Scaling and Parallel Processing
Scaling and Parallel Processing
Many batch processing problems can be solved with single-threaded, single-process jobs, so it is always a good idea to properly check if that meets your needs before thinking about more complex implementations. Measure the performance of a realistic job and see if the simplest implementation meets your needs first. You can read and write a file of several hundred megabytes in well under a minute, even with standard hardware.
When you are ready to start implementing a job with some parallel processing, Spring Batch offers a range of options, which are described in this chapter, although some features are covered elsewhere. At a high level, there are two modes of parallel processing:
-
Single-process, multi-threaded
-
Multi-process
These break down into categories as well, as follows:
-
Multi-threaded Step (single-process)
-
Parallel Steps (single-process)
-
Remote Chunking of Step (multi-process)
-
Partitioning a Step (single or multi-process)
First, we review the single-process options. Then we review the multi-process options.
Multi-threaded Step
The simplest way to start parallel processing is to add a TaskExecutor to your Step
configuration.
For example, you might add an attribute TO the tasklet, as follows:
<step id="loading">
<tasklet task-executor="taskExecutor">...</tasklet>
</step>When using Java configuration, you can add a TaskExecutor to the step,
as the following example shows:
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
@Bean
public Step sampleStep(TaskExecutor taskExecutor, JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("sampleStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.build();
}
In this example, the taskExecutor is a reference to another bean definition that
implements the TaskExecutor interface.
TaskExecutor
is a standard Spring interface, so consult the Spring User Guide for details of available
implementations. The simplest multi-threaded TaskExecutor is a
SimpleAsyncTaskExecutor.
The result of the preceding configuration is that the Step executes by reading, processing,
and writing each chunk of items (each commit interval) in a separate thread of execution.
Note that this means there is no fixed order for the items to be processed, and a chunk
might contain items that are non-consecutive compared to the single-threaded case. In
addition to any limits placed by the task executor (such as whether it is backed by a
thread pool), the tasklet configuration has a throttle limit (default: 4).
You may need to increase this limit to ensure that a thread pool is fully used.
For example, you might increase the throttle-limit, as follows:
<step id="loading"> <tasklet
task-executor="taskExecutor"
throttle-limit="20">...</tasklet>
</step>When using Java configuration, the builders provide access to the throttle limit, as follows:
@Bean
public Step sampleStep(TaskExecutor taskExecutor, JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("sampleStep", jobRepository)
.<String, String>chunk(10, transactionManager)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.throttleLimit(20)
.build();
}
Note also that there may be limits placed on concurrency by any pooled resources used in
your step, such as a DataSource. Be sure to make the pool in those resources at least
as large as the desired number of concurrent threads in the step.
|
Throttle limit deprecation
As of v5.0, the throttle limit is deprecated with no replacement. If you want to replace the
current throttling mechanism in the default Java Configuration
|
There are some practical limitations of using multi-threaded Step implementations for
some common batch use cases. Many participants in a Step (such as readers and writers)
are stateful. If the state is not segregated by thread, those components are not
usable in a multi-threaded Step. In particular, most of the readers and
writers from Spring Batch are not designed for multi-threaded use. It is, however,
possible to work with stateless or thread safe readers and writers, and there is a sample
(called parallelJob) in the
Spring
Batch Samples that shows the use of a process indicator (see
Preventing State Persistence) to keep track
of items that have been processed in a database input table.
Spring Batch provides some implementations of ItemWriter and ItemReader. Usually,
they say in the Javadoc if they are thread safe or not or what you have to do to avoid
problems in a concurrent environment. If there is no information in the Javadoc, you can
check the implementation to see if there is any state. If a reader is not thread safe,
you can decorate it with the provided SynchronizedItemStreamReader or use it in your own
synchronizing delegator. You can synchronize the call to read(), and, as long as the
processing and writing is the most expensive part of the chunk, your step may still
complete much more quickly than it would in a single-threaded configuration.
Parallel Steps
As long as the application logic that needs to be parallelized can be split into distinct responsibilities and assigned to individual steps, it can be parallelized in a single process. Parallel Step execution is easy to configure and use.
