数据访问
1. 交易管理
全面的事务支持是使用 Spring 的最令人信服的理由之一 框架。Spring Framework 为事务提供了一致的抽象 管理带来以下好处:
以下各节描述了 Spring 框架的事务功能和 技术:
-
Spring 框架的事务支持的优势 model 描述了为什么你会使用 Spring 框架的事务抽象 而不是 EJB Container-Managed Transactions (CMT) 或选择在本地驱动 事务。
-
了解 Spring Framework 事务抽象概述了核心类,并描述了如何从各种来源配置和获取实例。
DataSource -
将资源与事务同步 描述 应用程序代码如何确保创建、重用和清理资源 适当地。
-
声明式事务管理描述了对 声明式事务管理。
-
程序化交易管理涵盖对 编程 (即显式编码) 事务管理。
-
事务绑定事件描述如何使用应用程序 事件。
1.1. Spring 框架的事务支持模型的优势
传统上,Java EE 开发人员有两种事务管理选择: 全局或本地事务,这两者都有严重的局限性。全球 接下来的两节将回顾本地事务管理,然后是 讨论 Spring 框架的事务管理支持如何解决 全局和本地事务模型的限制。
1.1.1. 全局事务
全局事务允许您使用多个事务资源,通常
关系数据库和消息队列。应用程序服务器管理全局
交易,这是一个繁琐的 API(部分原因是其
异常模型)。此外,JTA 通常需要从
JNDI,这意味着您还需要使用 JNDI 才能使用 JTA。用途
的全局事务限制了应用程序代码的任何潜在重用,就像 JTA 一样
通常仅在 Application Server 环境中可用。UserTransaction
以前,使用全局事务的首选方式是通过 EJB CMT (容器管理事务)。CMT 是一种声明式交易 管理(与编程事务管理不同)。EJB CMT 消除了与事务相关的 JNDI 查找的需要,尽管使用 EJB 本身就需要使用 JNDI。它消除了大部分但不是全部的编写需求 用于控制事务的 Java 代码。显着的缺点是 CMT 与 JTA 挂钩 以及应用程序服务器环境。此外,它仅在选择时可用 在 EJB 中实现业务逻辑(或至少在事务性 EJB 门面后面)。这 一般来说,EJB 的缺点是如此之大,以至于这不是一个有吸引力的提议。 尤其是在面对声明式事务管理的令人信服的替代方案时。
1.2. 理解 Spring Framework 事务抽象
Spring 事务抽象的关键是事务策略的概念。一个
事务策略由 ,具体而言,命令式的接口
事务管理和 Reactive 接口
事务管理。下面的清单显示了 API 的定义:TransactionManagerorg.springframework.transaction.PlatformTransactionManagerorg.springframework.transaction.ReactiveTransactionManagerPlatformTransactionManager
public interface PlatformTransactionManager extends TransactionManager {
TransactionStatus getTransaction(TransactionDefinition definition) throws TransactionException;
void commit(TransactionStatus status) throws TransactionException;
void rollback(TransactionStatus status) throws TransactionException;
}这主要是一个服务提供商接口 (SPI),尽管您可以从应用程序代码中以编程方式使用它。因为是一个接口,所以它可以很容易地被 mock 或 stub 化为
必要。它与查找策略(如 JNDI)无关。 实现的定义与任何其他对象(或 bean)一样
在 Spring Framework IoC 容器中。仅此一项优势就使 Spring Framework
transactions 是一个有价值的抽象,即使您使用 JTA 也是如此。您可以测试
事务性代码比直接使用 JTA 要容易得多。PlatformTransactionManagerPlatformTransactionManager
同样,为了与 Spring 的理念保持一致,可以抛出
(该
is,它会扩展类)。交易基础设施
失败几乎总是致命的。在应用程序代码实际上可以
从事务失败中恢复,应用程序开发人员仍然可以选择捕获
和 handle .突出的一点是开发人员不是被迫这样做的。TransactionExceptionPlatformTransactionManagerjava.lang.RuntimeExceptionTransactionException
该方法根据参数返回一个对象。返回的 this 可能表示
新交易,也可以表示现有交易(如果是匹配的交易)
存在于当前调用堆栈中。后一种情况的含义是,与
Java EE 事务上下文中,a 与
执行。getTransaction(..)TransactionStatusTransactionDefinitionTransactionStatusTransactionStatus
从 Spring Framework 5.2 开始, Spring 还为
使用反应式类型或 Kotlin 协程的响应式应用程序。以下内容
清单显示了由以下定义的事务策略:org.springframework.transaction.ReactiveTransactionManager
public interface ReactiveTransactionManager extends TransactionManager {
Mono<ReactiveTransaction> getReactiveTransaction(TransactionDefinition definition) throws TransactionException;
Mono<Void> commit(ReactiveTransaction status) throws TransactionException;
Mono<Void> rollback(ReactiveTransaction status) throws TransactionException;
}反应式事务管理器主要是一个服务提供者接口 (SPI),
尽管您可以从
应用程序代码。因为是一个接口,所以可以很容易地
根据需要被 mock 或 stubbed 进行。ReactiveTransactionManager
该接口指定:TransactionDefinition
-
传播:通常,事务范围内的所有代码都在 那笔交易。但是,如果 当事务上下文已存在时,将运行 transactional 方法。为 example,代码可以继续在现有事务中运行(常见情况),或者 可以暂停现有事务并创建新事务。Spring 提供 EJB CMT 中熟悉的所有事务传播选项。阅读 关于 Spring 中事务传播的语义,请参见事务传播。
-
隔离:此事务与其他事务的工作隔离的程度 交易。例如,此事务能否看到来自其他 交易?
-
Timeout:此事务在超时并自动回滚之前运行的时间 通过底层事务基础设施。
-
Read-only 状态:当您的代码读取但 不修改数据。只读事务在某些 的情况下,例如当您使用 Hibernate 时。
这些设置反映了标准的事务概念。如有必要,请参阅 参考资料 讨论事务隔离级别和其他核心事务概念。 理解这些概念对于使用 Spring Framework 或任何 事务管理解决方案。
该接口为事务代码提供了一种简单的方法:
控制事务执行并查询事务状态。概念应该是
熟悉,因为它们对所有事务 API 都是通用的。下面的清单显示了该接口:TransactionStatusTransactionStatus
public interface TransactionStatus extends TransactionExecution, SavepointManager, Flushable {
@Override
boolean isNewTransaction();
boolean hasSavepoint();
@Override
void setRollbackOnly();
@Override
boolean isRollbackOnly();
void flush();
@Override
boolean isCompleted();
}无论您在
Spring,定义正确的实现是绝对必要的。
通常通过依赖项注入来定义此实现。TransactionManager
TransactionManager实现通常需要了解
他们使用的 JDBC、JTA、Hibernate 等。以下示例显示了如何
定义本地实现(在本例中,使用 PLAIN
JDBC。PlatformTransactionManager
您可以通过创建类似于以下内容的 bean 来定义 JDBC:DataSource
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="${jdbc.driverClassName}" />
<property name="url" value="${jdbc.url}" />
<property name="username" value="${jdbc.username}" />
<property name="password" value="${jdbc.password}" />
</bean>然后,相关的 bean 定义具有对该定义的引用。它应类似于以下示例:PlatformTransactionManagerDataSource
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>如果在 Java EE 容器中使用 JTA,则使用 container 获取
通过 JNDI 与 Spring 的 .以下示例
显示了 JTA 和 JNDI 查找版本的外观:DataSourceJtaTransactionManager
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jee="http://www.springframework.org/schema/jee"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/jee
https://www.springframework.org/schema/jee/spring-jee.xsd">
<jee:jndi-lookup id="dataSource" jndi-name="jdbc/jpetstore"/>
<bean id="txManager" class="org.springframework.transaction.jta.JtaTransactionManager" />
<!-- other <bean/> definitions here -->
</beans>不需要了解(或任何其他
特定资源),因为它使用容器的全局事务管理
基础设施。JtaTransactionManagerDataSource
前面的 bean 定义使用标记
从命名空间。有关更多信息,请参阅 JEE 架构。dataSource<jndi-lookup/>jee |
| 如果您使用 JTA,则无论如何,您的事务管理器定义看起来都应该相同 您使用的数据访问技术,无论是 JDBC、Hibernate JPA 还是任何其他受支持的 科技。这是因为 JTA 事务是全局事务,而 可以登记任何事务性资源。 |
在所有 Spring 事务设置中,应用程序代码不需要更改。您可以更改 如何仅通过更改配置来管理事务,即使该更改意味着 从本地交易转向全球交易,反之亦然。
1.2.1. Hibernate 事务设置
您还可以轻松使用 Hibernate 本地事务,如以下示例所示。
在这种情况下,您需要定义一个 Hibernate ,您的
应用程序代码可用于获取 Hibernate 实例。LocalSessionFactoryBeanSession
Bean 定义类似于前面显示的本地 JDBC 示例
因此,以下示例中未显示 。DataSource
如果通过
JNDI 并由 Java EE 容器管理,则它应该是非事务性的,因为
Spring Framework(而不是 Java EE 容器)管理事务。DataSource |
在本例中,bean 的类型为 。在
与 需要对 的引用相同,需要对 的引用。以下内容
示例 declare 和 bean:txManagerHibernateTransactionManagerDataSourceTransactionManagerDataSourceHibernateTransactionManagerSessionFactorysessionFactorytxManager
<bean id="sessionFactory" class="org.springframework.orm.hibernate5.LocalSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="mappingResources">
<list>
<value>org/springframework/samples/petclinic/hibernate/petclinic.hbm.xml</value>
</list>
</property>
<property name="hibernateProperties">
<value>
hibernate.dialect=${hibernate.dialect}
</value>
</property>
</bean>
<bean id="txManager" class="org.springframework.orm.hibernate5.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory"/>
</bean>如果使用 Hibernate 和 Java EE 容器托管的 JTA 事务,则应使用
与前面的 JDBC JTA 示例相同,如下所示
示例显示。此外,建议通过 Hibernate 的 JTA
Transaction Coordinator 以及可能的 Connection Release Mode 配置:JtaTransactionManager
<bean id="sessionFactory" class="org.springframework.orm.hibernate5.LocalSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="mappingResources">
<list>
<value>org/springframework/samples/petclinic/hibernate/petclinic.hbm.xml</value>
</list>
</property>
<property name="hibernateProperties">
<value>
hibernate.dialect=${hibernate.dialect}
hibernate.transaction.coordinator_class=jta
hibernate.connection.handling_mode=DELAYED_ACQUISITION_AND_RELEASE_AFTER_STATEMENT
</value>
</property>
</bean>
<bean id="txManager" class="org.springframework.transaction.jta.JtaTransactionManager"/>或者,你可以将 the 传递给 your 以强制执行相同的默认值:JtaTransactionManagerLocalSessionFactoryBean
<bean id="sessionFactory" class="org.springframework.orm.hibernate5.LocalSessionFactoryBean">
<property name="dataSource" ref="dataSource"/>
<property name="mappingResources">
<list>
<value>org/springframework/samples/petclinic/hibernate/petclinic.hbm.xml</value>
</list>
</property>
<property name="hibernateProperties">
<value>
hibernate.dialect=${hibernate.dialect}
</value>
</property>
<property name="jtaTransactionManager" ref="txManager"/>
</bean>
<bean id="txManager" class="org.springframework.transaction.jta.JtaTransactionManager"/>1.3. 将资源与事务同步
如何创建不同的事务管理器以及它们如何链接到相关资源
需要同步到事务(例如同步到 JDBC 、 Hibernate 、
等等)现在应该很清楚了。本节介绍应用程序代码
(直接或间接,通过使用 JDBC、Hibernate 或 JPA 等持久性 API)
确保正确创建、重用和清理这些资源。该部分
还讨论了如何通过
相关。DataSourceTransactionManagerDataSourceHibernateTransactionManagerSessionFactoryTransactionManager
1.3.1. 高级同步方法
首选方法是使用 Spring 最高级别的基于模板的持久性
集成 API,或者将本机 ORM API 与事务感知工厂 bean 一起使用,或者
用于管理本机资源工厂的代理。这些交易感知解决方案
内部处理资源创建和重用、清理、可选事务
资源的同步和异常映射。因此,用户数据访问代码
不必处理这些任务,但可以专注于非样板
持久化逻辑。通常,您使用原生 ORM API 或采用模板方法
用于 JDBC 访问。这些解决方案将在后续
部分。JdbcTemplate
1.3.2. 低级同步方法
诸如 (for JDBC)、(for JPA)、(for Hibernate) 等类存在于较低级别。当您需要
应用程序代码直接处理本机持久性 API 的资源类型,
使用这些类来确保获得正确的 Spring Framework 托管实例,
事务是(可选)同步的,并且过程中发生的异常是
正确映射到一致的 API。DataSourceUtilsEntityManagerFactoryUtilsSessionFactoryUtils
例如,在 JDBC 的情况下,而不是传统的 JDBC 调用
的方法,你可以改用 Spring 的类,如下所示:getConnection()DataSourceorg.springframework.jdbc.datasource.DataSourceUtils
Connection conn = DataSourceUtils.getConnection(dataSource);如果现有事务已经同步(链接)了连接,则
instance 返回。否则,方法调用会触发创建新的
连接,该连接(可选)与任何现有事务同步并进行
可在同一交易中供后续重用。如前所述,any 包装在 Spring Framework 中,一个
的 Spring 框架的未选中类型的层次结构中。这种方法
提供的信息比从 和 中轻松获得的信息要多
确保跨数据库甚至跨不同持久性技术的可移植性。SQLExceptionCannotGetJdbcConnectionExceptionDataAccessExceptionSQLException
这种方法也可以在没有 Spring 事务管理(事务 synchronization 是可选的),因此无论您是否使用 Spring 事务管理。
当然,一旦您使用了 Spring 的 JDBC 支持、JPA 支持或 Hibernate 支持,
您通常不喜欢使用 或其他帮助程序类
因为您通过 Spring 抽象工作比直接使用 Spring 抽象要高得多
使用相关的 API。例如,如果使用 Spring 或 package 来简化 JDBC 的使用,则会进行正确的连接检索
在幕后,您无需编写任何特殊代码。DataSourceUtilsJdbcTemplatejdbc.object
1.4. 声明式事务管理
| 大多数 Spring Framework 用户选择声明式事务 Management。此选项具有 对应用程序代码的影响最小,因此最符合 非侵入性轻量级容器。 |
Spring 框架的声明式事务 Management 是通过 Spring 实现的 面向方面的编程 (AOP)。但是,随着事务性方面的代码 与 Spring Framework 发行版一起使用,并且可以以样板方式使用 AOP 通常不必理解概念即可有效使用此代码。
Spring 框架的声明式事务 Management 类似于 EJB CMT,因为
您可以指定事务行为(或缺少事务行为),直到单个方法级别。
您可以在事务上下文中进行调用,如果
必要。两种类型的事务管理之间的区别是:setRollbackOnly()
-
与与 JTA 绑定的 EJB CMT 不同,Spring 框架的声明式事务 管理适用于任何环境。它可以与 JTA 事务或本地 使用 JDBC、JPA 或 Hibernate 的事务,通过调整配置 文件。
-
您可以将 Spring Framework 声明式事务管理应用于任何类, 而不仅仅是 EJB 等特殊类。
-
Spring Framework 提供声明式回滚规则,这是一个没有 EJB 的功能 等效。提供了对回滚规则的编程和声明式支持。
-
Spring Framework 允许您使用 AOP 自定义事务行为。 例如,您可以在事务回滚的情况下插入自定义行为。你 还可以添加任意建议以及事务性建议。使用 EJB CMT,您可以 无法影响容器的事务管理,除非 .
setRollbackOnly() -
Spring Framework 不支持事务上下文的传播 远程调用,就像高端应用程序服务器一样。如果您需要此功能,我们 建议使用 EJB。但是,在使用此类功能之前,请仔细考虑, 因为,通常情况下,人们不希望事务跨越远程调用。
回滚规则的概念很重要。它们允许您指定哪些例外
(和 throwables)应该会导致自动回滚。您可以在
配置,而不是在 Java 代码中。所以,虽然你仍然可以调用
用于回滚当前事务的对象,最常见的是
可以指定必须始终导致回滚的规则。这
此选项的显著优点是 Business Objects 不依赖于
交易基础设施。例如,他们通常不需要导入 Spring
事务 API 或其他 Spring API 的 API 进行处理。setRollbackOnly()TransactionStatusMyApplicationException
尽管 EJB 容器默认行为会自动回滚
系统异常(通常是运行时异常),则 EJB CMT 不会回滚
transaction 在应用程序异常(即已检查的异常
除 ) 之外。虽然 Spring 的默认行为
声明式事务管理遵循 EJB 约定(回滚仅是自动的
on unchecked exceptions),自定义此行为通常很有用。java.rmi.RemoteException
1.4.1. 理解 Spring 框架的声明式事务实现
仅仅告诉你用注解来注解你的类,添加到你的配置中,是不够的。
并希望您了解这一切是如何运作的。为了提供更深入的理解,这个
部分介绍了 Spring 框架的声明式事务的内部工作原理
基础设施。@Transactional@EnableTransactionManagement
关于 Spring 框架的声明式,需要掌握的最重要的概念
事务支持是通过 AOP 代理启用的,并且事务
通知由元数据驱动(目前基于 XML 或 Comments)。AOP 的组合
的 AOP 代理会生成一个 AOP 代理,该代理使用
与适当的实施相结合以驱动交易
围绕方法调用。TransactionInterceptorTransactionManager
| Spring AOP 在 AOP 部分介绍。 |
Spring Framework 为
命令式和反应式编程模型。拦截器检测到所需的
transaction management 来检查方法返回类型。返回响应式
类型(例如 或 Kotlin)(或这些的子类型)符合 reactive 的条件
事务管理。所有其他返回类型(包括
命令式事务管理。TransactionInterceptorPublisherFlowvoid
事务管理风格会影响所需的事务管理器。祈使的
事务需要 ,而反应式事务使用实现。PlatformTransactionManagerReactiveTransactionManager
|
由 Management 的反应式事务使用 Reactor 上下文
而不是线程本地属性。因此,所有参与的数据都可以访问
操作需要在同一个反应式管道的同一个 Reactor 上下文中执行。 |
下图显示了在事务代理上调用方法的概念视图:
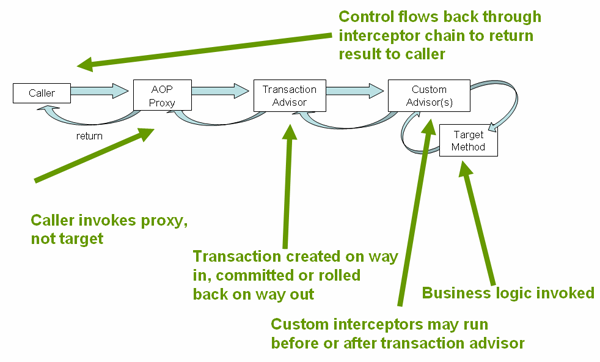
1.4.2. 声明式事务实现示例
请考虑以下接口及其附带的实现。此示例使用 和 类作为占位符,以便您可以专注于事务
使用,而不关注特定的域模型。在本示例中,
该类在每个已实现方法的主体中引发实例这一事实是好的。该行为让您看到
正在创建事务,然后回滚以响应实例。下面的清单显示了该接口:FooBarDefaultFooServiceUnsupportedOperationExceptionUnsupportedOperationExceptionFooService
// the service interface that we want to make transactional
package x.y.service;
public interface FooService {
Foo getFoo(String fooName);
Foo getFoo(String fooName, String barName);
void insertFoo(Foo foo);
void updateFoo(Foo foo);
}// the service interface that we want to make transactional
package x.y.service
interface FooService {
fun getFoo(fooName: String): Foo
fun getFoo(fooName: String, barName: String): Foo
fun insertFoo(foo: Foo)
fun updateFoo(foo: Foo)
}以下示例显示了上述接口的实现:
package x.y.service;
public class DefaultFooService implements FooService {
@Override
public Foo getFoo(String fooName) {
// ...
}
@Override
public Foo getFoo(String fooName, String barName) {
// ...
}
@Override
public void insertFoo(Foo foo) {
// ...
}
@Override
public void updateFoo(Foo foo) {
// ...
}
}package x.y.service
class DefaultFooService : FooService {
override fun getFoo(fooName: String): Foo {
// ...
}
override fun getFoo(fooName: String, barName: String): Foo {
// ...
}
override fun insertFoo(foo: Foo) {
// ...
}
override fun updateFoo(foo: Foo) {
// ...
