输出中可能性较小的标记的影响。较高的值(例如 2.0)将减少更多影响,而值 1.0 将禁用此设置。 |
1.0 |
spring.ai.ollama.chat.options.typical-p |
- |
1.0 |
spring.ai.ollama.chat.options.repeat-last-n |
设置模型回溯多长时间以防止重复。(默认值:64,0 = 禁用,-1 = num_ctx) |
64 |
spring.ai.ollama.chat.options.temperature |
模型的温度。提高温度会使模型更有创意地回答。 |
0.8 |
spring.ai.ollama.chat.options.repeat-penalty |
设置对重复项的惩罚强度。较高的值(例如 1.5)将更强烈地惩罚重复,而较低的值(例如 0.9)将更宽松。 |
1.1 |
spring.ai.ollama.chat.options.presence-penalty |
- |
0.0 |
spring.ai.ollama.chat.options.frequency-penalty |
- |
0.0 |
spring.ai.ollama.chat.options.mirostat |
启用 Mirostat 采样以控制困惑度。(默认值:0、0 = 禁用、1 = Mirostat、2 = Mirostat 2.0) |
0 |
spring.ai.ollama.chat.options.mirostat-tau |
控制输出的连贯性和多样性之间的平衡。较低的值将导致文本更集中、更连贯。 |
5.0 |
spring.ai.ollama.chat.options.mirostat-eta |
影响算法响应生成文本的反馈的速度。较低的学习率将导致较慢的调整,而较高的学习率将使算法的响应速度更快。 |
0.1 |
spring.ai.ollama.chat.options.penalize-newline |
- |
真 |
spring.ai.ollama.chat.options.stop |
设置要使用的停止序列。遇到此模式时,LLM 将停止生成文本并返回。通过在模型文件中指定多个单独的停止参数,可以设置多个停止模式。 |
- |
spring.ai.ollama.chat.options.functions |
函数列表,由其名称标识,用于在单个提示请求中启用函数调用。具有这些名称的函数必须存在于 functionCallbacks 注册表中。 |
- |
spring.ai.ollama.chat.options.proxy-tool-calls |
如果为true,则 Spring AI 将不会在内部处理函数调用,而是将它们代理给客户端。然后,客户端负责处理函数调用,将它们分派给适当的函数,并返回结果。如果为 false (默认值),则 Spring AI 将在内部处理函数调用。仅适用于支持函数调用的聊天模型 |
假 |
通过向调用添加特定于请求的 Runtime Options,可以在运行时覆盖所有前缀为 的属性。spring.ai.ollama.chat.optionsPrompt |
运行时选项
OllamaOptions.java 类提供模型配置,例如要使用的模型、温度等。
启动时,可以使用 constructor 或 properties 配置默认选项。OllamaChatModel(api, options)spring.ai.ollama.chat.options.*
在运行时,您可以通过向调用添加新的特定于请求的选项来覆盖默认选项。
例如,要覆盖特定请求的默认型号和温度:Prompt
ChatResponse response = chatModel.call(
new Prompt(
"Generate the names of 5 famous pirates.",
OllamaOptions.builder()
.withModel(OllamaModel.LLAMA3_1)
.withTemperature(0.4)
.build()
));| 除了特定于模型的 OllamaOptions 之外,您还可以使用通过 ChatOptionsBuilder#builder() 创建的可移植 ChatOptions 实例。 |
自动拉取模型
Spring AI Ollama 可以在模型在 Ollama 实例中不可用时自动拉取模型。 此功能对于开发和测试以及将应用程序部署到新环境特别有用。
| 您还可以按名称提取数千个免费的 GGUF 紧贴面部模型中的任何一个。 |