For example, executing steps (step1,step2) in parallel with step3 is straightforward,
as follows:
<job id="job1">
<split id="split1" task-executor="taskExecutor" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>
<beans:bean id="taskExecutor" class="org.spr...SimpleAsyncTaskExecutor"/>When using Java configuration, executing steps (step1,step2) in parallel with step3
is straightforward, as follows:
@Bean
public Job job(JobRepository jobRepository) {
return new JobBuilder("job", jobRepository)
.start(splitFlow())
.next(step4())
.build() //builds FlowJobBuilder instance
.build(); //builds Job instance
}
@Bean
public Flow splitFlow() {
return new FlowBuilder<SimpleFlow>("splitFlow")
.split(taskExecutor())
.add(flow1(), flow2())
.build();
}
@Bean
public Flow flow1() {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1())
.next(step2())
.build();
}
@Bean
public Flow flow2() {
return new FlowBuilder<SimpleFlow>("flow2")
.start(step3())
.build();
}
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
The configurable task executor is used to specify which TaskExecutor
implementation should execute the individual flows. The default is
SyncTaskExecutor, but an asynchronous TaskExecutor is required to run the steps in
parallel. Note that the job ensures that every flow in the split completes before
aggregating the exit statuses and transitioning.
See the section on Split Flows for more detail.
Remote Chunking
In remote chunking, the Step processing is split across multiple processes,
communicating with each other through some middleware. The following image shows the
pattern:
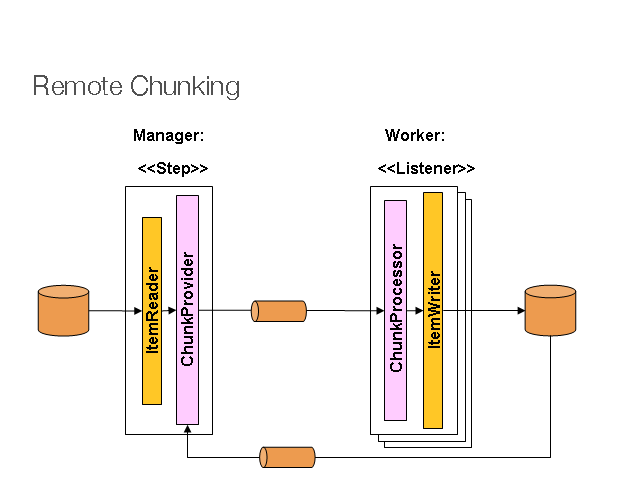
The manager component is a single process, and the workers are multiple remote processes. This pattern works best if the manager is not a bottleneck, so the processing must be more expensive than the reading of items (as is often the case in practice).
The manager is an implementation of a Spring Batch Step with the ItemWriter replaced
by a generic version that knows how to send chunks of items to the middleware as
messages. The workers are standard listeners for whatever middleware is being used (for
example, with JMS, they would be MesssageListener implementations), and their role is
to process the chunks of items by using a standard ItemWriter or ItemProcessor plus an
ItemWriter, through the ChunkProcessor interface. One of the advantages of using this
pattern is that the reader, processor, and writer components are off-the-shelf (the same
as would be used for a local execution of the step). The items are divided up dynamically,
and work is shared through the middleware, so that, if the listeners are all eager
consumers, load balancing is automatic.
The middleware has to be durable, with guaranteed delivery and a single consumer for each message. JMS is the obvious candidate, but other options (such as JavaSpaces) exist in the grid computing and shared memory product space.
See the section on Spring Batch Integration - Remote Chunking for more detail.
Partitioning
Spring Batch also provides an SPI for partitioning a Step execution and executing it
remotely. In this case, the remote participants are Step instances that could just as
easily have been configured and used for local processing. The following image shows the
pattern:
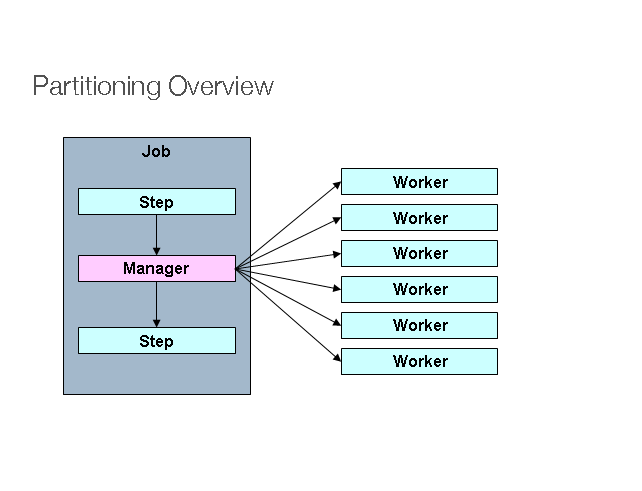
The Job runs on the left-hand side as a sequence of Step instances, and one of the
Step instances is labeled as a manager. The workers in this picture are all identical
instances of a Step, which could in fact take the place of the manager, resulting in the
same outcome for the Job. The workers are typically going to be remote services but
could also be local threads of execution. The messages sent by the manager to the workers
in this pattern do not need to be durable or have guaranteed delivery. Spring Batch
metadata in the JobRepository ensures that each worker is executed once and only once for
each Job execution.