}
}假设接口的前两个方法 和 必须在只读事务的上下文中运行
语义,并且其他方法 和 必须
在具有读写语义的事务上下文中运行。以下内容
接下来的几段将详细解释配置:FooServicegetFoo(String)getFoo(String, String)insertFoo(Foo)updateFoo(Foo)
<!-- from the file 'context.xml' -->
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
https://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/aop
https://www.springframework.org/schema/aop/spring-aop.xsd">
<!-- this is the service object that we want to make transactional -->
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<!-- the transactional advice (what 'happens'; see the <aop:advisor/> bean below) -->
<tx:advice id="txAdvice" transaction-manager="txManager">
<!-- the transactional semantics... -->
<tx:attributes>
<!-- all methods starting with 'get' are read-only -->
<tx:method name="get*" read-only="true"/>
<!-- other methods use the default transaction settings (see below) -->
<tx:method name="*"/>
</tx:attributes>
</tx:advice>
<!-- ensure that the above transactional advice runs for any execution
of an operation defined by the FooService interface -->
<aop:config>
<aop:pointcut id="fooServiceOperation" expression="execution(* x.y.service.FooService.*(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="fooServiceOperation"/>
</aop:config>
<!-- don't forget the DataSource -->
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@rj-t42:1521:elvis"/>
<property name="username" value="scott"/>
<property name="password" value="tiger"/>
</bean>
<!-- similarly, don't forget the TransactionManager -->
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- other <bean/> definitions here -->
</beans>检查前面的配置。它假定你想创建一个服务对象
bean 的 transaction 。要应用的事务语义是封装的
在定义中。定义为“所有方法
从 are 开始,在 read-only 事务的上下文中运行,并且所有
其他方法是使用默认的事务语义运行”。标记的属性设置为将要驱动事务的 Bean 的名称(在本例中为 Bean)。fooService<tx:advice/><tx:advice/>gettransaction-manager<tx:advice/>TransactionManagertxManager
您可以在 transactional advice 中省略该属性
() 如果要
wire in 的名称为 。如果 bean 中
You want to wire in 具有任何其他名称,则必须显式使用该属性,如前面的示例所示。transaction-manager<tx:advice/>TransactionManagertransactionManagerTransactionManagertransaction-manager |
该定义确保 Bean 定义的事务性建议在程序中的适当点运行。首先,定义一个
与接口中定义的任何操作的执行相匹配的切入点
().然后,使用
顾问。结果表明,在执行 、
由 定义的建议 is run.<aop:config/>txAdviceFooServicefooServiceOperationtxAdvicefooServiceOperationtxAdvice
在元素中定义的表达式是一个 AspectJ 切入点
表达。有关 pointcut 的更多详细信息,请参阅 AOP 部分
表达式。<aop:pointcut/>
一个常见的要求是使整个服务层具有事务性。最好的方法 执行此操作是为了更改切入点表达式以匹配 service 层。以下示例显示了如何执行此操作:
<aop:config>
<aop:pointcut id="fooServiceMethods" expression="execution(* x.y.service.*.*(..))"/>
<aop:advisor advice-ref="txAdvice" pointcut-ref="fooServiceMethods"/>
</aop:config>在前面的示例中,假定所有服务接口都已定义
在包中。有关更多详细信息,请参阅 AOP 部分。x.y.service |
现在我们已经分析了配置,您可能会问自己, “所有这些配置实际上是做什么的?”
前面显示的配置用于围绕对象创建事务代理
这是从 Bean 定义创建的。代理配置了
事务性通知,以便在代理上调用适当的方法时,
事务被启动、暂停、标记为只读等,具体取决于
transaction 配置。请考虑以下程序
该测试驱动前面显示的配置:fooService
public final class Boot {
public static void main(final String[] args) throws Exception {
ApplicationContext ctx = new ClassPathXmlApplicationContext("context.xml");
FooService fooService = ctx.getBean(FooService.class);
fooService.insertFoo(new Foo());
}
}import org.springframework.beans.factory.getBean
fun main() {
val ctx = ClassPathXmlApplicationContext("context.xml")
val fooService = ctx.getBean<FooService>("fooService")
fooService.insertFoo(Foo())
}运行上述程序的输出应类似于以下内容(Log4J
output 和类的方法引发的堆栈跟踪已被截断,以便清楚起见):UnsupportedOperationExceptioninsertFoo(..)DefaultFooService
<!-- the Spring container is starting up... -->
[AspectJInvocationContextExposingAdvisorAutoProxyCreator] - Creating implicit proxy for bean 'fooService' with 0 common interceptors and 1 specific interceptors
<!-- the DefaultFooService is actually proxied -->
[JdkDynamicAopProxy] - Creating JDK dynamic proxy for [x.y.service.DefaultFooService]
<!-- ... the insertFoo(..) method is now being invoked on the proxy -->
[TransactionInterceptor] - Getting transaction for x.y.service.FooService.insertFoo
<!-- the transactional advice kicks in here... -->
[DataSourceTransactionManager] - Creating new transaction with name [x.y.service.FooService.insertFoo]
[DataSourceTransactionManager] - Acquired Connection [org.apache.commons.dbcp.PoolableConnection@a53de4] for JDBC transaction
<!-- the insertFoo(..) method from DefaultFooService throws an exception... -->
[RuleBasedTransactionAttribute] - Applying rules to determine whether transaction should rollback on java.lang.UnsupportedOperationException
[TransactionInterceptor] - Invoking rollback for transaction on x.y.service.FooService.insertFoo due to throwable [java.lang.UnsupportedOperationException]
<!-- and the transaction is rolled back (by default, RuntimeException instances cause rollback) -->
[DataSourceTransactionManager] - Rolling back JDBC transaction on Connection [org.apache.commons.dbcp.PoolableConnection@a53de4]
[DataSourceTransactionManager] - Releasing JDBC Connection after transaction
[DataSourceUtils] - Returning JDBC Connection to DataSource
Exception in thread "main" java.lang.UnsupportedOperationException at x.y.service.DefaultFooService.insertFoo(DefaultFooService.java:14)
<!-- AOP infrastructure stack trace elements removed for clarity -->
at $Proxy0.insertFoo(Unknown Source)
at Boot.main(Boot.java:11)要使用反应式事务管理,代码必须使用反应式类型。
Spring Framework 使用 来确定
return 类型是 Reactive。ReactiveAdapterRegistry |
下面的清单显示了以前使用的 , 但
这次代码使用了反应式类型:FooService
// the reactive service interface that we want to make transactional
package x.y.service;
public interface FooService {
Flux<Foo> getFoo(String fooName);
Publisher<Foo> getFoo(String fooName, String barName);
Mono<Void> insertFoo(Foo foo);
Mono<Void> updateFoo(Foo foo);
}// the reactive service interface that we want to make transactional
package x.y.service
interface FooService {
fun getFoo(fooName: String): Flow<Foo>
fun getFoo(fooName: String, barName: String): Publisher<Foo>
fun insertFoo(foo: Foo) : Mono<Void>
fun updateFoo(foo: Foo) : Mono<Void>
}以下示例显示了上述接口的实现:
package x.y.service;
public class DefaultFooService implements FooService {
@Override
public Flux<Foo> getFoo(String fooName) {
// ...
}
@Override
public Publisher<Foo> getFoo(String fooName, String barName) {
// ...
}
@Override
public Mono<Void> insertFoo(Foo foo) {
// ...
}
@Override
public Mono<Void> updateFoo(Foo foo) {
// ...
}
}package x.y.service
class DefaultFooService : FooService {
override fun getFoo(fooName: String): Flow<Foo> {
// ...
}
override fun getFoo(fooName: String, barName: String): Publisher<Foo> {
// ...
}
override fun insertFoo(foo: Foo): Mono<Void> {
// ...
}
override fun updateFoo(foo: Foo): Mono<Void> {
// ...
}
}命令式事务管理和反应式事务管理共享相同的事务语义
boundary 和 transaction 属性定义。命令式
而 reactive transactions 是后者的 delayend 性质。 使用事务运算符装饰返回的响应式类型以开始和清理
交易。因此,调用事务响应式方法会延迟实际的
transaction management 添加到一个订阅类型中,该订阅类型激活了 Reactive
类型。TransactionInterceptor
反应式事务管理的另一个方面与数据转义有关,它是一个 编程模型的自然结果。
命令式事务的方法返回值是从事务性方法返回的 成功终止方法时,以便部分计算的结果不会转义 方法闭包。
反应式事务方法返回一个反应式包装器类型,它表示一个 计算序列以及开始和完成计算的 Promise。
A 可以在事务正在进行但不一定完成时发出数据。
因此,依赖于成功完成整个事务的方法需要
以确保 completion 和 buffer 结果在调用代码中。Publisher
1.4.3. 回滚声明式事务
上一节概述了如何为
类(通常是服务层类)在您的应用程序中以声明方式。本节
描述如何在简单的声明式
fashion 的 XML 配置。有关以声明方式控制回滚语义的详细信息
使用注释,请参阅@Transactional设置。@Transactional
向 Spring 框架的事务基础结构指示的推荐方法
事务的工作要回滚是抛出一个 from 代码,该
当前正在事务的上下文中执行。Spring 框架的
交易基础设施代码在冒泡时捕获任何未处理的
调用堆栈,并确定是否将事务标记为回滚。ExceptionException
在其默认配置中, Spring 框架的事务基础结构代码
仅在运行时未检查异常的情况下将事务标记为回滚。
也就是说,当引发的异常是 的实例或子类时。
( 实例也默认会导致回滚)。已检查的异常
从事务方法抛出的 URL 不会导致默认的 Rollback
配置。RuntimeExceptionError
您可以准确配置哪些类型将事务标记为回滚,
通过指定回滚规则来包括已检查的异常。Exception
|
回滚规则
回滚规则确定在给定异常
thrown,规则基于模式。模式可以是完全限定的类
name 或异常类型的完全限定类名的子字符串(必须是
) 的子类),目前不支持通配符。例如,值 or 将匹配其子类。 回滚规则可以通过 和 属性在 XML 中配置,该属性允许将模式指定为字符串。使用
|
以下 XML 代码段演示了如何为选中的
Application-specific 类型,方法是通过属性提供异常模式:Exceptionrollback-for
<tx:advice id="txAdvice" transaction-manager="txManager">
<tx:attributes>
<tx:method name="get*" read-only="true" rollback-for="NoProductInStockException"/>
<tx:method name="*"/>
</tx:attributes>
</tx:advice>如果您不希望在引发异常时回滚事务,您还可以
指定 'No rollback' 规则。下面的示例告诉 Spring 框架的
transaction 基础设施来提交伴随的事务,即使面对
未处理 :InstrumentNotFoundException
<tx:advice id="txAdvice">
<tx:attributes>
<tx:method name="updateStock" no-rollback-for="InstrumentNotFoundException"/>
<tx:method name="*"/>
</tx:attributes>
</tx:advice>当 Spring 框架的事务基础结构捕获到异常并咨询
配置的 rollback 规则,用于确定是否将事务标记为 rollback,
最强的匹配规则胜出。因此,在以下配置的情况下,任何
exception 会导致
随行交易:InstrumentNotFoundException
<tx:advice id="txAdvice">
<tx:attributes>
<tx:method name="*" rollback-for="Throwable" no-rollback-for="InstrumentNotFoundException"/>
</tx:attributes>
</tx:advice>您还可以以编程方式指示所需的回滚。虽然简单,但这个过程 非常具有侵入性,并将您的代码与 Spring Framework 的事务紧密耦合 基础设施。以下示例演示如何以编程方式指示所需的 反转:
public void resolvePosition() {
try {
// some business logic...
} catch (NoProductInStockException ex) {
// trigger rollback programmatically
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
}
}fun resolvePosition() {
try {
// some business logic...
} catch (ex: NoProductInStockException) {
// trigger rollback programmatically
TransactionAspectSupport.currentTransactionStatus().setRollbackOnly();
}
}强烈建议您使用声明式方法进行回滚(如果有的话) 可能。如果您绝对需要,可以使用编程回滚,但其 使用与实现基于 POJO 的干净架构背道而驰。
1.4.4. 为不同的 bean 配置不同的事务语义
考虑这样一个场景:您有许多服务层对象,并且您希望
对它们中的每一个应用完全不同的事务配置。您可以这样做
通过定义具有不同值和属性值的不同元素。<aop:advisor/>pointcutadvice-ref
作为比较点,首先假设您的所有服务图层类都是
在根包中定义。使所有 bean 都是类的实例
在该包(或子包)中定义,并且名称以 have 结尾
default transactional configuration,您可以编写以下内容:x.y.serviceService
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
https://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/aop
https://www.springframework.org/schema/aop/spring-aop.xsd">
<aop:config>
<aop:pointcut id="serviceOperation"
expression="execution(* x.y.service..*Service.*(..))"/>
<aop:advisor pointcut-ref="serviceOperation" advice-ref="txAdvice"/>
</aop:config>
<!-- these two beans will be transactional... -->
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<bean id="barService" class="x.y.service.extras.SimpleBarService"/>
<!-- ... and these two beans won't -->
<bean id="anotherService" class="org.xyz.SomeService"/> <!-- (not in the right package) -->
<bean id="barManager" class="x.y.service.SimpleBarManager"/> <!-- (doesn't end in 'Service') -->
<tx:advice id="txAdvice">
<tx:attributes>
<tx:method name="get*" read-only="true"/>
<tx:method name="*"/>
</tx:attributes>
</tx:advice>
<!-- other transaction infrastructure beans such as a TransactionManager omitted... -->
</beans>下面的示例展示了如何配置两个完全不同的 bean 事务设置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
https://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/aop
https://www.springframework.org/schema/aop/spring-aop.xsd">
<aop:config>
<aop:pointcut id="defaultServiceOperation"
expression="execution(* x.y.service.*Service.*(..))"/>
<aop:pointcut id="noTxServiceOperation"
expression="execution(* x.y.service.ddl.DefaultDdlManager.*(..))"/>
<aop:advisor pointcut-ref="defaultServiceOperation" advice-ref="defaultTxAdvice"/>
<aop:advisor pointcut-ref="noTxServiceOperation" advice-ref="noTxAdvice"/>
</aop:config>
<!-- this bean will be transactional (see the 'defaultServiceOperation' pointcut) -->
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<!-- this bean will also be transactional, but with totally different transactional settings -->
<bean id="anotherFooService" class="x.y.service.ddl.DefaultDdlManager"/>
<tx:advice id="defaultTxAdvice">
<tx:attributes>
<tx:method name="get*" read-only="true"/>
<tx:method name="*"/>
</tx:attributes>
</tx:advice>
<tx:advice id="noTxAdvice">
<tx:attributes>
<tx:method name="*" propagation="NEVER"/>
</tx:attributes>
</tx:advice>
<!-- other transaction infrastructure beans such as a TransactionManager omitted... -->
</beans>1.4.5. <tx:advice/> 设置
本节总结了您可以使用
标签。默认设置为:<tx:advice/><tx:advice/>
-
传播设置为
REQUIRED. -
隔离级别为
DEFAULT. -
事务是读写的。
-
事务超时默认为基础事务的默认超时 system 或 none (如果不支持超时)。
-
any 触发器回滚,而 any checked 则不会。
RuntimeExceptionException
您可以更改这些默认设置。下表总结了标签的各种属性
嵌套在 and 标记中:<tx:method/><tx:advice/><tx:attributes/>
| 属性 | 必填? | 违约 | 描述 |
|---|---|---|---|
|
是的 |
要与事务属性关联的方法名称。这
通配符 (*) 字符可用于关联相同的事务属性
具有多种方法的设置(例如, , , , 等
forth)。 |
|
|
不 |
|
事务传播行为。 |
|
不 |
|
事务隔离级别。仅适用于 或 的传播设置 。 |
|
不 |
-1 |
事务超时 (秒)。仅适用于传播或 。 |
|
不 |
假 |
读写与只读事务。仅适用于 或 。 |
|
不 |
以逗号分隔的触发回滚的实例列表。例如。 |
|
|
不 |
不触发回滚的实例列表(以逗号分隔)。例如。 |
1.4.6. 使用@Transactional
除了基于 XML 的声明式事务配置方法外,您还可以 使用基于注释的方法。直接在 Java 中声明事务语义 源代码使声明更接近受影响的代码。没有太多 过度耦合的危险,因为本应以事务方式使用的代码是 无论如何,几乎总是以这种方式部署。
标准注释也支持作为
drop-in 替换到 Spring 自己的 Comments 中。请参阅 JTA 1.2 文档
了解更多详情。javax.transaction.Transactional |
使用 Comments 提供的易用性是最好的
用一个例子来说明,这将在下面的文本中解释。
请考虑以下类定义:@Transactional
// the service class that we want to make transactional
@Transactional
public class DefaultFooService implements FooService {
@Override
public Foo getFoo(String fooName) {
// ...
}
@Override
public Foo getFoo(String fooName, String barName) {
// ...
}
@Override
public void insertFoo(Foo foo) {
// ...
}
@Override
public void updateFoo(Foo foo) {
// ...
}
}// the service class that we want to make transactional
@Transactional
class DefaultFooService : FooService {
override fun getFoo(fooName: String): Foo {
// ...
}
override fun getFoo(fooName: String, barName: String): Foo {
// ...
}
override fun insertFoo(foo: Foo) {
// ...
}
override fun updateFoo(foo: Foo) {
// ...
}
}如上所述,在类级别使用,注解表示
声明类(及其子类)。或者,每种方法都可以是
单独注释。请参阅方法可见性和@Transactional
有关 Spring 认为哪些方法为事务性的更多详细信息。请注意,类级别
annotation 不适用于 class 层次结构中的祖先类;在这种情况下,
继承的方法需要在本地重新声明才能参与
subclass-level 注解。
当 POJO 类(如上面的类)在 Spring 上下文中被定义为 bean 时,
您可以通过类中的 Comments 使 Bean 实例具有事务性。有关完整详细信息,请参阅 javadoc。@EnableTransactionManagement@Configuration
在 XML 配置中,标记提供了类似的便利:<tx:annotation-driven/>
<!-- from the file 'context.xml' -->
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
https://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/aop
https://www.springframework.org/schema/aop/spring-aop.xsd">
<!-- this is the service object that we want to make transactional -->
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<!-- enable the configuration of transactional behavior based on annotations -->
<!-- a TransactionManager is still required -->
<tx:annotation-driven transaction-manager="txManager"/> (1)
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<!-- (this dependency is defined somewhere else) -->
<property name="dataSource" ref="dataSource"/>
</bean>
<!-- other <bean/> definitions here -->
</beans>| 1 | 使 Bean 实例成为事务性的行。 |
如果要连接 的 bean 名称具有 name .如果要 dependency-inject
具有任何其他名称,则必须使用该属性,如
前面的示例。transaction-manager<tx:annotation-driven/>TransactionManagertransactionManagerTransactionManagertransaction-manager |
与命令式相反,反应式事务方法使用反应式返回类型 编程安排如下 清单所示:
// the reactive service class that we want to make transactional
@Transactional
public class DefaultFooService implements FooService {
@Override
public Publisher<Foo> getFoo(String fooName) {
// ...
}
@Override
public Mono<Foo> getFoo(String fooName, String barName) {
// ...
}
@Override
public Mono<Void> insertFoo(Foo foo) {
// ...
}
@Override
public Mono<Void> updateFoo(Foo foo) {
// ...
}
}// the reactive service class that we want to make transactional
@Transactional
class DefaultFooService : FooService {
override fun getFoo(fooName: String): Flow<Foo> {
// ...
}
override fun getFoo(fooName: String, barName: String): Mono<Foo> {
// ...
}
override fun insertFoo(foo: Foo): Mono<Void> {
// ...
}
override fun updateFoo(foo: Foo): Mono<Void> {
// ...