拉取模型有三种策略:
-
always(定义于 ):始终拉取模型,即使它已经可用。有助于确保您使用的是最新版本的模型。PullModelStrategy.ALWAYS -
when_missing(定义于 ):仅在模型尚不可用时拉取模型。这可能会导致使用旧版本的模型。PullModelStrategy.WHEN_MISSING -
never(定义于 ):从不自动拉取模型。PullModelStrategy.NEVER
| 由于下载模型时可能会延迟,因此不建议在生产环境中使用自动拉取。相反,请考虑提前评估和预下载必要的模型。 |
通过配置属性和默认选项定义的所有模型都可以在启动时自动拉取。 您可以使用配置属性配置拉取策略、超时和最大重试次数:
spring:
ai:
ollama:
init:
pull-model-strategy: always
timeout: 60s
max-retries: 1| 在 Ollama 中提供所有指定模型之前,应用程序不会完成其初始化。根据模型大小和 Internet 连接速度,这可能会显著减慢应用程序的启动时间。 |
您可以在启动时初始化其他模型,这对于在运行时动态使用的模型非常有用:
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
additional-models:
- llama3.2
- qwen2.5如果只想将拉取策略应用于特定类型的模型,则可以从初始化任务中排除聊天模型:
spring:
ai:
ollama:
init:
pull-model-strategy: always
chat:
include: false此配置会将拉取策略应用于除聊天模型之外的所有模型。
函数调用
您可以使用 注册自定义 Java 函数,并让 Ollama 模型智能地选择输出包含参数的 JSON 对象,以调用一个或多个已注册的函数。
这是一种将 LLM 功能与外部工具和 API 连接起来的强大技术。
阅读有关 Ollama 函数调用的更多信息。OllamaChatModel
| 您需要 Ollama 0.2.8 或更高版本才能使用函数式调用功能。 |
| 目前 Ollama API (0.3.8) 不支持流式模式下的函数调用。 |
模 态
多模态是指模型同时理解和处理来自各种来源的信息(包括文本、图像、音频和其他数据格式)的能力。
Ollama 中支持多模态的一些模型是 LLaVa 和 baklavava(请参阅完整列表)。 有关更多详细信息,请参阅 LLaVA:大型语言和视觉助手。
Ollama 消息 API 提供了一个 “images” 参数,用于将 base64 编码的图像列表与消息合并。
Spring AI 的 Message 接口通过引入 Media 类型来促进多模态 AI 模型。
此类型包含有关消息中媒体附件的数据和详细信息,将 Spring 和 a 用于原始媒体数据。org.springframework.util.MimeTypeorg.springframework.core.io.Resource
下面是一个摘自 OllamaChatModelMultimodalIT.java 的简单代码示例,说明了用户文本与图像的融合。
var imageResource = new ClassPathResource("/multimodal.test.png");
var userMessage = new UserMessage("Explain what do you see on this picture?",
new Media(MimeTypeUtils.IMAGE_PNG, this.imageResource));
ChatResponse response = chatModel.call(new Prompt(this.userMessage,
OllamaOptions.builder().withModel(OllamaModel.LLAVA)).build());该示例显示了一个将图像作为输入的模型:multimodal.test.png

以及文本消息 “Explain what do you see on this picture?”,并生成如下响应:
The image shows a small metal basket filled with ripe bananas and red apples. The basket is placed on a surface, which appears to be a table or countertop, as there's a hint of what seems like a kitchen cabinet or drawer in the background. There's also a gold-colored ring visible behind the basket, which could indicate that this photo was taken in an area with metallic decorations or fixtures. The overall setting suggests a home environment where fruits are being displayed, possibly for convenience or aesthetic purposes.
OpenAI API 兼容性
Ollama 与 OpenAI API 兼容,您可以使用 Spring AI OpenAI 客户端与 Ollama 交谈并使用工具。
为此,您需要将 OpenAI 基本 URL 配置为您的 Ollama 实例:并选择提供的 Ollama 模型之一:。spring.ai.openai.chat.base-url=http://localhost:11434spring.ai.openai.chat.options.model=mistral
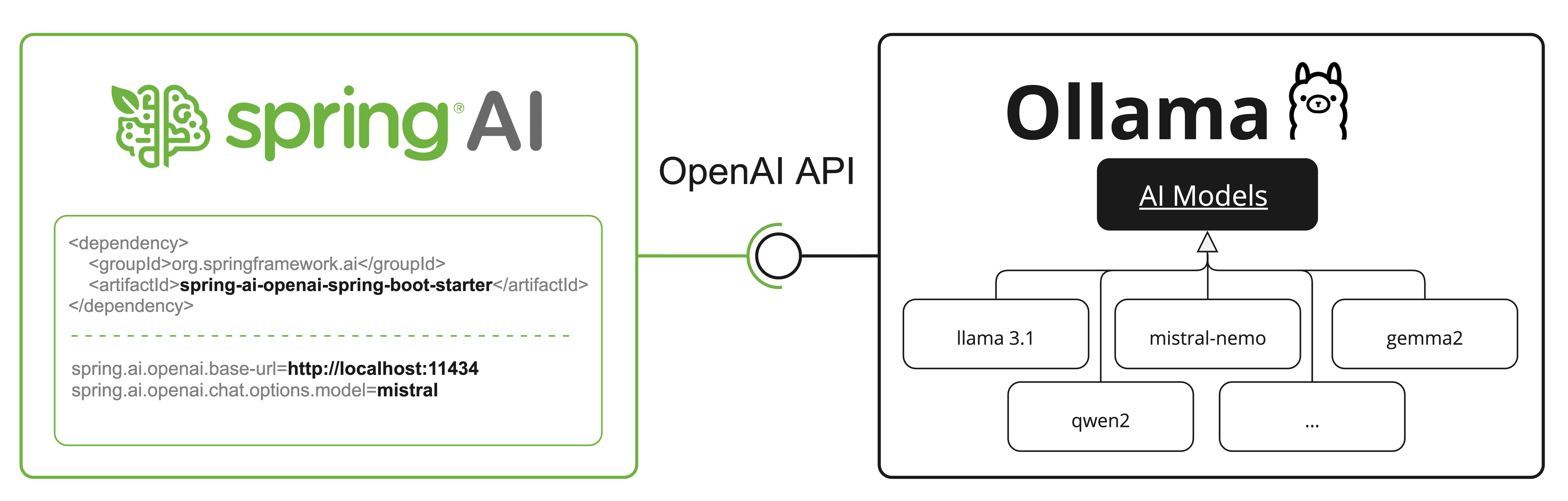
查看 OllamaWithOpenAiChatModelIT.java 测试,了解在 Spring AI OpenAI 上使用 Ollama 的示例。
Samples控制器
创建一个新的 Spring Boot 项目,并将 添加到您的 pom(或 gradle)依赖项中。spring-ai-ollama-spring-boot-starter
在目录下添加一个文件,以启用和配置 Ollama 聊天模型:application.yamlsrc/main/resources
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
options:
model: mistral
temperature: 0.7将 替换为您的 Ollama 服务器 URL。base-url |
这将创建一个可以注入到类中的实现。
下面是一个使用 chat 模型进行文本生成的简单类的示例。OllamaChatModel@RestController
@RestController
public class ChatController {
private final OllamaChatModel chatModel;
@Autowired
public ChatController(OllamaChatModel chatModel) {
this.chatModel = chatModel;
}
@GetMapping("/ai/generate")
public Map<String,String> generate(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
return Map.of("generation", this.chatModel.call(message));
}
@GetMapping("/ai/generateStream")
public Flux<ChatResponse> generateStream(@RequestParam(value = "message", defaultValue = "Tell me a joke") String message) {
Prompt prompt = new Prompt(new UserMessage(message));
return this.chatModel.stream(prompt);
}
}手动配置
如果您不想使用 Spring Boot 自动配置,则可以在应用程序中手动配置。
OllamaChatModel 实现 and,并使用低级 OllamaApi Client 连接到 Ollama 服务。OllamaChatModelChatModelStreamingChatModel
要使用它,请将依赖项添加到项目的 Maven 或 Gradle 构建文件中:spring-ai-ollamapom.xmlbuild.gradle
-
Maven
-
Gradle
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama</artifactId>