The SPI in Spring Batch consists of a special implementation of Step (called the
PartitionStep) and two strategy interfaces that need to be implemented for the specific
environment. The strategy interfaces are PartitionHandler and StepExecutionSplitter,
and the following sequence diagram shows their role:
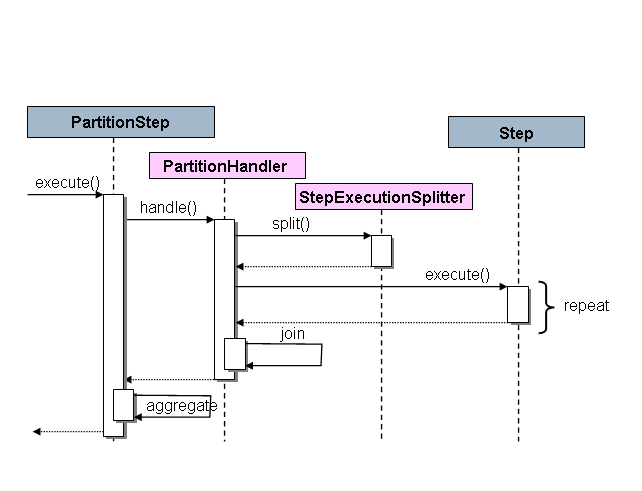
The Step on the right in this case is the “remote” worker, so, potentially, there are
many objects and or processes playing this role, and the PartitionStep is shown driving
the execution.
The following example shows the PartitionStep configuration when using XML
configuration:
<step id="step1.manager">
<partition step="step1" partitioner="partitioner">
<handler grid-size="10" task-executor="taskExecutor"/>
</partition>
</step>Similar to the multi-threaded step’s throttle-limit attribute, the grid-size
attribute prevents the task executor from being saturated with requests from a single
step.
The following example shows the PartitionStep configuration when using Java
configuration:
@Bean
public Step step1Manager(JobRepository jobRepository) {
return new StepBuilder("step1.manager", jobRepository)
.<String, String>partitioner("step1", partitioner())
.step(step1())
.gridSize(10)
.taskExecutor(taskExecutor())
.build();
}
Similar to the multi-threaded step’s throttleLimit method, the gridSize
method prevents the task executor from being saturated with requests from a single
step.
The unit test suite for
Spring
Batch Samples (see partition*Job.xml configuration) has a simple example that you can copy and extend.
Spring Batch creates step executions for the partition called step1:partition0 and so
on. Many people prefer to call the manager step step1:manager for consistency. You can
use an alias for the step (by specifying the name attribute instead of the id
attribute).
PartitionHandler
PartitionHandler is the component that knows about the fabric of the remoting or
grid environment. It is able to send StepExecution requests to the remote Step
instances, wrapped in some fabric-specific format, like a DTO. It does not have to know
how to split the input data or how to aggregate the result of multiple Step executions.
Generally speaking, it probably also does not need to know about resilience or failover,
since those are features of the fabric in many cases. In any case, Spring Batch always
provides restartability independent of the fabric. A failed Job can always be restarted,
and, in that case, only the failed Steps are re-executed.
The PartitionHandler interface can have specialized implementations for a variety of
fabric types, including simple RMI remoting, EJB remoting, custom web service, JMS, Java
Spaces, shared memory grids (such as Terracotta or Coherence), and grid execution fabrics
(such as GridGain). Spring Batch does not contain implementations for any proprietary grid
or remoting fabrics.