}
}请注意,返回的 cookie 有一些特殊的注意事项
Reactive Streams 取消信号。请参阅 Cancel Signals 部分
“使用 TransactionalOperator”了解更多详细信息。Publisher
|
方法 visibility 和
@Transactional当您将事务代理与 Spring 的标准配置一起使用时,您应该应用
仅对具有可见性的方法进行注释。如果你这样做
annotate 、 , 或 package-visible 方法时,不会引发错误,但 annotated 方法不会显示配置的
事务设置。如果需要注释非公共方法,请考虑
以下段落用于基于类的代理,或者考虑使用 AspectJ 编译时或
加载时编织(稍后介绍)。 在类中使用时,或者
package-visible 方法也可以通过以下方式为基于类的代理提供事务性
注册自定义 Bean,如以下示例所示。
但是请注意,基于接口的代理中的事务方法必须始终在代理接口中定义。 Spring TestContext 框架通过以下方式支持非私有测试方法
违约。在测试中查看 Transaction Management
章。 |
您可以将注释应用于接口定义,即方法
在接口、类定义或类上的方法上。然而,仅仅存在
的注释不足以激活事务行为。
注解只是元数据,可以由相应的
运行时基础结构,该基础结构使用该元数据来配置适当的 bean
交易行为。在前面的示例中,元素
在运行时打开实际事务管理。@Transactional@Transactional@Transactional<tx:annotation-driven/>
Spring 团队建议您使用注解来注解具体类的方法,而不是依赖接口中的注解方法。
即使后者在 5.0 中确实适用于基于接口的代理和 Target 类代理。
由于 Java 注解不是从接口继承的,因此接口声明的注解
在使用 AspectJ 模式时仍然无法被 weaveing 基础设施识别,因此
aspect 不会被应用。因此,您的交易注释可能是
静默忽略:在您测试回滚方案之前,您的代码可能看起来“有效”。@Transactional |
在代理模式(这是默认模式)下,只有外部方法调用通过
代理被拦截。这意味着自调用(实际上是
target 对象调用 target 对象的另一个方法)不会导致实际的
transaction 在运行时进行交易,即使调用的方法标记为 .也
代理必须完全初始化才能提供预期行为,因此您不应
在初始化代码中依赖此功能 — 例如,在 Method 中。@Transactional@PostConstruct |
考虑使用 AspectJ 模式(参见下表中的属性),如果你
期望 self-invocations 也将与 transactions 一起包装。在这种情况下,有
首先没有代理。相反,目标类是 woven 的(即它的字节码
被修改)以支持任何类型的方法的运行时行为。mode@Transactional
| XML 属性 | 注释属性 | 违约 | 描述 |
|---|---|---|---|
|
不适用(请参阅 |
|
要使用的事务管理器的名称。仅当交易名称
manager 不是 ,如前面的示例所示。 |
|
|
|
默认模式()处理带注释的 bean 以使用 Spring 的 AOP 进行代理
框架(如前所述,遵循代理语义,应用于方法调用
仅通过代理进入)。相反,替代模式 () 将
影响了具有 Spring 的 AspectJ 事务方面的类,修改了目标类
字节码应用于任何类型的方法调用。AspectJ 编织需要在 Classpath 中,并启用加载时编织(或编译时编织)。
(有关如何设置的详细信息,请参阅 Spring 配置
加载时编织。 |
|
|
|
仅适用于 mode。控制创建的交易代理类型
对于使用注释进行注释的类。如果该属性设置为 ,则会创建基于类的代理。如果省略了 is 或该属性,则基于 JDK 接口的标准代理为
创建。(有关详细检查,请参见代理机制
的不同代理类型。 |
|
|
|
定义应用于 Comments 为 的 bean 的事务通知的顺序。(有关 AOP 排序相关规则的更多信息
建议,请参阅 建议排序。
没有指定的 Sequences 意味着 AOP 子系统确定通知的 Sequences。 |
处理 annotation 的默认通知模式是 ,
,它仅允许通过代理拦截调用。本地调用
同一个类不能以这种方式被拦截。对于更高级的拦截模式,
考虑切换到与编译时或加载时编织相结合的模式。@Transactionalproxyaspectj |
该属性控制交易代理的类型
为使用注释注释的类创建。如果设置为 ,则会创建基于类的代理。如果是或省略属性,则为标准 JDK
创建基于接口的代理。(有关不同代理类型的讨论,请参阅 代理机制。proxy-target-class@Transactionalproxy-target-classtrueproxy-target-classfalse |
@EnableTransactionManagement并仅在定义 bean 的同一应用程序上下文中查找 bean。
这意味着,如果您将 Comments 驱动的配置放在 for a for a 中,它只会检查控制器中的 bean
而不是在你的服务中。有关更多信息,请参阅 MVC。<tx:annotation-driven/>@TransactionalWebApplicationContextDispatcherServlet@Transactional |
在评估事务设置时,派生程度最高的位置优先
对于方法。在以下示例中,类为
在类级别使用只读事务的设置进行注释,但同一类中方法的注释采用
优先于在 Class 级别定义的事务设置。DefaultFooService@TransactionalupdateFoo(Foo)
@Transactional(readOnly = true)
public class DefaultFooService implements FooService {
public Foo getFoo(String fooName) {
// ...
}
// these settings have precedence for this method
@Transactional(readOnly = false, propagation = Propagation.REQUIRES_NEW)
public void updateFoo(Foo foo) {
// ...
}
}@Transactional(readOnly = true)
class DefaultFooService : FooService {
override fun getFoo(fooName: String): Foo {
// ...
}
// these settings have precedence for this method
@Transactional(readOnly = false, propagation = Propagation.REQUIRES_NEW)
override fun updateFoo(foo: Foo) {
// ...
}
}@Transactional设置
注解是元数据,它指定接口、类、
或方法必须具有事务语义(例如,“启动全新的只读
transaction 来暂停任何现有事务”)。
默认设置如下:@Transactional@Transactional
-
传播设置为
PROPAGATION_REQUIRED. -
隔离级别为
ISOLATION_DEFAULT. -
事务是读写的。
-
事务超时默认为基础事务的默认超时 system,如果不支持超时,则设置为 none。
-
any 或 会触发回滚,而 any checked 会触发 不。
RuntimeExceptionErrorException
您可以更改这些默认设置。下表总结了各种
注释的属性:@Transactional
| 财产 | 类型 | 描述 |
|---|---|---|
|
指定要使用的事务管理器的可选限定符。 |
|
|
|
的别名 . |
|
标签数组,用于向事务添加富有表现力的描述。 |
事务管理器可以评估标签,以将特定于实现的行为与实际事务相关联。 |
|
可选的传播设置。 |
|
|
|
可选隔离级别。仅适用于 或 的传播值。 |
|
|
可选的事务超时。仅适用于 或 的传播值。 |
|
|
将 in seconds 指定为值的替代方法 — 例如,作为占位符。 |
|
|
读写与只读事务。仅适用于 或 的值。 |
|
对象数组,必须从 |
必须导致回滚的异常类型的可选数组。 |
|
异常名称模式的数组。 |
必须导致回滚的异常名称模式的可选数组。 |
|
对象数组,必须从 |
不得导致回滚的异常类型的可选数组。 |
|
异常名称模式的数组。 |
不得导致回滚的异常名称模式的可选数组。 |
| 有关更多详细信息,请参阅 Rollback rules On Rollback 规则语义、模式和有关可能的无意警告 比赛。 |
目前,您无法对事务的名称进行显式控制,其中 'name'
表示事务监视器中显示的事务名称(如果适用)
(例如,WebLogic 的事务监视器)和日志记录输出。对于声明性
transactions 时,事务名称始终是完全限定的类名 + + 事务性建议类的方法名。例如,如果类的方法启动了事务,则
交易的名称将为: 。.handlePayment(..)BusinessServicecom.example.BusinessService.handlePayment
多个事务管理器@Transactional
大多数 Spring 应用程序只需要一个事务 Management 器,但可能有
您希望在单个事务管理器中有多个独立的事务管理器的情况
应用。您可以使用注释的 or 属性(可选)来指定要使用的 的标识。这可以是 bean 名称或 qualifier 值
事务管理器 Bean 中。例如,使用限定符表示法,您可以
将以下 Java 代码与以下事务管理器 Bean 声明组合在一起
在应用程序上下文中:valuetransactionManager@TransactionalTransactionManager
public class TransactionalService {
@Transactional("order")
public void setSomething(String name) { ... }
@Transactional("account")
public void doSomething() { ... }
@Transactional("reactive-account")
public Mono<Void> doSomethingReactive() { ... }
}class TransactionalService {
@Transactional("order")
fun setSomething(name: String) {
// ...
}
@Transactional("account")
fun doSomething() {
// ...
}
@Transactional("reactive-account")
fun doSomethingReactive(): Mono<Void> {
// ...
}
}下面的清单显示了 bean 声明:
<tx:annotation-driven/>
<bean id="transactionManager1" class="org.springframework.jdbc.support.JdbcTransactionManager">
...
<qualifier value="order"/>
</bean>
<bean id="transactionManager2" class="org.springframework.jdbc.support.JdbcTransactionManager">
...
<qualifier value="account"/>
</bean>
<bean id="transactionManager3" class="org.springframework.data.r2dbc.connection.R2dbcTransactionManager">
...
<qualifier value="reactive-account"/>
</bean>在这种情况下,在单独的
事务管理器,由 、 和 限定符区分。默认目标 Bean 名称 ,
如果未找到特别限定的 bean,则仍会使用。TransactionalServiceorderaccountreactive-account<tx:annotation-driven>transactionManagerTransactionManager
自定义组合注释
如果您发现您在许多不同的
方法,Spring 的元注释支持允许您
为您的特定使用案例定义自定义组合注释。例如,考虑
以下注释定义:@Transactional
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Transactional(transactionManager = "order", label = "causal-consistency")
public @interface OrderTx {
}
@Target({ElementType.METHOD, ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
@Transactional(transactionManager = "account", label = "retryable")
public @interface AccountTx {
}@Target(AnnotationTarget.FUNCTION, AnnotationTarget.TYPE)
@Retention(AnnotationRetention.RUNTIME)
@Transactional(transactionManager = "order", label = ["causal-consistency"])
annotation class OrderTx
@Target(AnnotationTarget.FUNCTION, AnnotationTarget.TYPE)
@Retention(AnnotationRetention.RUNTIME)
@Transactional(transactionManager = "account", label = ["retryable"])
annotation class AccountTx前面的注释让我们编写上一节中的示例,如下所示:
public class TransactionalService {
@OrderTx
public void setSomething(String name) {
// ...
}
@AccountTx
public void doSomething() {
// ...
}
}class TransactionalService {
@OrderTx
fun setSomething(name: String) {
// ...
}
@AccountTx
fun doSomething() {
// ...
}
}在前面的示例中,我们使用了语法来定义事务管理器限定符 和事务标签,但我们也可以包括传播行为 回滚规则、超时和其他功能。
1.4.7. 事务传播
本节描述了 Spring 中事务传播的一些语义。注意 本节不是对 Transaction Propagation 的适当介绍。相反,它 详细介绍了 Spring 中有关事务传播的一些语义。
在 Spring 管理的事务中,请注意 physical 和 logical transactions 的 Barrier 事务,以及 PROPAGATION 设置如何应用于此差异。
理解PROPAGATION_REQUIRED
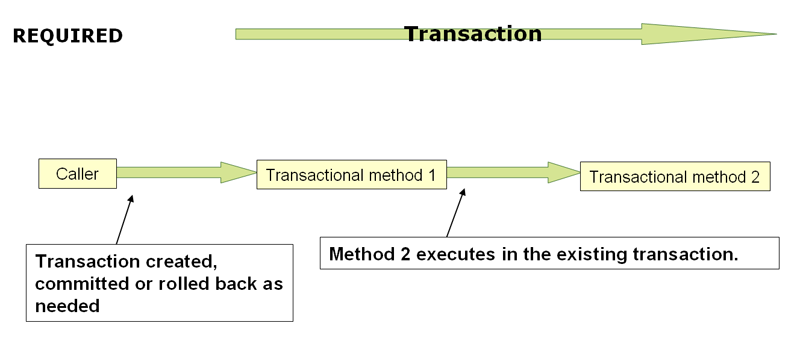
PROPAGATION_REQUIRED强制执行物理事务,无论是在本地为当前的
scope(如果尚不存在交易或参与现有的 'outer' 交易)
为更大的范围定义。这是常见调用堆栈安排中的一个很好的默认值
在同一线程中(例如,委托给多个存储库方法的服务门面
其中所有底层资源都必须参与服务级事务)。
默认情况下,参与的事务会加入外部范围
静默忽略本地隔离级别、超时值或只读标志(如果有)。
考虑将标志切换到您的交易
manager 如果您希望在参与
具有不同隔离级别的现有事务。这种不宽容的模式也
拒绝只读不匹配(即尝试参与的内部读写事务
在只读外部作用域中)。validateExistingTransactionstrue |
当传播设置为 时,逻辑事务范围
为应用该设置的每种方法创建。每个这样的逻辑
transaction 作用域可以单独确定仅回滚状态,并使用外部
事务范围在逻辑上独立于内部事务范围。
在标准行为的情况下,所有这些范围都是
映射到同一 Physical 事务。因此,在内部
事务范围确实会影响外部事务实际提交的机会。PROPAGATION_REQUIREDPROPAGATION_REQUIRED
但是,在内部事务范围设置仅回滚标记的情况下,
outer 事务尚未决定回滚本身,因此 rollback (静默地
triggered by the inner transaction scope)是意外的。此时会抛出相应的信息。这是预期行为,因此
事务的调用者永远不会被误导认为提交是
在它真的没有的时候表演。因此,如果内部事务(其中外部调用者
不知道)以静默方式将事务标记为仅回滚,外部调用方仍
调用 commit。外部调用方需要接收 to
清楚地指示已执行回滚。UnexpectedRollbackExceptionUnexpectedRollbackException
理解PROPAGATION_REQUIRES_NEW
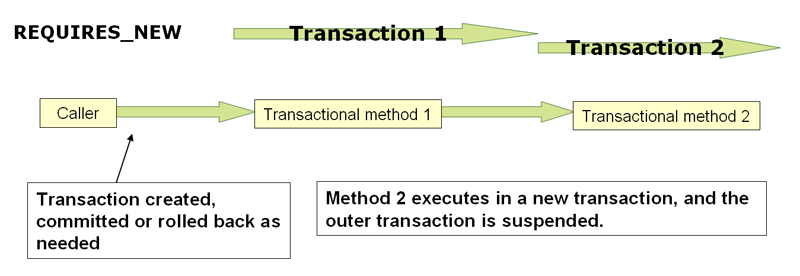
PROPAGATION_REQUIRES_NEW,与 相比,始终使用
每个受影响的事务范围的独立物理事务,从不
参与 outer scope 的现有事务。在这样的安排下,
底层资源事务是不同的,因此可以提交或回滚
独立,外部事务不受内部事务回滚的影响
状态,并在内部事务完成后立即释放其锁。
这样一个独立的内部事务也可以声明自己的隔离级别 timeout,
和只读设置,并且不会继承外部事务的特征。PROPAGATION_REQUIRED
附加到外部事务的资源将保持绑定状态,而
内部事务获取自己的资源,例如新的 Database Connection。
这可能会导致连接池耗尽,并可能导致死锁,如果
多个线程具有活动的外部事务并等待获取新连接
对于他们的内部交易,矿池无法分发任何此类内部
连接。除非您的连接池
的大小适当,至少超过并发线程数 1。PROPAGATION_REQUIRES_NEW |
理解PROPAGATION_NESTED
PROPAGATION_NESTED使用具有多个 Savepoint 的单个物理事务
它可以回滚到。这种部分回滚允许内部事务范围
触发其范围的回滚,外部事务能够继续
尽管某些操作已回滚,但 Physical Transaction 仍会丢失。此设置
通常映射到 JDBC 保存点,因此它仅适用于 JDBC 资源
交易。参见 Spring 的DataSourceTransactionManager。
1.4.8. 为事务性操作提供建议
假设您要同时运行事务操作和一些基本的分析建议。
在 ?<tx:annotation-driven/>
调用该方法时,您希望看到以下操作:updateFoo(Foo)
-
配置的分析方面将启动。
-
事务性建议运行。
-
将运行建议对象上的方法。
-
事务提交。
-
分析方面报告整个事务方法调用的确切持续时间。
| 本章不涉及对 AOP 的任何详细解释(除了它 适用于交易)。有关 AOP 的详细覆盖范围,请参阅 AOP 配置和 AOP 的 AOP 进行配置。 |
以下代码显示了前面讨论的简单性能分析方面:
package x.y;
import org.aspectj.lang.ProceedingJoinPoint;
import org.springframework.util.StopWatch;
import org.springframework.core.Ordered;
public class SimpleProfiler implements Ordered {
private int order;
// allows us to control the ordering of advice
public int getOrder() {
return this.order;
}
public void setOrder(int order) {
this.order = order;
}
// this method is the around advice
public Object profile(ProceedingJoinPoint call) throws Throwable {
Object returnValue;
StopWatch clock = new StopWatch(getClass().getName());
try {
clock.start(call.toShortString());
returnValue = call.proceed();
} finally {
clock.stop();
System.out.println(clock.prettyPrint());
}
return returnValue;
}
}class SimpleProfiler : Ordered {
private var order: Int = 0
// allows us to control the ordering of advice
override fun getOrder(): Int {
return this.order
}
fun setOrder(order: Int) {
this.order = order
}
// this method is the around advice
fun profile(call: ProceedingJoinPoint): Any {
var returnValue: Any
val clock = StopWatch(javaClass.name)
try {
clock.start(call.toShortString())
returnValue = call.proceed()
} finally {
clock.stop()
println(clock.prettyPrint())
}
return returnValue
}
}通知的排序
通过界面进行控制。有关建议订购的完整详细信息,请参阅建议订购。Ordered
以下配置创建一个 Bean,该 Bean 具有 profiling 和
按所需顺序应用于它的事务方面:fooService
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
https://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/aop
https://www.springframework.org/schema/aop/spring-aop.xsd">
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<!-- this is the aspect -->
<bean id="profiler" class="x.y.SimpleProfiler">
<!-- run before the transactional advice (hence the lower order number) -->
<property name="order" value="1"/>
</bean>
<tx:annotation-driven transaction-manager="txManager" order="200"/>
<aop:config>
<!-- this advice runs around the transactional advice -->
<aop:aspect id="profilingAspect" ref="profiler">
<aop:pointcut id="serviceMethodWithReturnValue"
expression="execution(!void x.y..*Service.*(..))"/>
<aop:around method="profile" pointcut-ref="serviceMethodWithReturnValue"/>
</aop:aspect>
</aop:config>
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="oracle.jdbc.driver.OracleDriver"/>
<property name="url" value="jdbc:oracle:thin:@rj-t42:1521:elvis"/>
<property name="username" value="scott"/>
<property name="password" value="tiger"/>
</bean>
<bean id="txManager" class="org.springframework.jdbc.datasource.DataSourceTransactionManager">
<property name="dataSource" ref="dataSource"/>
</bean>
</beans>您可以配置任意数量 以类似的方式进行其他方面的攻击。
以下示例创建与前两个示例相同的设置,但使用纯 XML 声明式方法:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
https://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/aop
https://www.springframework.org/schema/aop/spring-aop.xsd">
<bean id="fooService" class="x.y.service.DefaultFooService"/>
<!-- the profiling advice -->
<bean id="profiler" class="x.y.SimpleProfiler">
<!-- run before the transactional advice (hence the lower order number) -->
<property name="order" value="1"/>
</bean>
<aop:config>
<aop:pointcut id="entryPointMethod" expression="execution(* x.y..*Service.*(..))"/>
<!-- runs after the profiling advice (cf. the order attribute) -->
<aop:advisor advice-ref="txAdvice" pointcut-ref="entryPointMethod" order="2"/>
<!-- order value is higher than the profiling aspect -->
<aop:aspect id="profilingAspect" ref="profiler">
<aop:pointcut id="serviceMethodWithReturnValue"
expression="execution(!void x.y..*Service.*(..))"/>
<aop:around method="profile" pointcut-ref="serviceMethodWithReturnValue"/>
</aop:aspect>
</aop:config>
<tx:advice id="txAdvice" transaction-manager="txManager">
<tx:attributes>
<tx:method name="get*" read-only="true"/>
<tx:method name="*"/>
</tx:attributes>
</tx:advice>
<!-- other <bean/> definitions such as a DataSource and a TransactionManager here -->
</beans>上述配置的结果是一个具有 profiling 和
交易方面按此顺序应用于它。如果需要性能分析建议
在 transaction advice 之后和 access 之前运行
交易建议 在退出的路上,您可以交换分析的值
aspect bean 的属性,使其高于事务通知的
order 值。fooServiceorder
您可以以类似的方式配置其他方面。
1.4.9. 与 AspectJ 一起使用@Transactional
你也可以在 Spring 之外使用 Spring 框架的支持
container 通过 AspectJ 切面。为此,请先为您的类添加注释
(以及可选的类的方法)和注解
然后将您的应用程序与文件中定义的 LINK (WEAVE) 链接。您还必须使用事务配置 aspect
经理。你可以使用 Spring 框架的 IoC 容器来处理
dependency-injecting 方面。配置事务的最简单方法
management 方面是使用元素并指定属性 to,如 使用 @Transactional中所述。因为
我们在这里重点介绍在 Spring 容器之外运行的应用程序,我们展示了
你如何以编程方式做到这一点。@Transactional@Transactionalorg.springframework.transaction.aspectj.AnnotationTransactionAspectspring-aspects.jar<tx:annotation-driven/>modeaspectj
在继续之前,您可能希望分别阅读使用 @Transactional 和 AOP。 |
以下示例显示了如何创建事务管理器并配置以使用它:AnnotationTransactionAspect
// construct an appropriate transaction manager
DataSourceTransactionManager txManager = new DataSourceTransactionManager(getDataSource());
// configure the AnnotationTransactionAspect to use it; this must be done before executing any transactional methods
AnnotationTransactionAspect.aspectOf().setTransactionManager(txManager);// construct an appropriate transaction manager
val txManager = DataSourceTransactionManager(getDataSource())
// configure the AnnotationTransactionAspect to use it; this must be done before executing any transactional methods
AnnotationTransactionAspect.aspectOf().transactionManager = txManager| 当您使用此方面时,您必须注释 implementation 类(或方法 在该类中或两者中),而不是该类实现的接口(如果有)。AspectJ 遵循 Java 的规则,即不继承接口上的 Comments。 |
类的注释指定了默认的事务语义
用于执行类中的任何公共方法。@Transactional
类中方法的注释将覆盖默认值
类注解(如果存在)给出的交易语义。您可以注释任何方法,
无论可见性如何。@Transactional
要使用 编织应用程序,您必须构建
你的应用程序与 AspectJ 一起(参见 AspectJ 开发
Guide) 或使用加载时编织。参见 加载时编织
Spring 框架中的 AspectJ 来讨论使用 AspectJ 进行加载时编织。AnnotationTransactionAspect
1.5. 程序化事务管理
Spring 框架提供了两种编程事务管理方法,方法是使用:
-
或 .