</dependency>dependencies {
implementation 'org.springframework.ai:spring-ai-ollama'
}| 请参阅 Dependency Management 部分,将 Spring AI BOM 添加到您的构建文件中。 |
依赖项还提供对 .
有关更多信息,请参阅 Ollama 嵌入模型 部分。spring-ai-ollamaOllamaEmbeddingModelOllamaEmbeddingModel |
接下来,创建一个实例并使用它来发送文本生成请求:OllamaChatModel
var ollamaApi = new OllamaApi();
var chatModel = new OllamaChatModel(this.ollamaApi,
OllamaOptions.create()
.withModel(OllamaOptions.DEFAULT_MODEL)
.withTemperature(0.9));
ChatResponse response = this.chatModel.call(
new Prompt("Generate the names of 5 famous pirates."));
// Or with streaming responses
Flux<ChatResponse> response = this.chatModel.stream(
new Prompt("Generate the names of 5 famous pirates."));这提供了所有聊天请求的配置信息。OllamaOptions
低级 OllamaApi 客户端
OllamaApi 为 Ollama Chat Completion API Ollama Chat Completion API 提供了一个轻量级 Java 客户端。
下面的类图说明了聊天界面和构建基块:OllamaApi
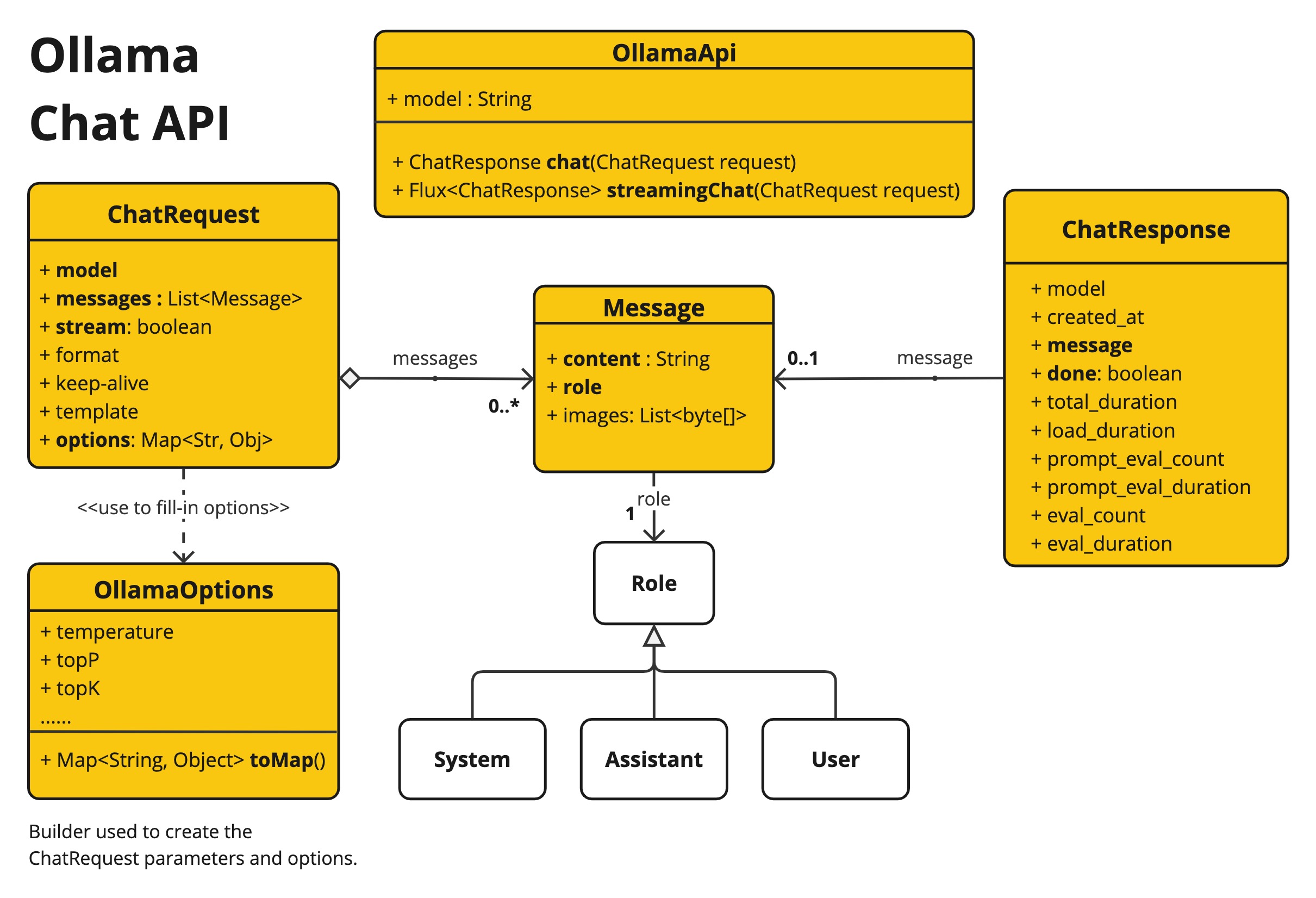
这是一个低级 API,不建议直接使用。请改用 。OllamaApiOllamaChatModel |
下面是一个简单的代码片段,演示如何以编程方式使用 API:
OllamaApi ollamaApi = new OllamaApi("YOUR_HOST:YOUR_PORT");
// Sync request
var request = ChatRequest.builder("orca-mini")
.withStream(false) // not streaming
.withMessages(List.of(
Message.builder(Role.SYSTEM)
.withContent("You are a geography teacher. You are talking to a student.")
.build(),
Message.builder(Role.USER)
.withContent("What is the capital of Bulgaria and what is the size? "
+ "What is the national anthem?")
.build()))
.withOptions(OllamaOptions.create().withTemperature(0.9))
.build();
ChatResponse response = this.ollamaApi.chat(this.request);
// Streaming request
var request2 = ChatRequest.builder("orca-mini")
.withStream(true) // streaming
.withMessages(List.of(Message.builder(Role.USER)
.withContent("What is the capital of Bulgaria and what is the size? " + "What is the national anthem?")
.build()))
.withOptions(OllamaOptions.create().withTemperature(0.9).toMap())
.build();
Flux<ChatResponse> streamingResponse = this.ollamaApi.streamingChat(this.request2);