Spring Batch does, however, provide a useful implementation of PartitionHandler that
executes Step instances locally in separate threads of execution, using the
TaskExecutor strategy from Spring. The implementation is called
TaskExecutorPartitionHandler.
The TaskExecutorPartitionHandler is the default for a step configured with the XML
namespace shown previously. You can also configure it explicitly, as follows:
<step id="step1.manager">
<partition step="step1" handler="handler"/>
</step>
<bean class="org.spr...TaskExecutorPartitionHandler">
<property name="taskExecutor" ref="taskExecutor"/>
<property name="step" ref="step1" />
<property name="gridSize" value="10" />
</bean>You can explicitly configure the TaskExecutorPartitionHandler with Java configuration,
as follows:
@Bean
public Step step1Manager() {
return stepBuilderFactory.get("step1.manager")
.partitioner("step1", partitioner())
.partitionHandler(partitionHandler())
.build();
}
@Bean
public PartitionHandler partitionHandler() {
TaskExecutorPartitionHandler retVal = new TaskExecutorPartitionHandler();
retVal.setTaskExecutor(taskExecutor());
retVal.setStep(step1());
retVal.setGridSize(10);
return retVal;
}
The gridSize attribute determines the number of separate step executions to create, so
it can be matched to the size of the thread pool in the TaskExecutor. Alternatively, it
can be set to be larger than the number of threads available, which makes the blocks of
work smaller.
The TaskExecutorPartitionHandler is useful for IO-intensive Step instances, such as
copying large numbers of files or replicating filesystems into content management
systems. It can also be used for remote execution by providing a Step implementation
that is a proxy for a remote invocation (such as using Spring Remoting).
Partitioner
The Partitioner has a simpler responsibility: to generate execution contexts as input
parameters for new step executions only (no need to worry about restarts). It has a
single method, as the following interface definition shows:
public interface Partitioner {
Map<String, ExecutionContext> partition(int gridSize);
}
The return value from this method associates a unique name for each step execution (the
String) with input parameters in the form of an ExecutionContext. The names show up
later in the Batch metadata as the step name in the partitioned StepExecutions. The
ExecutionContext is just a bag of name-value pairs, so it might contain a range of
primary keys, line numbers, or the location of an input file. The remote Step then
normally binds to the context input by using #{…} placeholders (late binding in step
scope), as shown in the next section.
The names of the step executions (the keys in the Map returned by Partitioner) need
to be unique amongst the step executions of a Job but do not have any other specific
requirements. The easiest way to do this (and to make the names meaningful for users) is
to use a prefix+suffix naming convention, where the prefix is the name of the step that
is being executed (which itself is unique in the Job) and the suffix is just a
counter. There is a SimplePartitioner in the framework that uses this convention.
You can use an optional interface called PartitionNameProvider to provide the partition
names separately from the partitions themselves. If a Partitioner implements this
interface, only the names are queried on a restart. If partitioning is expensive,
this can be a useful optimization. The names provided by the PartitionNameProvider must
match those provided by the Partitioner.
Binding Input Data to Steps
It is very efficient for the steps that are executed by the PartitionHandler to have
identical configuration and for their input parameters to be bound at runtime from the
ExecutionContext. This is easy to do with the StepScope feature of Spring Batch
(covered in more detail in the section on Late Binding). For
example, if the Partitioner creates ExecutionContext instances with an attribute key
called fileName, pointing to a different file (or directory) for each step invocation,
the Partitioner output might resemble the content of the following table:
Step Execution Name (key) |
ExecutionContext (value) |
filecopy:partition0 |
fileName=/home/data/one |
filecopy:partition1 |
fileName=/home/data/two |
filecopy:partition2 |
fileName=/home/data/three |
Then the file name can be bound to a step by using late binding to the execution context.
The following example shows how to define late binding in XML:
<bean id="itemReader" scope="step"
class="org.spr...MultiResourceItemReader">
<property name="resources" value="#{stepExecutionContext[fileName]}/*"/>
</bean>The following example shows how to define late binding in Java:
@Bean
public MultiResourceItemReader itemReader(
@Value("#{stepExecutionContext['fileName']}/*") Resource [] resources) {
return new MultiResourceItemReaderBuilder<String>()
.delegate(fileReader())
.name("itemReader")
.resources(resources)
.build();
}