TransactionTemplateTransactionalOperator -
直接实现。
TransactionManager
Spring 团队通常建议将 for programmatic
命令式流中的事务管理以及反应式代码的事务管理。
第二种方法类似于使用 JTA API,但例外
处理不那么麻烦。TransactionTemplateTransactionalOperatorUserTransaction
1.5.1. 使用TransactionTemplate
采用与其他 Spring 模板相同的方法,例如
这。它使用回调方法(使应用程序代码不必
执行样板获取并释放事务资源)并导致
代码是意图驱动的,因为你的代码只关注什么
你想做的。TransactionTemplateJdbcTemplate
正如下面的示例所示,使用 absolute
将您耦合到 Spring 的事务基础设施和 API。无论是否为编程
事务管理是否适合你的开发需求是你的决定
必须自己制作。TransactionTemplate |
必须在事务上下文中运行并显式使用 的应用程序代码类似于下一个示例。您,作为应用程序
开发人员可以编写一个实现(通常表示为
anonymous 内部类),其中包含您需要在
一个交易。然后,您可以将自定义的实例传递给 .以下示例显示了如何执行此操作:TransactionTemplateTransactionCallbackTransactionCallbackexecute(..)TransactionTemplate
public class SimpleService implements Service {
// single TransactionTemplate shared amongst all methods in this instance
private final TransactionTemplate transactionTemplate;
// use constructor-injection to supply the PlatformTransactionManager
public SimpleService(PlatformTransactionManager transactionManager) {
this.transactionTemplate = new TransactionTemplate(transactionManager);
}
public Object someServiceMethod() {
return transactionTemplate.execute(new TransactionCallback() {
// the code in this method runs in a transactional context
public Object doInTransaction(TransactionStatus status) {
updateOperation1();
return resultOfUpdateOperation2();
}
});
}
}// use constructor-injection to supply the PlatformTransactionManager
class SimpleService(transactionManager: PlatformTransactionManager) : Service {
// single TransactionTemplate shared amongst all methods in this instance
private val transactionTemplate = TransactionTemplate(transactionManager)
fun someServiceMethod() = transactionTemplate.execute<Any?> {
updateOperation1()
resultOfUpdateOperation2()
}
}如果没有返回值,可以使用方便的类
替换为匿名类,如下所示:TransactionCallbackWithoutResult
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus status) {
updateOperation1();
updateOperation2();
}
});transactionTemplate.execute(object : TransactionCallbackWithoutResult() {
override fun doInTransactionWithoutResult(status: TransactionStatus) {
updateOperation1()
updateOperation2()
}
})回调中的代码可以通过对提供的对象调用方法回滚事务,如下所示:setRollbackOnly()TransactionStatus
transactionTemplate.execute(new TransactionCallbackWithoutResult() {
protected void doInTransactionWithoutResult(TransactionStatus status) {
try {
updateOperation1();
updateOperation2();
} catch (SomeBusinessException ex) {
status.setRollbackOnly();
}
}
});transactionTemplate.execute(object : TransactionCallbackWithoutResult() {
override fun doInTransactionWithoutResult(status: TransactionStatus) {
try {
updateOperation1()
updateOperation2()
} catch (ex: SomeBusinessException) {
status.setRollbackOnly()
}
}
})指定事务设置
您可以指定事务设置(例如传播模式、隔离级别、
超时,依此类推)在
配置。默认情况下,实例具有默认的事务设置。这
以下示例显示了
一个特定的TransactionTemplateTransactionTemplateTransactionTemplate:
public class SimpleService implements Service {
private final TransactionTemplate transactionTemplate;
public SimpleService(PlatformTransactionManager transactionManager) {
this.transactionTemplate = new TransactionTemplate(transactionManager);
// the transaction settings can be set here explicitly if so desired
this.transactionTemplate.setIsolationLevel(TransactionDefinition.ISOLATION_READ_UNCOMMITTED);
this.transactionTemplate.setTimeout(30); // 30 seconds
// and so forth...
}
}class SimpleService(transactionManager: PlatformTransactionManager) : Service {
private val transactionTemplate = TransactionTemplate(transactionManager).apply {
// the transaction settings can be set here explicitly if so desired
isolationLevel = TransactionDefinition.ISOLATION_READ_UNCOMMITTED
timeout = 30 // 30 seconds
// and so forth...
}
}以下示例定义了具有一些自定义事务的
设置:TransactionTemplate
<bean id="sharedTransactionTemplate"
class="org.springframework.transaction.support.TransactionTemplate">
<property name="isolationLevelName" value="ISOLATION_READ_UNCOMMITTED"/>
<property name="timeout" value="30"/>
</bean>然后,您可以根据需要将 注入到任意数量的服务中。sharedTransactionTemplate
最后,该类的实例是线程安全的,在该实例中
不要保持任何会话状态。 但是,实例确实可以:
维护配置状态。因此,虽然多个类可能共享一个实例
中,如果类需要使用
不同的设置(例如,不同的隔离级别),您需要创建
两个不同的实例。TransactionTemplateTransactionTemplateTransactionTemplateTransactionTemplateTransactionTemplate
1.5.2. 使用TransactionalOperator
遵循类似于其他反应式的运算符设计
运营商。它使用回调方法(使应用程序代码不必执行
样板获取和释放事务资源),并生成代码
意图驱动,因为你的代码只关注你想要做的事情。TransactionalOperator
正如下面的示例所示,使用 absolute
将您耦合到 Spring 的事务基础设施和 API。无论是否为编程
事务管理是否适合你的开发需求是你的决定
使自己。TransactionalOperator |
必须在事务上下文中运行并显式使用
类似于下一个示例:TransactionalOperator
public class SimpleService implements Service {
// single TransactionalOperator shared amongst all methods in this instance
private final TransactionalOperator transactionalOperator;
// use constructor-injection to supply the ReactiveTransactionManager
public SimpleService(ReactiveTransactionManager transactionManager) {
this.transactionalOperator = TransactionalOperator.create(transactionManager);
}
public Mono<Object> someServiceMethod() {
// the code in this method runs in a transactional context
Mono<Object> update = updateOperation1();
return update.then(resultOfUpdateOperation2).as(transactionalOperator::transactional);
}
}// use constructor-injection to supply the ReactiveTransactionManager
class SimpleService(transactionManager: ReactiveTransactionManager) : Service {
// single TransactionalOperator shared amongst all methods in this instance
private val transactionalOperator = TransactionalOperator.create(transactionManager)
suspend fun someServiceMethod() = transactionalOperator.executeAndAwait<Any?> {
updateOperation1()
resultOfUpdateOperation2()
}
}TransactionalOperator可以通过两种方式使用:
-
使用 Project Reactor 类型 (
mono.as(transactionalOperator::transactional)) -
Callback 样式 (
transactionalOperator.execute(TransactionCallback<T>))
回调中的代码可以通过对提供的对象调用方法回滚事务,如下所示:setRollbackOnly()ReactiveTransaction
transactionalOperator.execute(new TransactionCallback<>() {
public Mono<Object> doInTransaction(ReactiveTransaction status) {
return updateOperation1().then(updateOperation2)
.doOnError(SomeBusinessException.class, e -> status.setRollbackOnly());
}
}
});transactionalOperator.execute(object : TransactionCallback() {
override fun doInTransactionWithoutResult(status: ReactiveTransaction) {
updateOperation1().then(updateOperation2)
.doOnError(SomeBusinessException.class, e -> status.setRollbackOnly())
}
})取消信号
在 Reactive Streams 中,a 可以取消 its 并停止其 .Project Reactor 以及其他库中的运算符(如 、 等)可以发出取消。没有办法
了解取消的原因,无论是由于错误还是仅仅缺乏
利息进一步消费。从 5.3 版本开始,取消信号会导致回滚。
因此,重要的是要考虑 transaction 下游使用的运算符 。特别是在 a 或其他多值的情况下,
必须消耗 full output 才能完成事务。SubscriberSubscriptionPublishernext()take(long)timeout(Duration)PublisherFluxPublisher
指定事务设置
您可以指定事务设置(例如传播模式、隔离级别、
超时等)。默认情况下,实例具有默认的事务设置。这
以下示例显示了特定TransactionalOperatorTransactionalOperatorTransactionalOperator:
public class SimpleService implements Service {
private final TransactionalOperator transactionalOperator;
public SimpleService(ReactiveTransactionManager transactionManager) {
DefaultTransactionDefinition definition = new DefaultTransactionDefinition();
// the transaction settings can be set here explicitly if so desired
definition.setIsolationLevel(TransactionDefinition.ISOLATION_READ_UNCOMMITTED);
definition.setTimeout(30); // 30 seconds
// and so forth...
this.transactionalOperator = TransactionalOperator.create(transactionManager, definition);
}
}class SimpleService(transactionManager: ReactiveTransactionManager) : Service {
private val definition = DefaultTransactionDefinition().apply {
// the transaction settings can be set here explicitly if so desired
isolationLevel = TransactionDefinition.ISOLATION_READ_UNCOMMITTED
timeout = 30 // 30 seconds
// and so forth...
}
private val transactionalOperator = TransactionalOperator(transactionManager, definition)
}1.5.3. 使用TransactionManager
以下部分介绍了命令式事务和反应式事务的编程用法 经理。
使用PlatformTransactionManager
对于命令式事务,您可以直接使用 来管理
交易。为此,请将 u 的
通过 Bean 引用将其用于 Bean。然后,通过使用 and 对象,您可以启动事务、回滚和提交。这
以下示例显示了如何执行此操作:org.springframework.transaction.PlatformTransactionManagerPlatformTransactionManagerTransactionDefinitionTransactionStatus
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
// explicitly setting the transaction name is something that can be done only programmatically
def.setName("SomeTxName");
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
TransactionStatus status = txManager.getTransaction(def);
try {
// put your business logic here
} catch (MyException ex) {
txManager.rollback(status);
throw ex;
}
txManager.commit(status);val def = DefaultTransactionDefinition()
// explicitly setting the transaction name is something that can be done only programmatically
def.setName("SomeTxName")
def.propagationBehavior = TransactionDefinition.PROPAGATION_REQUIRED
val status = txManager.getTransaction(def)
try {
// put your business logic here
} catch (ex: MyException) {
txManager.rollback(status)
throw ex
}
txManager.commit(status)使用ReactiveTransactionManager
在处理响应式事务时,您可以直接使用 a 来管理
交易。为此,请将 u 的
通过 Bean 引用将其用于 Bean。然后,通过使用 and 对象,您可以启动事务、回滚和提交。这
以下示例显示了如何执行此操作:org.springframework.transaction.ReactiveTransactionManagerReactiveTransactionManagerTransactionDefinitionReactiveTransaction
DefaultTransactionDefinition def = new DefaultTransactionDefinition();
// explicitly setting the transaction name is something that can be done only programmatically
def.setName("SomeTxName");
def.setPropagationBehavior(TransactionDefinition.PROPAGATION_REQUIRED);
Mono<ReactiveTransaction> reactiveTx = txManager.getReactiveTransaction(def);
reactiveTx.flatMap(status -> {
Mono<Object> tx = ...; // put your business logic here
return tx.then(txManager.commit(status))
.onErrorResume(ex -> txManager.rollback(status).then(Mono.error(ex)));
});val def = DefaultTransactionDefinition()
// explicitly setting the transaction name is something that can be done only programmatically
def.setName("SomeTxName")
def.propagationBehavior = TransactionDefinition.PROPAGATION_REQUIRED
val reactiveTx = txManager.getReactiveTransaction(def)
reactiveTx.flatMap { status ->
val tx = ... // put your business logic here
tx.then(txManager.commit(status))
.onErrorResume { ex -> txManager.rollback(status).then(Mono.error(ex)) }
}1.6. 在编程和声明式事务管理之间进行选择
程序化事务管理通常是一个好主意,前提是您有一个较小的
事务操作数。例如,如果您有一个 Web 应用程序
仅对某些更新操作需要事务,您可能不想设置
使用 Spring 或任何其他技术的交易代理。在这种情况下,使用 可能是一种很好的方法。能够设置交易名称
explicitly 也只能通过使用编程方法来完成
到事务管理。TransactionTemplate
另一方面,如果您的应用程序具有大量事务操作, 声明式事务管理通常是值得的。它保持事务 管理脱离业务逻辑,配置起来并不难。使用 Spring Framework,而不是 EJB CMT,声明式事务的配置成本 管理工作大大减少。
1.7. 事务绑定事件
从 Spring 4.2 开始,事件的侦听器可以绑定到事务的某个阶段。 典型的示例是在事务成功完成时处理事件。 这样做可以更灵活地使用事件,当当前 transaction 实际上对侦听器很重要。
您可以使用注释注册常规事件侦听器。
如果需要将其绑定到事务,请使用 .
执行此操作时,默认情况下,侦听器将绑定到事务的提交阶段。@EventListener@TransactionalEventListener
下一个示例显示了这个概念。假设组件发布 order-created 事件,并且我们想要定义一个侦听器,该侦听器应该只处理该事件一次 已成功提交已发布的事务。以下内容 example 设置这样的事件侦听器:
@Component
public class MyComponent {
@TransactionalEventListener
public void handleOrderCreatedEvent(CreationEvent<Order> creationEvent) {
// ...
}
}@Component
class MyComponent {
@TransactionalEventListener
fun handleOrderCreatedEvent(creationEvent: CreationEvent<Order>) {
// ...
}
}该注解公开了一个属性,该属性允许您
自定义侦听器应绑定到的事务阶段。
有效阶段是 , (default), 以及聚合事务完成(无论是提交还是回滚)。@TransactionalEventListenerphaseBEFORE_COMMITAFTER_COMMITAFTER_ROLLBACKAFTER_COMPLETION
如果没有事务正在运行,则根本不会调用侦听器,因为我们无法遵循
必需的语义。但是,您可以通过将 Comments 的属性设置为 来覆盖该行为。fallbackExecutiontrue
|
|
1.8. 特定于应用程序服务器的集成
Spring 的事务抽象通常是与应用程序服务器无关的。此外
Spring 的类(可以选择对
JTA 和对象)会自动检测
后者对象,因 Application Server 而异。访问 JTA 可以增强事务语义 — 特别是
支持交易暂停。有关详细信息,请参见JtaTransactionManager javadoc。JtaTransactionManagerUserTransactionTransactionManagerTransactionManager
Spring 的是在 Java EE 应用程序上运行的标准选择
servers 的 S S 的 S S Var S 的 S T高级功能,例如
事务暂停,也适用于许多服务器(包括 GlassFish、JBoss 和
Geronimo) 的 Git。但是,对于完全支持
事务暂停和进一步的高级集成,Spring 包括特殊的适配器
用于 WebLogic Server 和 WebSphere。下面将讨论这些适配器
部分。JtaTransactionManager
对于标准场景,包括 WebLogic Server 和 WebSphere,请考虑使用
方便的配置元素。配置后,
此元素会自动检测底层服务器并选择最佳服务器
可用于平台的事务管理器。这意味着您不需要明确地
配置特定于服务器的适配器类(如以下各节所述)。
相反,它们是自动选择的,标准作为默认回退。<tx:jta-transaction-manager/>JtaTransactionManager
1.9. 常见问题
本节介绍一些常见问题的解决方案。
1.9.1. 对特定的DataSource
根据您选择的
事务技术和要求。如果使用得当,Spring Framework 只是
提供了一个简单且可移植的抽象。如果使用 global
transactions 中,您必须使用类(或特定于 Application Server 的
it) 进行所有事务性操作。否则,事务基础结构
尝试对容器实例等资源执行本地事务。这样的本地事务没有意义,一个好的应用程序服务器
将它们视为错误。PlatformTransactionManagerorg.springframework.transaction.jta.JtaTransactionManagerDataSource
1.10. 更多资源
有关 Spring Framework 的事务支持的更多信息,请参阅:
-
分散式 Spring 中的事务(带 XA 和不带 XA)是一个 JavaWorld 表示,其中 Spring 的 David Syer 将指导您了解分布式的 7 种模式 Spring 应用程序中的事务,其中 3 个使用 XA,4 个没有。
-
Java Transaction Design Strategies 是一本书 可从 InfoQ 获得,它提供了一个节奏良好的介绍 到 Java 中的事务。它还包括有关如何配置的并排示例 并将事务与 Spring Framework 和 EJB3 一起使用。
2. DAO 支持
Spring 中的数据访问对象 (DAO) 支持旨在使其易于使用 数据访问技术(如 JDBC、Hibernate 或 JPA)以一致的方式。这 让你相当容易地在上述持久化技术之间切换, 它还允许您编写代码,而无需担心捕获 特定于每种技术。
2.1. 一致的异常层次结构
Spring 提供了从特定于技术的异常(例如到其自己的异常类层次结构)的便捷转换,该层次结构具有
root 异常。这些异常包装了原始异常,因此永远不会有
您可能会丢失有关可能出错的任何信息的任何风险。SQLExceptionDataAccessException
除了 JDBC 异常之外, Spring 还可以包装特定于 JPA 和 Hibernate 的异常。 将它们转换为一组 Focused Runtime 异常。这让你处理大多数 不可恢复的持久性异常,而没有 DAO 中烦人的样板捕获和抛出块和异常声明。 (不过,您仍然可以在需要的任何位置捕获和处理异常。如上所述, JDBC 异常(包括特定于数据库的方言)也会转换为相同的 层次结构,这意味着您可以在一致的 编程模型。
前面的讨论适用于 Spring 支持中的各种模板类
适用于各种 ORM 框架。如果使用基于侦听器的类,则应用程序必须
关心处理和自身,最好由
分别委托给 的 或 方法。这些方法将异常
添加到与 Exception 层次结构中的异常兼容的 Exception。如果不加以控制,它们也可能被抛出
(不过,在例外方面牺牲了通用的 DAO 抽象)。HibernateExceptionsPersistenceExceptionsconvertHibernateAccessException(..)convertJpaAccessException(..)SessionFactoryUtilsorg.springframework.daoPersistenceExceptions
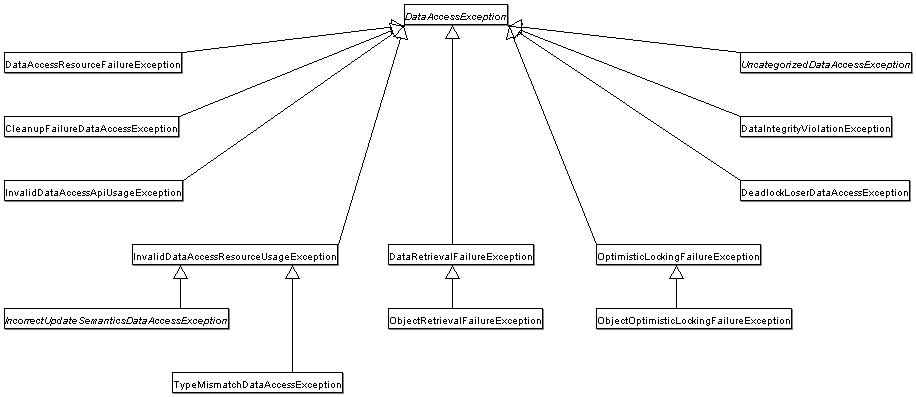
下图显示了 Spring 提供的异常层次结构。
(请注意,图中详述的类层次结构仅显示整个层次结构的一个子集。DataAccessException
2.2. 用于配置 DAO 或存储库类的注解
保证您的数据访问对象 (DAO) 或存储库提供
exception translation 是使用 annotation。此注释还
让组件扫描支持人员查找和配置您的 DAO 和存储库
而无需为它们提供 XML 配置条目。以下示例显示了
如何使用注释:@Repository@Repository
@Repository (1)
public class SomeMovieFinder implements MovieFinder {
// ...
}| 1 | 注释。@Repository |
@Repository (1)
class SomeMovieFinder : MovieFinder {
// ...
}| 1 | 注释。@Repository |
任何 DAO 或存储库实现都需要访问持久化资源,
取决于使用的持久性技术。例如,基于 JDBC 的存储库
需要访问 JDBC ,而基于 JPA 的存储库需要访问 .实现此目的的最简单方法是具有此资源依赖项
使用 、 或 注释之一注入。以下示例适用于 JPA 存储库:DataSourceEntityManager@Autowired@Inject@Resource@PersistenceContext
@Repository
public class JpaMovieFinder implements MovieFinder {
@PersistenceContext
private EntityManager entityManager;
// ...
}@Repository
class JpaMovieFinder : MovieFinder {
@PersistenceContext
private lateinit var entityManager: EntityManager
// ...
}如果使用经典的 Hibernate API,则可以注入 ,如下所示
示例显示:SessionFactory
@Repository
public class HibernateMovieFinder implements MovieFinder {
private SessionFactory sessionFactory;
@Autowired
public void setSessionFactory(SessionFactory sessionFactory) {
this.sessionFactory = sessionFactory;
}
// ...
}@Repository
class HibernateMovieFinder(private val sessionFactory: SessionFactory) : MovieFinder {
// ...
}我们在这里展示的最后一个示例是典型的 JDBC 支持。您可以将 注入到初始化方法或构造函数中,在那里您将使用此 .以下示例自动装配 :DataSourceJdbcTemplateSimpleJdbcCallDataSourceDataSource
@Repository
public class JdbcMovieFinder implements MovieFinder {
private JdbcTemplate jdbcTemplate;
@Autowired
public void init(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
// ...
}@Repository
class JdbcMovieFinder(dataSource: DataSource) : MovieFinder {
private val jdbcTemplate = JdbcTemplate(dataSource)
// ...
}| 有关如何执行以下操作的详细信息,请参阅每种持久化技术的具体覆盖范围 配置 Application Context 以利用这些注释。 |
3. 使用 JDBC 进行数据访问
Spring 框架 JDBC 抽象提供的值可能最好地由 下表中概述了操作顺序。该表显示了 Spring 的操作 负责以及哪些操作是您的责任。
| 行动 | Spring | 你 |
|---|---|---|
定义连接参数。 |
X |
|
打开连接。 |
X |
|
指定 SQL 语句。 |
X |
|
声明参数并提供参数值 |
X |
|
准备并运行该语句。 |
X |
|
设置循环以迭代结果(如果有)。 |
X |
|
为每次迭代执行工作。 |
X |
|
处理任何异常。 |
X |
|
处理交易。 |
X |
|
关闭连接、语句和 resultset。 |
X |
Spring 框架处理了所有低级细节,这些细节可以使 JDBC 成为 乏味的 API。
3.1. 选择 JDBC 数据库访问方法
您可以在多种方法中进行选择,以构成 JDBC 数据库访问的基础。
除了三种风格的 之外,一种新的 and 方法优化了数据库元数据,而 RDBMS 对象样式则采用
更面向对象的方法,类似于 JDO Query 设计。开始使用
其中一种方法,您仍然可以混合和匹配以包含
不同的方法。所有方法都需要符合 JDBC 2.0 的驱动程序,并且某些
高级功能需要 JDBC 3.0 驱动程序。JdbcTemplateSimpleJdbcInsertSimpleJdbcCall
-
JdbcTemplate是经典且最流行的 Spring JDBC 方法。这 “最低级别”方法和所有其他方法在幕后都使用JdbcTemplate。 -
NamedParameterJdbcTemplate包装 a 以提供命名参数 而不是传统的 JDBC 占位符。这种方法提供了更好的 文档和易用性(当您的 SQL 语句有多个参数时)。JdbcTemplate? -
SimpleJdbcInsert并优化数据库元数据以限制数量 的必要配置。此方法简化了编码,因此您需要 仅提供表或过程的名称,并提供匹配的参数映射 列名。仅当数据库提供足够的元数据时,这才有效。如果 数据库不提供此元数据,您必须提供显式的 参数的配置。SimpleJdbcCall -
RDBMS 对象 — 包括 、 和 — 要求您在初始化 data-access 层。此方法以 JDO 查询为模型,其中定义 query string、declare parameters 并编译查询。一旦你这样做了, , 和 方法可以被调用多个 时间。
MappingSqlQuerySqlUpdateStoredProcedureexecute(…)update(…)findObject(…)
3.2. 包层次结构
Spring 框架的 JDBC 抽象框架由四个不同的包组成:
-
core:包包含类 及其各种回调接口,以及各种相关类。A 分包 named 包含 和 类。另一个名为 的子包包含该类和相关的支持类。请参阅使用 JDBC 核心类控制基本的 JDBC 处理和错误处理、JDBC 批处理操作和使用SimpleJdbc类简化 JDBC 操作。org.springframework.jdbc.coreJdbcTemplateorg.springframework.jdbc.core.simpleSimpleJdbcInsertSimpleJdbcCallorg.springframework.jdbc.core.namedparamNamedParameterJdbcTemplate -
datasource:包包含一个实用程序类 为了方便访问和各种简单的实现,您可以 用于在 Java EE 容器外部测试和运行未修改的 JDBC 代码。A 分包 named 支持创建 使用 Java 数据库引擎(如 HSQL、H2 和 Derby)的嵌入式数据库。请参阅控制数据库连接和嵌入式数据库支持。org.springframework.jdbc.datasourceDataSourceDataSourceorg.springframework.jdbc.datasource.embedded -
object:该包包含表示 RDBMS 查询、更新和存储过程作为线程安全、可重用的对象。请参阅将 JDBC 操作建模为 Java 对象。此方法由 JDO 建模,尽管查询返回的对象 自然会与数据库断开连接。这个更高级别的 JDBC 抽象 取决于 package 中的较低级别抽象。org.springframework.jdbc.objectorg.springframework.jdbc.core -
support:该包提供翻译功能和一些实用程序类。JDBC 处理期间引发的异常 转换为包中定义的异常。这意味着 使用 Spring JDBC 抽象层的代码不需要实现 JDBC 或 特定于 RDBMS 的错误处理。所有已翻译的异常都是未选中的,这会为您提供 捕获异常的选项,您可以从中恢复,同时让其他 异常传播到调用方。请参阅使用SQLExceptionTranslator。org.springframework.jdbc.supportSQLExceptionorg.springframework.dao
3.3. 使用 JDBC 核心类控制基本的 JDBC 处理和错误处理
本节介绍如何使用 JDBC 核心类来控制基本的 JDBC 处理。 包括错误处理。它包括以下主题:
3.3.1. 使用JdbcTemplate
JdbcTemplate是 JDBC 核心包中的中心类。它处理
创建和释放资源,这有助于您避免常见错误,例如
忘记关闭连接。它执行核心 JDBC 的基本任务
工作流(例如语句创建和执行),让应用程序代码提供
SQL 并提取结果。类:JdbcTemplate
-
运行 SQL 查询
-
更新语句和存储过程调用
-
对实例执行迭代并提取返回的参数值。
ResultSet -
捕获 JDBC 异常并将它们转换为泛型、信息量更大的异常 hierarchy 中定义的 Hierarchy。(请参阅一致的异常层次结构。
org.springframework.dao
当您使用 for your code 时,您只需实现 callback
接口,为它们提供明确定义的 Contract。给定类提供的 a 后,回调接口会创建一个准备好的
语句,提供 SQL 和任何必要的参数。这同样适用于创建可调用语句的接口。该接口从 .JdbcTemplateConnectionJdbcTemplatePreparedStatementCreatorCallableStatementCreatorRowCallbackHandlerResultSet
您可以通过直接实例化在 DAO 实现中使用
替换为引用,或者您可以在 Spring IoC 容器中配置它并将其提供给
DAO 作为 bean 引用。JdbcTemplateDataSource
应该始终在 Spring IoC 容器中配置为 bean。在
第一种情况是将 bean 直接提供给服务;在第二种情况下,它给出了
添加到准备好的模板中。DataSource |
此类发出的所有 SQL 都记录在类别
对应于 Template 实例的完全限定类名(通常为 ,但如果您使用类的自定义子类,则可能会有所不同)。DEBUGJdbcTemplateJdbcTemplate
以下部分提供了一些用法示例。这些例子
并不是 .
有关此内容,请参阅随附的 javadoc。JdbcTemplateJdbcTemplate
查询 (SELECT)
以下查询获取关系中的行数:
int rowCount = this.jdbcTemplate.queryForObject("select count(*) from t_actor", Integer.class);val rowCount = jdbcTemplate.queryForObject<Int>("select count(*) from t_actor")!!以下查询使用 bind 变量:
int countOfActorsNamedJoe = this.jdbcTemplate.queryForObject(
"select count(*) from t_actor where first_name = ?", Integer.class, "Joe");val countOfActorsNamedJoe = jdbcTemplate.queryForObject<Int>(
"select count(*) from t_actor where first_name = ?", arrayOf("Joe"))!!以下查询查找 :String
String lastName = this.jdbcTemplate.queryForObject(
"select last_name from t_actor where id = ?",
String.class, 1212L);val lastName = this.jdbcTemplate.queryForObject<String>(
"select last_name from t_actor where id = ?",
arrayOf(1212L))!!以下查询查找并填充单个域对象:
Actor actor = jdbcTemplate.queryForObject(
"select first_name, last_name from t_actor where id = ?",
(resultSet, rowNum) -> {
Actor newActor = new Actor();
newActor.setFirstName(resultSet.getString("first_name"));
newActor.setLastName(resultSet.getString("last_name"));
return newActor;
},
1212L);val actor = jdbcTemplate.queryForObject(
"select first_name, last_name from t_actor where id = ?",
arrayOf(1212L)) { rs, _ ->
Actor(rs.getString("first_name"), rs.getString("last_name"))
}以下查询查找并填充域对象列表:
List<Actor> actors = this.jdbcTemplate.query(
"select first_name, last_name from t_actor",
(resultSet, rowNum) -> {
Actor actor = new Actor();
actor.setFirstName(resultSet.getString("first_name"));
actor.setLastName(resultSet.getString("last_name"));
return actor;
});val actors = jdbcTemplate.query("select first_name, last_name from t_actor") { rs, _ ->
Actor(rs.getString("first_name"), rs.getString("last_name"))如果最后两个代码片段实际存在于同一个应用程序中,那么它将使
sense 删除两个 lambda 表达式中存在的重复项,使用 sense
将它们提取到一个字段中,然后 DAO 方法可以根据需要引用该字段。
例如,最好按如下方式编写前面的代码片段:RowMapper
private final RowMapper<Actor> actorRowMapper = (resultSet, rowNum) -> {
Actor actor = new Actor();
actor.setFirstName(resultSet.getString("first_name"));
actor.setLastName(resultSet.getString("last_name"));
return actor;
};
public List<Actor> findAllActors() {
return this.jdbcTemplate.query("select first_name, last_name from t_actor", actorRowMapper);
}val actorMapper = RowMapper<Actor> { rs: ResultSet, rowNum: Int ->
Actor(rs.getString("first_name"), rs.getString("last_name"))
}
fun findAllActors(): List<Actor> {
return jdbcTemplate.query("select first_name, last_name from t_actor", actorMapper)
}更新 (, , 和 )INSERTUPDATEDELETEJdbcTemplate
您可以使用该方法执行插入、更新和删除操作。
参数值通常作为变量参数提供,或者作为对象数组提供。update(..)
以下示例插入一个新条目:
this.jdbcTemplate.update(
"insert into t_actor (first_name, last_name) values (?, ?)",
"Leonor", "Watling");jdbcTemplate.update(
"insert into t_actor (first_name, last_name) values (?, ?)",
"Leonor", "Watling")以下示例更新现有条目:
this.jdbcTemplate.update(
"update t_actor set last_name = ? where id = ?",
"Banjo", 5276L);jdbcTemplate.update(
"update t_actor set last_name = ? where id = ?",
"Banjo", 5276L)以下示例删除条目:
this.jdbcTemplate.update(
"delete from t_actor where id = ?",
Long.valueOf(actorId));jdbcTemplate.update("delete from t_actor where id = ?", actorId.toLong())其他操作JdbcTemplate
您可以使用该方法运行任意 SQL。因此,
method 通常用于 DDL 语句。它严重过载了采用
回调接口、绑定变量数组等。以下示例创建一个
桌子:execute(..)
this.jdbcTemplate.execute("create table mytable (id integer, name varchar(100))");jdbcTemplate.execute("create table mytable (id integer, name varchar(100))")以下示例调用存储过程:
this.jdbcTemplate.update(
"call SUPPORT.REFRESH_ACTORS_SUMMARY(?)",
Long.valueOf(unionId));jdbcTemplate.update(
"call SUPPORT.REFRESH_ACTORS_SUMMARY(?)",
unionId.toLong())稍后将介绍更复杂的存储过程支持。
JdbcTemplate最佳实践
类的实例一旦配置,就是线程安全的。这是
重要,因为这意味着您可以配置单个实例,然后将此共享引用安全地注入多个 DAO(或存储库)。
这是有状态的,因为它维护对 的引用 ,但
此状态不是对话状态。JdbcTemplateJdbcTemplateJdbcTemplateDataSource
使用该类(以及关联的 NamedParameterJdbcTemplate 类)时的常见做法是
在 Spring 配置文件中配置 a,然后 dependency-inject
将 bean 共享到您的 DAO 类中。在
.这导致了类似于以下内容的 DAO:JdbcTemplateDataSourceDataSourceJdbcTemplateDataSource
public class JdbcCorporateEventDao implements CorporateEventDao {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
// JDBC-backed implementations of the methods on the CorporateEventDao follow...
}class JdbcCorporateEventDao(dataSource: DataSource) : CorporateEventDao {
private val jdbcTemplate = JdbcTemplate(dataSource)
// JDBC-backed implementations of the methods on the CorporateEventDao follow...
}以下示例显示了相应的 XML 配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd">
<bean id="corporateEventDao" class="com.example.JdbcCorporateEventDao">
<property name="dataSource" ref="dataSource"/>
</bean>
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="${jdbc.driverClassName}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
<context:property-placeholder location="jdbc.properties"/>
</beans>显式配置的替代方法是使用组件扫描和注释
支持依赖项注入。在这种情况下,你可以用 (这使它成为组件扫描的候选者) 来注释类,并 注释 setter
方法与 .以下示例显示了如何执行此操作:@RepositoryDataSource@Autowired
@Repository (1)
public class JdbcCorporateEventDao implements CorporateEventDao {
private JdbcTemplate jdbcTemplate;
@Autowired (2)
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource); (3)
}
// JDBC-backed implementations of the methods on the CorporateEventDao follow...
}| 1 | 用 .@Repository |
| 2 | 使用 .DataSource@Autowired |
| 3 | 使用 创建新的 .JdbcTemplateDataSource |
@Repository (1)
class JdbcCorporateEventDao(dataSource: DataSource) : CorporateEventDao { (2)
private val jdbcTemplate = JdbcTemplate(dataSource) (3)
// JDBC-backed implementations of the methods on the CorporateEventDao follow...
}| 1 | 用 .@Repository |
| 2 | 构造函数注入 .DataSource |
| 3 | 使用 创建新的 .JdbcTemplateDataSource |
以下示例显示了相应的 XML 配置:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
https://www.springframework.org/schema/context/spring-context.xsd">
<!-- Scans within the base package of the application for @Component classes to configure as beans -->
<context:component-scan base-package="org.springframework.docs.test" />
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="${jdbc.driverClassName}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
<context:property-placeholder location="jdbc.properties"/>
</beans>如果你使用 Spring 的类和各种 JDBC 支持的 DAO 类
extend 的子类会从该类继承一个 method。您可以选择是否从此类继承。该类仅为方便起见而提供。JdbcDaoSupportsetDataSource(..)JdbcDaoSupportJdbcDaoSupport
无论您选择使用上述哪种模板初始化样式(或
not),则很少需要为每个
运行时间。配置后,实例是线程安全的。
如果您的应用程序访问多个
databases 中,您可能需要多个实例,这需要多个实例,然后需要多个不同的实例
配置的实例。JdbcTemplateJdbcTemplateJdbcTemplateDataSourcesJdbcTemplate
3.3.2. 使用NamedParameterJdbcTemplate
该类添加了对 JDBC 语句编程的支持
通过使用命名参数,而不是仅使用经典
placeholder ( ) 参数。该类包装 a 并委托 wraps 完成其大部分工作。这
部分仅描述类中不同的区域
从自身 — 即使用 named 对 JDBC 语句进行编程
参数。以下示例演示如何使用:NamedParameterJdbcTemplate'?'NamedParameterJdbcTemplateJdbcTemplateJdbcTemplateNamedParameterJdbcTemplateJdbcTemplateNamedParameterJdbcTemplate
// some JDBC-backed DAO class...
private NamedParameterJdbcTemplate namedParameterJdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.namedParameterJdbcTemplate = new NamedParameterJdbcTemplate(dataSource);
}
public int countOfActorsByFirstName(String firstName) {
String sql = "select count(*) from t_actor where first_name = :first_name";
SqlParameterSource namedParameters = new MapSqlParameterSource("first_name", firstName);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class);
}private val namedParameterJdbcTemplate = NamedParameterJdbcTemplate(dataSource)
fun countOfActorsByFirstName(firstName: String): Int {
val sql = "select count(*) from t_actor where first_name = :first_name"
val namedParameters = MapSqlParameterSource("first_name", firstName)
return namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Int::class.java)!!
}请注意,在分配给变量的值中使用了命名参数表示法,以及插入变量(类型 )的相应值。sqlnamedParametersMapSqlParameterSource
或者,您也可以使用基于 的样式将命名参数及其相应的值传递给实例。剩余的
由 暴露 和 由类实现的方法遵循类似的模式,此处不作介绍。NamedParameterJdbcTemplateMapNamedParameterJdbcOperationsNamedParameterJdbcTemplate
以下示例显示了基于 -的样式的用法:Map
// some JDBC-backed DAO class...
private NamedParameterJdbcTemplate namedParameterJdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.namedParameterJdbcTemplate = new NamedParameterJdbcTemplate(dataSource);
}
public int countOfActorsByFirstName(String firstName) {
String sql = "select count(*) from t_actor where first_name = :first_name";
Map<String, String> namedParameters = Collections.singletonMap("first_name", firstName);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class);
}// some JDBC-backed DAO class...
private val namedParameterJdbcTemplate = NamedParameterJdbcTemplate(dataSource)
fun countOfActorsByFirstName(firstName: String): Int {
val sql = "select count(*) from t_actor where first_name = :first_name"
val namedParameters = mapOf("first_name" to firstName)
return namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Int::class.java)!!
}一个与 相关的不错的功能(并且存在于相同的
Java 包)是接口。您已经看到了一个
在前面的代码片段之一(类)中实现此接口。An 是命名参数的源
值设置为 .该类是一个
简单的实现,它是围绕 的适配器,其中键
是参数名称,值是参数值。NamedParameterJdbcTemplateSqlParameterSourceMapSqlParameterSourceSqlParameterSourceNamedParameterJdbcTemplateMapSqlParameterSourcejava.util.Map
另一个实现是 class.此类包装一个任意 JavaBean(即
遵守
JavaBean 约定),并使用包装的 JavaBean 的属性作为源
的命名参数值。SqlParameterSourceBeanPropertySqlParameterSource
以下示例显示了一个典型的 JavaBean:
public class Actor {
private Long id;
private String firstName;
private String lastName;
public String getFirstName() {
return this.firstName;
}
public String getLastName() {
return this.lastName;
}
public Long getId() {
return this.id;
}
// setters omitted...
}data class Actor(val id: Long, val firstName: String, val lastName: String)以下示例使用 a 返回
上例所示的类的成员:NamedParameterJdbcTemplate
// some JDBC-backed DAO class...
private NamedParameterJdbcTemplate namedParameterJdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.namedParameterJdbcTemplate = new NamedParameterJdbcTemplate(dataSource);
}
public int countOfActors(Actor exampleActor) {
// notice how the named parameters match the properties of the above 'Actor' class
String sql = "select count(*) from t_actor where first_name = :firstName and last_name = :lastName";
SqlParameterSource namedParameters = new BeanPropertySqlParameterSource(exampleActor);
return this.namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Integer.class);
}// some JDBC-backed DAO class...
private val namedParameterJdbcTemplate = NamedParameterJdbcTemplate(dataSource)
private val namedParameterJdbcTemplate = NamedParameterJdbcTemplate(dataSource)
fun countOfActors(exampleActor: Actor): Int {
// notice how the named parameters match the properties of the above 'Actor' class
val sql = "select count(*) from t_actor where first_name = :firstName and last_name = :lastName"
val namedParameters = BeanPropertySqlParameterSource(exampleActor)
return namedParameterJdbcTemplate.queryForObject(sql, namedParameters, Int::class.java)!!
}请记住,该类包装了一个经典模板。如果您需要访问包装的实例以访问
功能,则可以使用该方法通过接口访问 Wrapped。NamedParameterJdbcTemplateJdbcTemplateJdbcTemplateJdbcTemplategetJdbcOperations()JdbcTemplateJdbcOperations
另请参见JdbcTemplate最佳实践,以获取有关在应用程序上下文中使用该类的指南。NamedParameterJdbcTemplate
3.3.3. 使用SQLExceptionTranslator
SQLExceptionTranslator是由可以翻译的类实现的接口
在 s 和 Spring 自己的 ,
这在数据访问策略方面是不可知的。实现可以是通用的(对于
示例,使用 JDBC 的 SQLState 代码)或专有代码(例如,使用 Oracle 错误
代码)以获得更高的精度。此异常转换机制在
公共点和入口点
propagate 而不是 。SQLExceptionorg.springframework.dao.DataAccessExceptionJdbcTemplateJdbcTransactionManagerSQLExceptionDataAccessException
SQLErrorCodeSQLExceptionTranslator是默认使用的 that 的实现。此实施使用特定的供应商代码。它不止于
精确于实施。错误代码翻译基于
保存在名为 的 JavaBean 类型类中的代码。这个类被创建并
由 填充 ,它(顾名思义)是
根据名为 的配置文件的内容创建 。此文件填充了供应商代码,并基于从 .实际代码
数据库。SQLExceptionTranslatorSQLStateSQLErrorCodesSQLErrorCodesFactorySQLErrorCodessql-error-codes.xmlDatabaseProductNameDatabaseMetaData
按以下顺序应用匹配规则:SQLErrorCodeSQLExceptionTranslator
-
由子类实现的任何自定义翻译。通常,使用提供的混凝土,因此此规则不适用。它 仅当您实际提供了 subclass 实现时适用。
SQLErrorCodeSQLExceptionTranslator -
提供的接口的任何自定义实现 作为类的属性。
SQLExceptionTranslatorcustomSqlExceptionTranslatorSQLErrorCodes -
搜索类的实例列表(为类的属性提供)以查找匹配项。
CustomSQLErrorCodesTranslationcustomTranslationsSQLErrorCodes -
应用错误代码匹配。
-
使用回退转换器。 是默认回退 在线翻译。如果此翻译不可用,则下一个回退翻译器为 这。
SQLExceptionSubclassTranslatorSQLStateSQLExceptionTranslator
默认情况下,用于定义错误代码和自定义
异常翻译。它们在名为
classpath 的 URL,并且匹配的实例基于数据库进行定位
name 来自正在使用的数据库的数据库元数据。SQLErrorCodesFactorysql-error-codes.xmlSQLErrorCodes |
您可以扩展 ,如下例所示:SQLErrorCodeSQLExceptionTranslator
public class CustomSQLErrorCodesTranslator extends SQLErrorCodeSQLExceptionTranslator {
protected DataAccessException customTranslate(String task, String sql, SQLException sqlEx) {
if (sqlEx.getErrorCode() == -12345) {
return new DeadlockLoserDataAccessException(task, sqlEx);
}
return null;
}
}class CustomSQLErrorCodesTranslator : SQLErrorCodeSQLExceptionTranslator() {
override fun customTranslate(task: String, sql: String?, sqlEx: SQLException): DataAccessException? {
if (sqlEx.errorCode == -12345) {
return DeadlockLoserDataAccessException(task, sqlEx)
}
return null
}
}在前面的示例中,特定的错误代码 () 被转换,而
其他错误留给 default translator 实现进行转换。
要使用此自定义转换器,您必须通过
方法,并且必须对所有
需要此转换器的数据访问处理。以下示例显示了
如何使用此自定义转换器:-12345JdbcTemplatesetExceptionTranslatorJdbcTemplate
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
// create a JdbcTemplate and set data source
this.jdbcTemplate = new JdbcTemplate();
this.jdbcTemplate.setDataSource(dataSource);
// create a custom translator and set the DataSource for the default translation lookup
CustomSQLErrorCodesTranslator tr = new CustomSQLErrorCodesTranslator();
tr.setDataSource(dataSource);
this.jdbcTemplate.setExceptionTranslator(tr);
}
public void updateShippingCharge(long orderId, long pct) {
// use the prepared JdbcTemplate for this update
this.jdbcTemplate.update("update orders" +
" set shipping_charge = shipping_charge * ? / 100" +
" where id = ?", pct, orderId);
}// create a JdbcTemplate and set data source
private val jdbcTemplate = JdbcTemplate(dataSource).apply {
// create a custom translator and set the DataSource for the default translation lookup
exceptionTranslator = CustomSQLErrorCodesTranslator().apply {
this.dataSource = dataSource
}
}
fun updateShippingCharge(orderId: Long, pct: Long) {
// use the prepared JdbcTemplate for this update
this.jdbcTemplate!!.update("update orders" +
" set shipping_charge = shipping_charge * ? / 100" +
" where id = ?", pct, orderId)
}向自定义转换器传递数据源,以便在 中查找错误代码。sql-error-codes.xml
3.3.4. Running 语句
运行 SQL 语句需要的代码非常少。您需要 a 和 a ,包括随 .以下示例显示了您需要为最小但
完全功能类来创建新表:DataSourceJdbcTemplateJdbcTemplate
import javax.sql.DataSource;
import org.springframework.jdbc.core.JdbcTemplate;
public class ExecuteAStatement {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public void doExecute() {
this.jdbcTemplate.execute("create table mytable (id integer, name varchar(100))");
}
}import javax.sql.DataSource
import org.springframework.jdbc.core.JdbcTemplate
class ExecuteAStatement(dataSource: DataSource) {
private val jdbcTemplate = JdbcTemplate(dataSource)
fun doExecute() {
jdbcTemplate.execute("create table mytable (id integer, name varchar(100))")
}
}3.3.5. 运行查询
某些查询方法返回单个值。从
一行,请使用 .后者将返回的 JDBC 转换为
作为参数传入的 Java 类。如果类型转换无效,则引发 an。以下示例包含两个
query 方法,一个用于 an,一个用于查询 a:queryForObject(..)TypeInvalidDataAccessApiUsageExceptionintString
import javax.sql.DataSource;
import org.springframework.jdbc.core.JdbcTemplate;
public class RunAQuery {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public int getCount() {
return this.jdbcTemplate.queryForObject("select count(*) from mytable", Integer.class);
}
public String getName() {
return this.jdbcTemplate.queryForObject("select name from mytable", String.class);
}
}import javax.sql.DataSource
import org.springframework.jdbc.core.JdbcTemplate
class RunAQuery(dataSource: DataSource) {
private val jdbcTemplate = JdbcTemplate(dataSource)
val count: Int
get() = jdbcTemplate.queryForObject("select count(*) from mytable")!!
val name: String?
get() = jdbcTemplate.queryForObject("select name from mytable")
}除了单个结果查询方法之外,还有几个方法返回一个带有
条目。最通用的方法是 ,
,它返回一个 where each element is a 包含每列的一个条目,
使用列名作为键。如果向前面的示例添加方法以检索
列表中,它可能如下所示:queryForList(..)ListMap
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public List<Map<String, Object>> getList() {
return this.jdbcTemplate.queryForList("select * from mytable");
}private val jdbcTemplate = JdbcTemplate(dataSource)
fun getList(): List<Map<String, Any>> {
return jdbcTemplate.queryForList("select * from mytable")
}返回的列表将类似于以下内容:
[{name=Bob, id=1}, {name=Mary, id=2}]
3.3.6. 更新数据库
以下示例更新某个主键的列:
import javax.sql.DataSource;
import org.springframework.jdbc.core.JdbcTemplate;
public class ExecuteAnUpdate {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public void setName(int id, String name) {
this.jdbcTemplate.update("update mytable set name = ? where id = ?", name, id);
}
}import javax.sql.DataSource
import org.springframework.jdbc.core.JdbcTemplate
class ExecuteAnUpdate(dataSource: DataSource) {
private val jdbcTemplate = JdbcTemplate(dataSource)
fun setName(id: Int, name: String) {
jdbcTemplate.update("update mytable set name = ? where id = ?", name, id)
}
}在前面的示例中, SQL 语句具有行参数的占位符。您可以传递参数值 in 作为 varargs 或对象数组。因此,您应该显式包装 primitives 在 primitive wrapper 类中,或者您应该使用 auto-boxing。
3.3.7. 检索自动生成的 Key
一种便捷的方法支持检索由
数据库。此支持是 JDBC 3.0 标准的一部分。请参阅
规格。该方法将 a 作为其第一个
参数,这是指定所需 INSERT 语句的方式。另一个
argument 是一个 ,其中包含从
更新。没有标准的单一方法来创建适当的 (这解释了为什么方法签名是这样的)。以下示例有效
在 Oracle 上,但可能无法在其他平台上工作:update()PreparedStatementCreatorKeyHolderPreparedStatement
final String INSERT_SQL = "insert into my_test (name) values(?)";
final String name = "Rob";
KeyHolder keyHolder = new GeneratedKeyHolder();
jdbcTemplate.update(connection -> {
PreparedStatement ps = connection.prepareStatement(INSERT_SQL, new String[] { "id" });
ps.setString(1, name);
return ps;
}, keyHolder);
// keyHolder.getKey() now contains the generated keyval INSERT_SQL = "insert into my_test (name) values(?)"
val name = "Rob"
val keyHolder = GeneratedKeyHolder()
jdbcTemplate.update({
it.prepareStatement (INSERT_SQL, arrayOf("id")).apply { setString(1, name) }
}, keyHolder)
// keyHolder.getKey() now contains the generated key3.4. 控制数据库连接
本节涵盖:
3.4.1. 使用DataSource
Spring 通过 .A 是
是 JDBC 规范的一部分,是一个通用的连接工厂。它允许
容器或框架隐藏连接池和事务管理问题
从应用程序代码中。作为开发人员,您无需了解有关如何
连接到数据库。这是设置
数据源。在开发和测试代码时,您很可能会同时担任这两个角色,但您
不必知道生产数据源的配置方式。DataSourceDataSource
当您使用 Spring 的 JDBC 层时,您可以从 JNDI 获取数据源,或者您可以
使用第三方提供的 Connection Pool 实现配置您自己的 Integration。
传统的选择是 Apache Commons DBCP 和带有 bean 样式类的 C3P0;
对于现代 JDBC 连接池,请考虑使用 HikariCP 及其构建器风格的 API。DataSource
您应该使用 and 类
(包含在 Spring 发行版中)仅用于测试目的!这些变体不会
提供池化,并且在对一个连接发出多个请求时性能不佳。DriverManagerDataSourceSimpleDriverDataSource |
以下部分使用 Spring 的实现。
稍后将介绍其他几种变体。DriverManagerDataSourceDataSource
要配置 :DriverManagerDataSource
-
获取连接,就像通常获取 JDBC 一样 连接。
DriverManagerDataSource -
指定 JDBC 驱动程序的完全限定类名,以便 可以加载驱动程序类。
DriverManager -
提供在 JDBC 驱动程序之间变化的 URL。(请参阅驱动程序的文档 以获取正确的值。
-
提供用户名和密码以连接到数据库。
以下示例演示如何在 Java 中配置 a:DriverManagerDataSource
DriverManagerDataSource dataSource = new DriverManagerDataSource();
dataSource.setDriverClassName("org.hsqldb.jdbcDriver");
dataSource.setUrl("jdbc:hsqldb:hsql://localhost:");
dataSource.setUsername("sa");
dataSource.setPassword("");val dataSource = DriverManagerDataSource().apply {
setDriverClassName("org.hsqldb.jdbcDriver")
url = "jdbc:hsqldb:hsql://localhost:"
username = "sa"
password = ""
}以下示例显示了相应的 XML 配置:
<bean id="dataSource" class="org.springframework.jdbc.datasource.DriverManagerDataSource">
<property name="driverClassName" value="${jdbc.driverClassName}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
<context:property-placeholder location="jdbc.properties"/>接下来的两个示例显示了 DBCP 和 C3P0 的基本连接和配置。 若要了解有助于控制池功能的更多选项,请参阅产品 有关相应连接池实现的文档。
以下示例显示了 DBCP 配置:
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="${jdbc.driverClassName}"/>
<property name="url" value="${jdbc.url}"/>
<property name="username" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
<context:property-placeholder location="jdbc.properties"/>以下示例显示了 C3P0 配置:
<bean id="dataSource" class="com.mchange.v2.c3p0.ComboPooledDataSource" destroy-method="close">
<property name="driverClass" value="${jdbc.driverClassName}"/>
<property name="jdbcUrl" value="${jdbc.url}"/>
<property name="user" value="${jdbc.username}"/>
<property name="password" value="${jdbc.password}"/>
</bean>
<context:property-placeholder location="jdbc.properties"/>3.4.2. 使用DataSourceUtils
该类是一个方便而强大的帮助程序类,它提供了从 JNDI 获取连接并在必要时关闭连接的方法。
它支持线程绑定的 JDBC,但
也与 和 。DataSourceUtilsstaticConnectionDataSourceTransactionManagerJtaTransactionManagerJpaTransactionManager
请注意,这意味着连接访问,使用它
在每个 JDBC 操作背后,隐式地参与正在进行的事务。JdbcTemplateDataSourceUtils
3.4.3. 实现SmartDataSource
该接口应由可以提供
连接到关系数据库。它扩展了接口,让
使用它的类查询是否应在给定的
操作。当您知道需要重用连接时,这种用法非常有效。SmartDataSourceDataSource
3.4.4. 扩展AbstractDataSource
AbstractDataSource是 Spring 实现的基类。它实现所有实现通用的代码。
如果您编写自己的 implementation ,则应扩展该类。abstractDataSourceDataSourceAbstractDataSourceDataSource
3.4.5. 使用SingleConnectionDataSource
该类是接口的实现,它包装了每次使用后未关闭的 single。
这不支持多线程。SingleConnectionDataSourceSmartDataSourceConnection
如果任何客户端代码在假设池连接的情况下调用(如使用
持久性工具),则应将该属性设置为 。此设置
返回包装物理连接的关闭抑制代理。请注意,您可以
不再将此强制转换为本机 Oracle 或类似对象。closesuppressClosetrueConnection
SingleConnectionDataSource主要是一个测试类。它通常可以轻松测试
与简单的 JNDI 环境相结合。
与 相反,它始终重用相同的连接,
避免过度创建物理连接。DriverManagerDataSource
3.4.6. 使用DriverManagerDataSource
该类是标准接口的实现,该接口通过 Bean 属性配置普通 JDBC 驱动程序,并每次返回一个新的驱动程序。DriverManagerDataSourceDataSourceConnection
此实现对于 Java EE 之外的测试和独立环境非常有用
容器,作为 Spring IoC 容器中的 Bean 或结合使用
使用简单的 JNDI 环境。池假设调用
关闭连接,以便任何 -aware 持久性代码都应该可以正常工作。然而
使用 JavaBean 风格的连接池(例如 )非常简单,即使在测试中也是如此
环境中,则使用这样的连接池几乎总是比 更可取。DataSourceConnection.close()DataSourcecommons-dbcpDriverManagerDataSource
3.4.7. 使用TransactionAwareDataSourceProxy
TransactionAwareDataSourceProxy是目标 的代理。代理会包装
target 来增加对 Spring 管理的事务的感知。在这方面,它
类似于 Java EE 服务器提供的事务性 JNDI 。DataSourceDataSourceDataSource
很少需要使用此类,除非必须为现有代码
调用并传递标准 JDBC 接口实现。在这种情况下,
您仍然可以让此代码可用,同时拥有此代码
参与 Spring 管理的事务。通常最好编写
通过使用更高级别的资源管理抽象(如 OR)来拥有新代码。DataSourceJdbcTemplateDataSourceUtils |
有关更多详细信息,请参见 TransactionAwareDataSourceProxy javadoc。
3.4.8. 使用DataSourceTransactionManager / JdbcTransactionManager
该类是单个 JDBC 的实现。它将 JDBC 从指定的线程绑定到当前正在执行的线程,可能
允许每个 .DataSourceTransactionManagerPlatformTransactionManagerDataSourceConnectionDataSourceConnectionDataSource
需要应用程序代码来检索 JDBC,而不是 Java EE 的标准 .它抛出未经检查的异常
而不是选中 .所有框架类(例如 )都使用
这种策略是隐含的。如果不与事务管理器一起使用,则查找策略
的行为完全相同,因此可以在任何情况下使用。ConnectionDataSourceUtils.getConnection(DataSource)DataSource.getConnectionorg.springframework.daoSQLExceptionsJdbcTemplateDataSource.getConnection
该类支持 savepoints ()、
自定义隔离级别和超时,作为适当的 JDBC 语句应用
查询超时。为了支持后者,应用程序代码必须使用 或
为每个 created 语句调用 method。DataSourceTransactionManagerPROPAGATION_NESTEDJdbcTemplateDataSourceUtils.applyTransactionTimeout(..)
您可以在
single-resource 的情况下,因为它不需要容器支持 JTA 事务
协调者。在这些事务管理器之间切换只是一个配置问题,
前提是您坚持使用所需的连接查找模式。请注意,JTA 不支持
SavePoint 或自定义隔离级别,并且具有不同的超时机制,但其他情况
在 JDBC 资源和 JDBC 提交/回滚管理方面公开了类似的行为。DataSourceTransactionManagerJtaTransactionManager
|
从 5.3 开始, Spring 提供了一个扩展的变体,它添加了
提交/回滚时的异常转换功能(与 一致)。
Where 只会抛出(类似于 JTA),将数据库锁定失败等转换为
相应的子类。请注意,应用程序代码需要
为此类异常做好准备,而不是完全期望 .
在这种情况下,是推荐的选择。 就异常行为而言, 大致等同于 和 ,作为立即
companion / replacement 彼此。 另一方面
等同于并且可以作为那里的直接替换。 |
3.5. JDBC 批量操作
如果对同一 JDBC 驱动程序进行批处理多个调用,则大多数 JDBC 驱动程序都会提供改进的性能 prepared 语句。通过将更新分组为批次,您可以限制往返次数 添加到数据库。
3.5.1. 使用JdbcTemplate
您可以通过实现特殊接口的两个方法 ,并将该实现作为第二个参数传入来完成批处理
在你的方法调用中。您可以使用该方法提供
当前批次。您可以使用该方法设置
准备好的语句。此方法称为您在调用中指定的次数。以下示例根据列表中的条目更新表
,整个列表用作批处理:JdbcTemplateBatchPreparedStatementSetterbatchUpdategetBatchSizesetValuesgetBatchSizet_actor
public class JdbcActorDao implements ActorDao {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public int[] batchUpdate(final List<Actor> actors) {
return this.jdbcTemplate.batchUpdate(
"update t_actor set first_name = ?, last_name = ? where id = ?",
new BatchPreparedStatementSetter() {
public void setValues(PreparedStatement ps, int i) throws SQLException {
Actor actor = actors.get(i);
ps.setString(1, actor.getFirstName());
ps.setString(2, actor.getLastName());
ps.setLong(3, actor.getId().longValue());
}
public int getBatchSize() {
return actors.size();
}
});
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val jdbcTemplate = JdbcTemplate(dataSource)
fun batchUpdate(actors: List<Actor>): IntArray {
return jdbcTemplate.batchUpdate(
"update t_actor set first_name = ?, last_name = ? where id = ?",
object: BatchPreparedStatementSetter {
override fun setValues(ps: PreparedStatement, i: Int) {
ps.setString(1, actors[i].firstName)
ps.setString(2, actors[i].lastName)
ps.setLong(3, actors[i].id)
}
override fun getBatchSize() = actors.size
})
}
// ... additional methods
}如果您处理更新流或从文件中读取数据,则可能会有一个
首选批处理大小,但最后一个批处理可能没有该数量的条目。在这个
case,你可以使用 interface 来使用
一旦 input 源耗尽,您就会中断一个批处理。方法
用于向批处理结束发出信号。InterruptibleBatchPreparedStatementSetterisBatchExhausted
3.5.2. 使用 List of Object 进行批量操作
和 the 都提供了另一种方式
提供批处理更新。您无需实现特殊的批处理接口,而是
以列表形式提供调用中的所有参数值。框架在这些
值并使用内部准备好的语句 setter 进行设置。API 因
是否使用命名参数。对于命名参数,您需要为批处理的每个成员提供一个 , 一个条目。你可以使用便捷的方法创建这个数组,传递
在 Bean 样式对象数组中(具有与参数对应的 getter 方法)、-keyed 实例(包含相应的参数作为值)或两者的混合。JdbcTemplateNamedParameterJdbcTemplateSqlParameterSourceSqlParameterSourceUtils.createBatchStringMap
以下示例显示了使用命名参数的批量更新:
public class JdbcActorDao implements ActorDao {
private NamedParameterTemplate namedParameterJdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.namedParameterJdbcTemplate = new NamedParameterJdbcTemplate(dataSource);
}
public int[] batchUpdate(List<Actor> actors) {
return this.namedParameterJdbcTemplate.batchUpdate(
"update t_actor set first_name = :firstName, last_name = :lastName where id = :id",
SqlParameterSourceUtils.createBatch(actors));
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val namedParameterJdbcTemplate = NamedParameterJdbcTemplate(dataSource)
fun batchUpdate(actors: List<Actor>): IntArray {
return this.namedParameterJdbcTemplate.batchUpdate(
"update t_actor set first_name = :firstName, last_name = :lastName where id = :id",
SqlParameterSourceUtils.createBatch(actors));
}
// ... additional methods
}对于使用经典占位符的 SQL 语句,您需要传入一个列表
包含具有 Update 值的对象数组。此对象数组必须有一个条目
,并且它们的顺序必须与它们的顺序相同
在 SQL 语句中定义。?
以下示例与前面的示例相同,只是它使用了 classic
JDBC 占位符:?
public class JdbcActorDao implements ActorDao {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public int[] batchUpdate(final List<Actor> actors) {
List<Object[]> batch = new ArrayList<Object[]>();
for (Actor actor : actors) {
Object[] values = new Object[] {
actor.getFirstName(), actor.getLastName(), actor.getId()};
batch.add(values);
}
return this.jdbcTemplate.batchUpdate(
"update t_actor set first_name = ?, last_name = ? where id = ?",
batch);
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val jdbcTemplate = JdbcTemplate(dataSource)
fun batchUpdate(actors: List<Actor>): IntArray {
val batch = mutableListOf<Array<Any>>()
for (actor in actors) {
batch.add(arrayOf(actor.firstName, actor.lastName, actor.id))
}
return jdbcTemplate.batchUpdate(
"update t_actor set first_name = ?, last_name = ? where id = ?", batch)
}
// ... additional methods
}我们之前介绍的所有批处理更新方法都返回一个数组
包含每个批处理条目受影响的行数。此计数由
JDBC 驱动程序。如果计数不可用,则 JDBC 驱动程序将返回值 。int-2
|
在这种情况下,通过在底层 上自动设置值,
每个值的相应 JDBC 类型需要从给定的 Java 类型派生。
虽然这通常效果很好,但可能会出现问题(例如,使用 Map 包含的值)。默认情况下,Spring 会调用这样的
case 的 intent 调用,这对于 JDBC 驱动程序来说可能会很昂贵。您应该使用最近的驱动程序
版本,并考虑将属性设置为(作为 JVM 系统属性或通过 或者,您可以考虑显式指定相应的 JDBC 类型。
通过 A(如前所示),通过 Explicit 类型
数组,通过对
custom 实例,或者通过 a 从 Java 声明的属性类型派生 SQL 类型,即使对于 null 值也是如此。 |
3.5.3. 具有多个 Batch 的批处理操作
前面的批处理更新示例处理的批处理非常大,以至于您希望
将它们分成几个较小的批次。您可以使用以下方法执行此操作
前面提到的,但现在有一个
更方便的方法。除了 SQL 语句之外,此方法还采用包含参数的对象,以及要为每个对象进行的更新次数
batch 和 a 设置参数的值
的 Script。框架会遍历提供的值并断开
将调用更新为指定大小的批处理。batchUpdateCollectionParameterizedPreparedStatementSetter
以下示例显示了使用批处理大小 100 的批处理更新:
public class JdbcActorDao implements ActorDao {
private JdbcTemplate jdbcTemplate;
public void setDataSource(DataSource dataSource) {
this.jdbcTemplate = new JdbcTemplate(dataSource);
}
public int[][] batchUpdate(final Collection<Actor> actors) {
int[][] updateCounts = jdbcTemplate.batchUpdate(
"update t_actor set first_name = ?, last_name = ? where id = ?",
actors,
100,
(PreparedStatement ps, Actor actor) -> {
ps.setString(1, actor.getFirstName());
ps.setString(2, actor.getLastName());
ps.setLong(3, actor.getId().longValue());
});
return updateCounts;
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val jdbcTemplate = JdbcTemplate(dataSource)
fun batchUpdate(actors: List<Actor>): Array<IntArray> {
return jdbcTemplate.batchUpdate(
"update t_actor set first_name = ?, last_name = ? where id = ?",
actors, 100) { ps, argument ->
ps.setString(1, argument.firstName)
ps.setString(2, argument.lastName)
ps.setLong(3, argument.id)
}
}
// ... additional methods
}此调用的 batch update 方法返回一个数组数组,其中包含一个
数组条目,其中包含每个更新受影响的行数的数组。
顶级数组的长度表示运行的批处理数,第二级
数组的长度表示该批次中的更新数量。中的更新数量
每个批次应为为所有批次提供的批次大小(最后一个批次除外)
这可能更少),具体取决于提供的 Update 对象总数。更新
count 是 JDBC 驱动程序报告的 count 语句。如果计数为
不可用,则 JDBC 驱动程序将返回值 。int-2
3.6. 使用 Classes 简化 JDBC 操作SimpleJdbc
和 类提供了简化的配置
通过利用可通过 JDBC 驱动程序检索的数据库元数据。
这意味着您需要预先配置的更少,尽管您可以覆盖或关闭
元数据处理(如果您希望在代码中提供所有详细信息)。SimpleJdbcInsertSimpleJdbcCall
3.6.1. 使用SimpleJdbcInsert
我们首先查看具有最小
配置选项。您应该在数据访问中实例化
图层的初始化方法。对于此示例,初始化方法是 method.您不需要对类进行子类化。相反
您可以通过该方法创建新实例并设置表名。
此类的配置方法遵循返回实例的样式
,它允许您链接所有配置方法。以下内容
example 仅使用一种配置方法(我们稍后将展示多种方法的示例):SimpleJdbcInsertSimpleJdbcInsertsetDataSourceSimpleJdbcInsertwithTableNamefluidSimpleJdbcInsert
public class JdbcActorDao implements ActorDao {
private SimpleJdbcInsert insertActor;
public void setDataSource(DataSource dataSource) {
this.insertActor = new SimpleJdbcInsert(dataSource).withTableName("t_actor");
}
public void add(Actor actor) {
Map<String, Object> parameters = new HashMap<String, Object>(3);
parameters.put("id", actor.getId());
parameters.put("first_name", actor.getFirstName());
parameters.put("last_name", actor.getLastName());
insertActor.execute(parameters);
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val insertActor = SimpleJdbcInsert(dataSource).withTableName("t_actor")
fun add(actor: Actor) {
val parameters = mutableMapOf<String, Any>()
parameters["id"] = actor.id
parameters["first_name"] = actor.firstName
parameters["last_name"] = actor.lastName
insertActor.execute(parameters)
}
// ... additional methods
}这里使用的方法将 plain 作为其唯一的参数。这
这里需要注意的重要一点是,用于 Must match the column 的键
表的名称,如数据库中所定义。这是因为我们读取了元数据
构造实际的 INSERT 语句。executejava.util.MapMap
3.6.2. 使用SimpleJdbcInsert
下一个示例使用与上一个示例相同的 insert,但是,它不是传入 , it
检索自动生成的键并将其设置在新对象上。当它创建
的 ,除了指定 table name 之外,它还指定 name
生成的键列。以下内容
清单显示了它是如何工作的:idActorSimpleJdbcInsertusingGeneratedKeyColumns
public class JdbcActorDao implements ActorDao {
private SimpleJdbcInsert insertActor;
public void setDataSource(DataSource dataSource) {
this.insertActor = new SimpleJdbcInsert(dataSource)
.withTableName("t_actor")
.usingGeneratedKeyColumns("id");
}
public void add(Actor actor) {
Map<String, Object> parameters = new HashMap<String, Object>(2);
parameters.put("first_name", actor.getFirstName());
parameters.put("last_name", actor.getLastName());
Number newId = insertActor.executeAndReturnKey(parameters);
actor.setId(newId.longValue());
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val insertActor = SimpleJdbcInsert(dataSource)
.withTableName("t_actor").usingGeneratedKeyColumns("id")
fun add(actor: Actor): Actor {
val parameters = mapOf(
"first_name" to actor.firstName,
"last_name" to actor.lastName)
val newId = insertActor.executeAndReturnKey(parameters);
return actor.copy(id = newId.toLong())
}
// ... additional methods
}使用第二种方法运行 insert 时的主要区别在于,您不会
将 添加到 中,然后调用该方法。这将返回一个对象,您可以使用该对象创建数字类型的实例,该实例
用于 domain 类。您不能依赖所有数据库都返回特定的 Java
类。 是您可以依赖的基类。如果你有
多个自动生成的列或生成的值为非数值,则可以
使用从方法返回的 a。idMapexecuteAndReturnKeyjava.lang.Numberjava.lang.NumberKeyHolderexecuteAndReturnKeyHolder
3.6.3. 为SimpleJdbcInsert
您可以通过使用 method 指定列名列表来限制插入的列,如下例所示:usingColumns
public class JdbcActorDao implements ActorDao {
private SimpleJdbcInsert insertActor;
public void setDataSource(DataSource dataSource) {
this.insertActor = new SimpleJdbcInsert(dataSource)
.withTableName("t_actor")
.usingColumns("first_name", "last_name")
.usingGeneratedKeyColumns("id");
}
public void add(Actor actor) {
Map<String, Object> parameters = new HashMap<String, Object>(2);
parameters.put("first_name", actor.getFirstName());
parameters.put("last_name", actor.getLastName());
Number newId = insertActor.executeAndReturnKey(parameters);
actor.setId(newId.longValue());
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val insertActor = SimpleJdbcInsert(dataSource)
.withTableName("t_actor")
.usingColumns("first_name", "last_name")
.usingGeneratedKeyColumns("id")
fun add(actor: Actor): Actor {
val parameters = mapOf(
"first_name" to actor.firstName,
"last_name" to actor.lastName)
val newId = insertActor.executeAndReturnKey(parameters);
return actor.copy(id = newId.toLong())
}
// ... additional methods
}插入的执行与依赖元数据来确定的执行相同 要使用的列。
3.6.4. 用于提供参数值SqlParameterSource
使用 a 提供参数值可以正常工作,但这不是最方便的
类来使用。Spring 提供了几个接口的实现,您可以使用它们。第一个是 ,
如果您有一个符合 JavaBean 的类,并且包含
你的价值观。它使用相应的 getter 方法提取参数
值。以下示例演示如何使用:MapSqlParameterSourceBeanPropertySqlParameterSourceBeanPropertySqlParameterSource
public class JdbcActorDao implements ActorDao {
private SimpleJdbcInsert insertActor;
public void setDataSource(DataSource dataSource) {
this.insertActor = new SimpleJdbcInsert(dataSource)
.withTableName("t_actor")
.usingGeneratedKeyColumns("id");
}
public void add(Actor actor) {
SqlParameterSource parameters = new BeanPropertySqlParameterSource(actor);
Number newId = insertActor.executeAndReturnKey(parameters);
actor.setId(newId.longValue());
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val insertActor = SimpleJdbcInsert(dataSource)
.withTableName("t_actor")
.usingGeneratedKeyColumns("id")
fun add(actor: Actor): Actor {
val parameters = BeanPropertySqlParameterSource(actor)
val newId = insertActor.executeAndReturnKey(parameters)
return actor.copy(id = newId.toLong())
}
// ... additional methods
}另一个选项是类似于 a 但提供更多
可以链接的便捷方法。以下示例演示如何使用它:MapSqlParameterSourceMapaddValue
public class JdbcActorDao implements ActorDao {
private SimpleJdbcInsert insertActor;
public void setDataSource(DataSource dataSource) {
this.insertActor = new SimpleJdbcInsert(dataSource)
.withTableName("t_actor")
.usingGeneratedKeyColumns("id");
}
public void add(Actor actor) {
SqlParameterSource parameters = new MapSqlParameterSource()
.addValue("first_name", actor.getFirstName())
.addValue("last_name", actor.getLastName());
Number newId = insertActor.executeAndReturnKey(parameters);
actor.setId(newId.longValue());
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val insertActor = SimpleJdbcInsert(dataSource)
.withTableName("t_actor")
.usingGeneratedKeyColumns("id")
fun add(actor: Actor): Actor {
val parameters = MapSqlParameterSource()
.addValue("first_name", actor.firstName)
.addValue("last_name", actor.lastName)
val newId = insertActor.executeAndReturnKey(parameters)
return actor.copy(id = newId.toLong())
}
// ... additional methods
}如您所见,配置是相同的。只有执行代码必须更改为 使用这些替代输入类。
3.6.5. 使用SimpleJdbcCall
该类使用数据库中的元数据来查找 的名称和参数,因此您不必显式声明它们。您可以
声明参数 如果您愿意这样做,或者您的参数(例如 or )没有自动映射到 Java 类。第一个例子
显示了一个仅返回 AND 格式的标量值的简单过程
从 MySQL 数据库。示例过程读取指定的 actor 条目,并以参数的形式返回 、 和 列。
下面的清单显示了第一个示例:SimpleJdbcCallinoutARRAYSTRUCTVARCHARDATEfirst_namelast_namebirth_dateout
CREATE PROCEDURE read_actor (
IN in_id INTEGER,
OUT out_first_name VARCHAR(100),
OUT out_last_name VARCHAR(100),
OUT out_birth_date DATE)
BEGIN
SELECT first_name, last_name, birth_date
INTO out_first_name, out_last_name, out_birth_date
FROM t_actor where id = in_id;
END;该参数包含您正在查找的 actor 的 。这些参数返回从表中读取的数据。in_ididout
您可以采用类似于声明 .你
应在 data-access 的 initialization method 中实例化和配置类
层。与类相比,您无需创建子类
并且您无需声明可在数据库元数据中查找的参数。
下面的配置示例使用前面存储的
过程(除了 之外,唯一的配置选项是名称
的存储过程):SimpleJdbcCallSimpleJdbcInsertStoredProcedureSimpleJdbcCallDataSource
public class JdbcActorDao implements ActorDao {
private SimpleJdbcCall procReadActor;
public void setDataSource(DataSource dataSource) {
this.procReadActor = new SimpleJdbcCall(dataSource)
.withProcedureName("read_actor");
}
public Actor readActor(Long id) {
SqlParameterSource in = new MapSqlParameterSource()
.addValue("in_id", id);
Map out = procReadActor.execute(in);
Actor actor = new Actor();
actor.setId(id);
actor.setFirstName((String) out.get("out_first_name"));
actor.setLastName((String) out.get("out_last_name"));
actor.setBirthDate((Date) out.get("out_birth_date"));
return actor;
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val procReadActor = SimpleJdbcCall(dataSource)
.withProcedureName("read_actor")
fun readActor(id: Long): Actor {
val source = MapSqlParameterSource().addValue("in_id", id)
val output = procReadActor.execute(source)
return Actor(
id,
output["out_first_name"] as String,
output["out_last_name"] as String,
output["out_birth_date"] as Date)
}
// ... additional methods
}您为执行调用编写的代码涉及创建一个包含 IN 参数。您必须与为 input 值提供的名称匹配
替换为存储过程中声明的参数名称。case 没有
匹配,因为您使用元数据来确定应如何引用数据库对象
在存储过程中。在存储过程的源中指定的内容不是
必然是它在数据库中的存储方式。一些数据库将名称转换为所有
大写,而其他 Cookie 则使用 Lower Case 或使用指定的大小写。SqlParameterSource
该方法采用 IN 参数并返回 a,其中包含由存储过程中指定的名称键控的任何参数。在本例中,它们是 、 和 。executeMapoutout_first_nameout_last_nameout_birth_date
该方法的最后一部分创建一个实例,用于返回
检索到的数据。同样,使用参数的名称很重要,因为它们
在存储过程中声明。此外,结果映射中存储的参数名称的大小写与
数据库,这可能因数据库而异。为了使您的代码更具可移植性,您应该
执行不区分大小写的查找或指示 Spring 使用 .
要执行后者,您可以创建自己的 ID 并将属性设置为 。然后,您可以将此自定义实例传递到
你的 .以下示例显示了此配置:executeActoroutoutoutLinkedCaseInsensitiveMapJdbcTemplatesetResultsMapCaseInsensitivetrueJdbcTemplateSimpleJdbcCall
public class JdbcActorDao implements ActorDao {
private SimpleJdbcCall procReadActor;
public void setDataSource(DataSource dataSource) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.setResultsMapCaseInsensitive(true);
this.procReadActor = new SimpleJdbcCall(jdbcTemplate)
.withProcedureName("read_actor");
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private var procReadActor = SimpleJdbcCall(JdbcTemplate(dataSource).apply {
isResultsMapCaseInsensitive = true
}).withProcedureName("read_actor")
// ... additional methods
}通过执行此操作,您可以避免用于
返回的参数。out
3.6.6. 显式声明用于SimpleJdbcCall
在本章的前面,我们介绍了如何从元数据中推导出参数,但您可以声明它们
如果你愿意的话,明确地。您可以通过创建和配置
该方法,它接受可变数量的对象
作为输入。有关如何定义 .SimpleJdbcCalldeclareParametersSqlParameterSqlParameter
| 如果您使用的数据库不支持 Spring,则显式声明是必需的 数据库。目前, Spring 支持对 以下数据库:Apache Derby、DB2、MySQL、Microsoft SQL Server、Oracle 和 Sybase。 我们还支持 MySQL、Microsoft SQL Server、 和 Oracle。 |
您可以选择显式声明一个、部分或所有参数。参数
在未显式声明参数的情况下,仍使用 metadata。要绕过所有
处理元数据查找潜在参数,并仅使用声明的
参数,您可以将该方法作为
声明。假设您为
database 函数。在这种情况下,您可以调用以指定列表
要为给定签名包含的 IN 参数名称。withoutProcedureColumnMetaDataAccessuseInParameterNames
以下示例显示了一个完全声明的过程调用,并使用 前面的示例:
public class JdbcActorDao implements ActorDao {
private SimpleJdbcCall procReadActor;
public void setDataSource(DataSource dataSource) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.setResultsMapCaseInsensitive(true);
this.procReadActor = new SimpleJdbcCall(jdbcTemplate)
.withProcedureName("read_actor")
.withoutProcedureColumnMetaDataAccess()
.useInParameterNames("in_id")
.declareParameters(
new SqlParameter("in_id", Types.NUMERIC),
new SqlOutParameter("out_first_name", Types.VARCHAR),
new SqlOutParameter("out_last_name", Types.VARCHAR),
new SqlOutParameter("out_birth_date", Types.DATE)
);
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val procReadActor = SimpleJdbcCall(JdbcTemplate(dataSource).apply {
isResultsMapCaseInsensitive = true
}).withProcedureName("read_actor")
.withoutProcedureColumnMetaDataAccess()
.useInParameterNames("in_id")
.declareParameters(
SqlParameter("in_id", Types.NUMERIC),
SqlOutParameter("out_first_name", Types.VARCHAR),
SqlOutParameter("out_last_name", Types.VARCHAR),
SqlOutParameter("out_birth_date", Types.DATE)
)
// ... additional methods
}两个示例的执行和最终结果是相同的。第二个示例指定所有 details 而不是依赖元数据。
3.6.7. 如何定义SqlParameters
为类和 RDBMS 操作定义参数
类(在 将 JDBC 操作建模为 Java 对象中介绍)或其子类之一。
为此,您通常在构造函数中指定参数名称和 SQL 类型。SQL 类型
是使用常量指定的。在本章的前面,我们看到了声明
类似于以下内容:SimpleJdbcSqlParameterjava.sql.Types
new SqlParameter("in_id", Types.NUMERIC),
new SqlOutParameter("out_first_name", Types.VARCHAR),SqlParameter("in_id", Types.NUMERIC),
SqlOutParameter("out_first_name", Types.VARCHAR),带有 the 的第一行声明一个 IN 参数。您可以使用 IN 参数
对于存储过程调用和查询,使用 及其
子类(在 Understanding SqlQuery 中介绍)。SqlParameterSqlQuery
第二行(带有 )声明要在
stored procedure 调用。还有一个 for 参数
(为过程提供 IN 值并返回值的参数)。SqlOutParameteroutSqlInOutParameterInOut
只有声明为 和 的参数才用于
提供输入值。这与类不同,类(对于
向后兼容性原因)允许为参数提供输入值
声明为 .SqlParameterSqlInOutParameterStoredProcedureSqlOutParameter |
对于 IN 参数,除了名称和 SQL 类型之外,您还可以为
数字数据或自定义数据库类型的类型名称。对于参数,您可以
提供 a 以处理从游标返回的行的映射。另一个
option 是指定一个 API,该 API 提供了一个定义
自定义返回值的处理。outRowMapperREFSqlReturnType
3.6.8. 使用SimpleJdbcCall
您可以采用与调用存储过程几乎相同的方式调用存储函数,但
提供函数名称而不是过程名称。您将该方法用作配置的一部分,以指示您希望
对函数的调用,以及函数调用的相应字符串。一个
专门的调用 () 用于运行函数,并且
将函数返回值作为指定类型的对象,这意味着您执行
不必从 Results Map 中检索返回值。类似的便捷方法
(named ) 也可用于只有一个参数的存储过程。以下示例(适用于 MySQL)基于名为 的存储函数,该函数返回 actor 的全名:withFunctionNameexecuteFunctionexecuteObjectoutget_actor_name
CREATE FUNCTION get_actor_name (in_id INTEGER)
RETURNS VARCHAR(200) READS SQL DATA
BEGIN
DECLARE out_name VARCHAR(200);
SELECT concat(first_name, ' ', last_name)
INTO out_name
FROM t_actor where id = in_id;
RETURN out_name;
END;为了调用这个函数,我们再次在初始化方法
如下例所示:SimpleJdbcCall
public class JdbcActorDao implements ActorDao {
private SimpleJdbcCall funcGetActorName;
public void setDataSource(DataSource dataSource) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.setResultsMapCaseInsensitive(true);
this.funcGetActorName = new SimpleJdbcCall(jdbcTemplate)
.withFunctionName("get_actor_name");
}
public String getActorName(Long id) {
SqlParameterSource in = new MapSqlParameterSource()
.addValue("in_id", id);
String name = funcGetActorName.executeFunction(String.class, in);
return name;
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val jdbcTemplate = JdbcTemplate(dataSource).apply {
isResultsMapCaseInsensitive = true
}
private val funcGetActorName = SimpleJdbcCall(jdbcTemplate)
.withFunctionName("get_actor_name")
fun getActorName(id: Long): String {
val source = MapSqlParameterSource().addValue("in_id", id)
return funcGetActorName.executeFunction(String::class.java, source)
}
// ... additional methods
}使用的方法返回 a,其中包含来自
函数调用。executeFunctionString
3.6.9. 从ResultSetSimpleJdbcCall
调用返回结果集的存储过程或函数有点棘手。一些
数据库在 JDBC 结果处理期间返回结果集,而其他数据库需要
显式注册的特定类型的参数。这两种方法都需要
additional processing 循环结果集并处理返回的行。跟
的 ,您可以使用该方法并声明要用于特定参数的实现。如果结果集为
返回,则没有定义名称,因此返回的
results 必须与声明 implementations 的顺序匹配。指定的名称仍用于存储已处理的结果列表
在从语句返回的结果映射中。outSimpleJdbcCallreturningResultSetRowMapperRowMapperexecute
下一个示例(对于 MySQL)使用一个不采用 IN 参数并返回
表中的所有行:t_actor
CREATE PROCEDURE read_all_actors()
BEGIN
SELECT a.id, a.first_name, a.last_name, a.birth_date FROM t_actor a;
END;要调用此过程,您可以声明 .因为您想要的类
要映射遵循 JavaBean 规则,您可以使用由
传入要在方法中映射到的必需类。
以下示例显示了如何执行此操作:RowMapperBeanPropertyRowMappernewInstance
public class JdbcActorDao implements ActorDao {
private SimpleJdbcCall procReadAllActors;
public void setDataSource(DataSource dataSource) {
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
jdbcTemplate.setResultsMapCaseInsensitive(true);
this.procReadAllActors = new SimpleJdbcCall(jdbcTemplate)
.withProcedureName("read_all_actors")
.returningResultSet("actors",
BeanPropertyRowMapper.newInstance(Actor.class));
}
public List getActorsList() {
Map m = procReadAllActors.execute(new HashMap<String, Object>(0));
return (List) m.get("actors");
}
// ... additional methods
}class JdbcActorDao(dataSource: DataSource) : ActorDao {
private val procReadAllActors = SimpleJdbcCall(JdbcTemplate(dataSource).apply {
isResultsMapCaseInsensitive = true
}).withProcedureName("read_all_actors")
.returningResultSet("actors",
BeanPropertyRowMapper.newInstance(Actor::class.java))
fun getActorsList(): List<Actor> {
val m = procReadAllActors.execute(mapOf<String, Any>())
return m["actors"] as List<Actor>
}
// ... additional methods
}调用以空 传递,因为此调用不采用任何参数。
然后,从结果映射中检索参与者列表并将其返回给调用者。executeMap
3.7. 将 JDBC 操作建模为 Java 对象
该包包含允许您访问
数据库。例如,您可以运行查询
并将结果作为列表返回,其中包含具有关系
映射到业务对象属性的列数据。您也可以运行 stored
过程并运行 Update、Delete 和 Insert 语句。org.springframework.jdbc.object
|
许多 Spring 开发人员认为,下面描述的各种 RDBMS 操作类
( 但是,如果您通过使用 RDBMS 操作类获得可衡量的值, 您应该继续使用这些类。 |
3.7.1. 理解SqlQuery
SqlQuery是封装 SQL 查询的可重用、线程安全的类。子
必须实现 method 以提供一个实例,该实例可以
为通过迭代创建的
在执行查询期间。该类很少直接使用,因为
子类为
将行映射到 Java 类。扩展的其他实现包括 和 。newRowMapper(..)RowMapperResultSetSqlQueryMappingSqlQuerySqlQueryMappingSqlQueryWithParametersUpdatableSqlQuery
3.7.2. 使用MappingSqlQuery
MappingSqlQuery是一个可重用的查询,其中具体子类必须实现
abstract 方法将提供的每一行转换为
object 指定类型。以下示例显示了一个自定义查询,该查询将
来自类实例的关系的数据:mapRow(..)ResultSett_actorActor
public class ActorMappingQuery extends MappingSqlQuery<Actor> {
public ActorMappingQuery(DataSource ds) {
super(ds, "select id, first_name, last_name from t_actor where id = ?");
declareParameter(new SqlParameter("id", Types.INTEGER));
compile();
}
@Override
protected Actor mapRow(ResultSet rs, int rowNumber) throws SQLException {
Actor actor = new Actor();
actor.setId(rs.getLong("id"));
actor.setFirstName(rs.getString("first_name"));
actor.setLastName(rs.getString("last_name"));
return actor;
}
}class ActorMappingQuery(ds: DataSource) : MappingSqlQuery<Actor>(ds, "select id, first_name, last_name from t_actor where id = ?") {
init {
declareParameter(SqlParameter("id", Types.INTEGER))
compile()
}
override fun mapRow(rs: ResultSet, rowNumber: Int) = Actor(
rs.getLong("id"),
rs.getString("first_name"),
rs.getString("last_name")
)
}类使用 type 扩展参数化。构造函数
对于此客户,查询将 A 作为唯一参数。在这个
构造函数,你可以使用 和 SQL 调用超类的构造函数
应该运行该 API 以检索此查询的行。此 SQL 用于
创建一个 ,以便它可以包含任何参数的占位符
在执行期间传入。您必须使用传入 .它需要一个 name,而 JDBC 类型
如 中所定义。定义所有参数后,您可以调用该方法,以便可以准备语句并在以后运行。这个类是
线程安全的,因此,只要这些实例是在 DAO
初始化后,它们可以保留为实例变量并可重用。以下内容
example 演示如何定义此类:MappingSqlQueryActorDataSourceDataSourcePreparedStatementdeclareParameterSqlParameterSqlParameterjava.sql.Typescompile()
private ActorMappingQuery actorMappingQuery;
@Autowired
public void setDataSource(DataSource dataSource) {
this.actorMappingQuery = new ActorMappingQuery(dataSource);
}
public Customer getCustomer(Long id) {
return actorMappingQuery.findObject(id);
}private val actorMappingQuery = ActorMappingQuery(dataSource)
fun getCustomer(id: Long) = actorMappingQuery.findObject(id)前面示例中的方法检索 customer,其中包含作为
only 参数。由于我们只想返回一个对象,因此我们将 convenience
方法。如果我们有一个返回
list of objects 并采用额外的参数,我们将使用其中一种方法,该方法接受作为 varargs 传入的参数值数组。以下内容
example 显示了这样的方法:idfindObjectidexecute
public List<Actor> searchForActors(int age, String namePattern) {
List<Actor> actors = actorSearchMappingQuery.execute(age, namePattern);
return actors;
}fun searchForActors(age: Int, namePattern: String) =
actorSearchMappingQuery.execute(age, namePattern)3.7.3. 使用SqlUpdate
该类封装了 SQL 更新。与查询一样,更新对象是
reuseable,并且与所有类一样,更新可以具有参数,并且是
在 SQL 中定义。此类提供了许多类似于 query 对象的方法的方法。类是具体的。可以是
subclassed — 例如,添加自定义更新方法。
但是,您不必对类进行子类化,因为可以通过设置 SQL 和声明参数轻松对其进行参数化。
以下示例创建一个名为 的自定义更新方法:SqlUpdateRdbmsOperationupdate(..)execute(..)SqlUpdateSqlUpdateexecute
import java.sql.Types;
import javax.sql.DataSource;
import org.springframework.jdbc.core.SqlParameter;
import org.springframework.jdbc.object.SqlUpdate;
public class UpdateCreditRating extends SqlUpdate {
public UpdateCreditRating(DataSource ds) {
setDataSource(ds);
setSql("update customer set credit_rating = ? where id = ?");
declareParameter(new SqlParameter("creditRating", Types.NUMERIC));
declareParameter(new SqlParameter("id", Types.NUMERIC));
compile();
}
/**
* @param id for the Customer to be updated
* @param rating the new value for credit rating
* @return number of rows updated
*/
public int execute(int id, int rating) {
return update(rating, id);
}
}import java.sql.Types
import javax.sql.DataSource
import org.springframework.jdbc.core.SqlParameter
import org.springframework.jdbc.object.SqlUpdate
class UpdateCreditRating(ds: DataSource) : SqlUpdate() {
init {
setDataSource(ds)
sql = "update customer set credit_rating = ? where id = ?"
declareParameter(SqlParameter("creditRating", Types.NUMERIC))
declareParameter(SqlParameter("id", Types.NUMERIC))
compile()
}
/**
* @param id for the Customer to be updated
* @param rating the new value for credit rating
* @return number of rows updated
*/
fun execute(id: Int, rating: Int): Int {
return update(rating, id)
}
}3.7.4. 使用StoredProcedure
该类是 RDBMS 的对象抽象的超类
存储过程。StoredProcedureabstract
继承的属性是 RDBMS 中存储过程的名称。sql
要为类定义参数,可以使用 或 1
的子类。您必须在构造函数中指定参数名称和 SQL 类型。
如下面的代码片段所示:StoredProcedureSqlParameter
new SqlParameter("in_id", Types.NUMERIC),
new SqlOutParameter("out_first_name", Types.VARCHAR),SqlParameter("in_id", Types.NUMERIC),
SqlOutParameter("out_first_name", Types.VARCHAR),SQL 类型是使用常量指定的。java.sql.Types
第一行(带有 )声明 IN 参数。您可以使用 IN 参数
对于存储过程调用和使用 the 及其
子类(在 Understanding SqlQuery 中介绍)。SqlParameterSqlQuery
第二行(带有 )声明要在
stored procedure 调用。还有一个 for 参数
(为过程提供值并返回值的参数)。SqlOutParameteroutSqlInOutParameterInOutin
对于参数,除了名称和 SQL 类型之外,您还可以指定
数字数据的 scale 或自定义数据库类型的 type name。对于参数,
您可以提供 to handle 从游标返回的行的映射。
另一个选项是指定一个,允许您定义自定义
返回值的处理。inoutRowMapperREFSqlReturnType
下一个简单 DAO 示例使用 a 调用函数
(),它随任何 Oracle 数据库一起提供。使用存储过程
功能,您必须创建一个扩展 .在这个
example,该类是一个内部类。但是,如果需要重用 ,则可以将其声明为顶级类。此示例没有输入
参数,但输出参数使用类声明为日期类型。该方法运行该过程并提取
从 results 返回 Date 。结果对每个声明的
output 参数(在本例中,只有一个)使用参数名称作为键。
下面的清单显示了我们的自定义 StoredProcedure 类:StoredProceduresysdate()StoredProcedureStoredProcedureStoredProcedureSqlOutParameterexecute()MapMap
import java.sql.Types;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import javax.sql.DataSource;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.SqlOutParameter;
import org.springframework.jdbc.object.StoredProcedure;
public class StoredProcedureDao {
private GetSysdateProcedure getSysdate;
@Autowired
public void init(DataSource dataSource) {
this.getSysdate = new GetSysdateProcedure(dataSource);
}
public Date getSysdate() {
return getSysdate.execute();
}
private class GetSysdateProcedure extends StoredProcedure {
private static final String SQL = "sysdate";
public GetSysdateProcedure(DataSource dataSource) {
setDataSource(dataSource);
setFunction(true);
setSql(SQL);
declareParameter(new SqlOutParameter("date", Types.DATE));
compile();
}
public Date execute() {
// the 'sysdate' sproc has no input parameters, so an empty Map is supplied...
Map<String, Object> results = execute(new HashMap<String, Object>());
Date sysdate = (Date) results.get("date");
return sysdate;
}
}
}import java.sql.Types
import java.util.Date
import java.util.Map
import javax.sql.DataSource
import org.springframework.jdbc.core.SqlOutParameter
import org.springframework.jdbc.object.StoredProcedure
class StoredProcedureDao(dataSource: DataSource) {
private val SQL = "sysdate"
private val getSysdate = GetSysdateProcedure(dataSource)
val sysdate: Date
get() = getSysdate.execute()
private inner class GetSysdateProcedure(dataSource: DataSource) : StoredProcedure() {
init {
setDataSource(dataSource)
isFunction = true
sql = SQL
declareParameter(SqlOutParameter("date", Types.DATE))
compile()
}
fun execute(): Date {
// the 'sysdate' sproc has no input parameters, so an empty Map is supplied...
val results = execute(mutableMapOf<String, Any>())
return results["date"] as Date
}
}
}下面的 a 示例有两个输出参数(在本例中为
Oracle REF cursors):StoredProcedure
import java.util.HashMap;
import java.util.Map;
import javax.sql.DataSource;
import oracle.jdbc.OracleTypes;
import org.springframework.jdbc.core.SqlOutParameter;
import org.springframework.jdbc.object.StoredProcedure;
public class TitlesAndGenresStoredProcedure extends StoredProcedure {
private static final String SPROC_NAME = "AllTitlesAndGenres";
public TitlesAndGenresStoredProcedure(DataSource dataSource) {
super(dataSource, SPROC_NAME);
declareParameter(new SqlOutParameter("titles", OracleTypes.CURSOR, new TitleMapper()));
declareParameter(new SqlOutParameter("genres", OracleTypes.CURSOR, new GenreMapper()));
compile();
}
public Map<String, Object> execute() {
// again, this sproc has no input parameters, so an empty Map is supplied
return super.execute(new HashMap<String, Object>());
}
}import java.util.HashMap
import javax.sql.DataSource
import oracle.jdbc.OracleTypes
import org.springframework.jdbc.core.SqlOutParameter
import org.springframework.jdbc.object.StoredProcedure
class TitlesAndGenresStoredProcedure(dataSource: DataSource) : StoredProcedure(dataSource, SPROC_NAME) {
companion object {
private const val SPROC_NAME = "AllTitlesAndGenres"
}
init {
declareParameter(SqlOutParameter("titles", OracleTypes.CURSOR, TitleMapper()))
declareParameter(SqlOutParameter("genres", OracleTypes.CURSOR, GenreMapper()))
compile()
}
fun execute(): Map<String, Any> {
// again, this sproc has no input parameters, so an empty Map is supplied
return super.execute(HashMap<String, Any>())
}
}请注意
构造函数中使用的是传递的实现实例。这是一种非常方便和强大的重用现有
功能性。接下来的两个示例提供了两种实现的代码。declareParameter(..)TitlesAndGenresStoredProcedureRowMapperRowMapper
该类将 a 映射到 中每一行的域对象
提供的 ,如下所示:TitleMapperResultSetTitleResultSet
import java.sql.ResultSet;
import java.sql.SQLException;
import com.foo.domain.Title;
import org.springframework.jdbc.core.RowMapper;
public final class TitleMapper implements RowMapper<Title> {
public Title mapRow(ResultSet rs, int rowNum) throws SQLException {
Title title = new Title();
title.setId(rs.getLong("id"));
title.setName(rs.getString("name"));
return title;
}
}import java.sql.ResultSet
import com.foo.domain.Title
import org.springframework.jdbc.core.RowMapper
class TitleMapper : RowMapper<Title> {
override fun mapRow(rs: ResultSet, rowNum: Int) =
Title(rs.getLong("id"), rs.getString("name"))
}该类将 a 映射到 中每一行的域对象
提供的 ,如下所示:GenreMapperResultSetGenreResultSet
import java.sql.ResultSet;
import java.sql.SQLException;
import com.foo.domain.Genre;
import org.springframework.jdbc.core.RowMapper;
public final class GenreMapper implements RowMapper<Genre> {
public Genre mapRow(ResultSet rs, int rowNum) throws SQLException {
return new Genre(rs.getString("name"));
}
}import java.sql.ResultSet
import com.foo.domain.Genre
import org.springframework.jdbc.core.RowMapper
class GenreMapper : RowMapper<Genre> {
override fun mapRow(rs: ResultSet, rowNum: Int): Genre {
return Genre(rs.getString("name"))
}
}将参数传递给其
定义,您可以编写一个强类型方法,该方法将
delegate 分配给超类中的非类型化方法,如下例所示:execute(..)execute(Map)
import java.sql.Types;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import javax.sql.DataSource;
import oracle.jdbc.OracleTypes;
import org.springframework.jdbc.core.SqlOutParameter;
import org.springframework.jdbc.core.SqlParameter;
import org.springframework.jdbc.object.StoredProcedure;
public class TitlesAfterDateStoredProcedure extends StoredProcedure {
private static final String SPROC_NAME = "TitlesAfterDate";
private static final String CUTOFF_DATE_PARAM = "cutoffDate";
public TitlesAfterDateStoredProcedure(DataSource dataSource) {
super(dataSource, SPROC_NAME);
declareParameter(new SqlParameter(CUTOFF_DATE_PARAM, Types.DATE);
declareParameter(new SqlOutParameter("titles", OracleTypes.CURSOR, new TitleMapper()));
compile();
}
public Map<String, Object> execute(Date cutoffDate) {
Map<String, Object> inputs = new HashMap<String, Object>();
inputs.put(CUTOFF_DATE_PARAM, cutoffDate);
return super.execute(inputs);
}
}import java.sql.Types
import java.util.Date
import javax.sql.DataSource
import oracle.jdbc.OracleTypes
import org.springframework.jdbc.core.SqlOutParameter
import org.springframework.jdbc.core.SqlParameter
import org.springframework.jdbc.object.StoredProcedure
class TitlesAfterDateStoredProcedure(dataSource: DataSource) : StoredProcedure(dataSource, SPROC_NAME) {
companion object {
private const val SPROC_NAME = "TitlesAfterDate"
private const val CUTOFF_DATE_PARAM = "cutoffDate"
}
init {
declareParameter(SqlParameter(CUTOFF_DATE_PARAM, Types.DATE))
declareParameter(SqlOutParameter("titles", OracleTypes.CURSOR, TitleMapper()))
compile()
}
fun execute(cutoffDate: Date) = super.execute(
mapOf<String, Any>(CUTOFF_DATE_PARAM to cutoffDate))
}3.8. 参数和数据值处理的常见问题
参数和数据值的常见问题存在于不同的方法中 由 Spring Framework 的 JDBC 支持提供。本节介绍如何解决这些问题。
3.8.1. 为参数提供 SQL 类型信息
通常,Spring 会根据参数的类型来确定参数的 SQL 类型
传入。可以显式提供在设置
参数值。这有时对于正确设置值是必要的。NULL
您可以通过多种方式提供 SQL 类型信息:
-
的许多 update 和 query 方法在 数组的形式。此数组用于指示 相应的参数。提供 每个参数一个条目。
JdbcTemplateintjava.sql.Types -
你可以使用 class 来包装需要 this 的 parameter value 其他信息。为此,请为每个值创建一个新实例并传入 SQL 类型 和构造函数中的参数值。您还可以提供可选的比例 参数表示数值。
SqlParameterValue -
对于使用命名参数的方法,可以使用类或 .他们都有方法 用于注册任何命名参数值的 SQL 类型。
SqlParameterSourceBeanPropertySqlParameterSourceMapSqlParameterSource
3.8.2. 处理 BLOB 和 CLOB 对象
您可以在数据库中存储图像、其他二进制数据和大块文本。这些
对于二进制数据,大型对象称为 BLOB(二进制大型对象),对于 CLOB(字符
Large OBject) 获取字符数据。在 Spring 中,您可以使用
直接使用,以及使用 RDBMS 提供的更高抽象时
Objects 和 Class.所有这些方法都使用
用于实际管理 LOB (Large OBject) 数据的接口。 通过方法
用于创建要插入的新 LOB 对象。JdbcTemplateSimpleJdbcLobHandlerLobHandlerLobCreatorgetLobCreator
LobCreator并为 LOB 输入和输出提供以下支持:LobHandler
-
斑点
-
byte[]:和getBlobAsBytessetBlobAsBytes -
InputStream:和getBlobAsBinaryStreamsetBlobAsBinaryStream
-
-
CLOB
-
String:和getClobAsStringsetClobAsString -
InputStream:和getClobAsAsciiStreamsetClobAsAsciiStream -
Reader:和getClobAsCharacterStreamsetClobAsCharacterStream
-
下一个示例演示如何创建和插入 BLOB。稍后我们将介绍如何阅读 it 从数据库返回。
此示例使用 a 和 .它实现一种方法 .此方法提供了一个,我们使用它来设置
SQL 插入语句中的 LOB 列。JdbcTemplateAbstractLobCreatingPreparedStatementCallbacksetValuesLobCreator
对于此示例,我们假设有一个变量 ,它已经是
设置为 .通常通过
依赖注入。lobHandlerDefaultLobHandler
以下示例演示如何创建和插入 BLOB:
final File blobIn = new File("spring2004.jpg");
final InputStream blobIs = new FileInputStream(blobIn);
final File clobIn = new File("large.txt");
final InputStream clobIs = new FileInputStream(clobIn);
final InputStreamReader clobReader = new InputStreamReader(clobIs);
jdbcTemplate.execute(
"INSERT INTO lob_table (id, a_clob, a_blob) VALUES (?, ?, ?)",
new AbstractLobCreatingPreparedStatementCallback(lobHandler) { (1)
protected void setValues(PreparedStatement ps, LobCreator lobCreator) throws SQLException {
ps.setLong(1, 1L);
lobCreator.setClobAsCharacterStream(ps, 2, clobReader, (int)clobIn.length()); (2)
lobCreator.setBlobAsBinaryStream(ps, 3, blobIs, (int)blobIn.length()); (3)
}
}
);
blobIs.close();
clobReader.close();| 1 | 传入 (在本例中) 是普通的 .lobHandlerDefaultLobHandler |
| 2 | 使用该方法传入 CLOB 的内容。setClobAsCharacterStream |
| 3 | 使用该方法传入 BLOB 的内容。setBlobAsBinaryStream |
val blobIn = File("spring2004.jpg")
val blobIs = FileInputStream(blobIn)
val clobIn = File("large.txt")
val clobIs = FileInputStream(clobIn)
val clobReader = InputStreamReader(clobIs)
jdbcTemplate.execute(
"INSERT INTO lob_table (id, a_clob, a_blob) VALUES (?, ?, ?)",
object: AbstractLobCreatingPreparedStatementCallback(lobHandler) { (1)
override fun setValues(ps: PreparedStatement, lobCreator: LobCreator) {
ps.setLong(1, 1L)
lobCreator.setClobAsCharacterStream(ps, 2, clobReader, clobIn.length().toInt()) (2)
lobCreator.setBlobAsBinaryStream(ps, 3, blobIs, blobIn.length().toInt()) (3)
}
}
)
blobIs.close()
clobReader.close()| 1 | 传入 (在本例中) 是普通的 .lobHandlerDefaultLobHandler |
| 2 | 使用该方法传入 CLOB 的内容。setClobAsCharacterStream |
| 3 | 使用该方法传入 BLOB 的内容。setBlobAsBinaryStream |
|
如果在返回的 from 上调用 、 、 或 方法,则可以选择指定负值
对于参数。如果指定的内容长度为负数,则使用 set-stream 方法的 JDBC 4.0 变体,而不使用
length 参数。否则,它将指定的长度传递给驱动程序。 请参阅您所使用的 JDBC 驱动程序的文档,以验证它是否支持流式处理 一个 LOB,但未提供内容长度。 |
现在,可以从数据库中读取 LOB 数据。同样,您将 a 与相同的实例变量和对 .
以下示例显示了如何执行此操作:JdbcTemplatelobHandlerDefaultLobHandler
List<Map<String, Object>> l = jdbcTemplate.query("select id, a_clob, a_blob from lob_table",
new RowMapper<Map<String, Object>>() {
public Map<String, Object> mapRow(ResultSet rs, int i) throws SQLException {
Map<String, Object> results = new HashMap<String, Object>();
String clobText = lobHandler.getClobAsString(rs, "a_clob"); (1)
results.put("CLOB", clobText);
byte[] blobBytes = lobHandler.getBlobAsBytes(rs, "a_blob"); (2)
results.put("BLOB", blobBytes);
return results;
}
});| 1 | 使用该方法检索 CLOB 的内容。getClobAsString |
| 2 | 使用该方法检索 BLOB 的内容。getBlobAsBytes |
val l = jdbcTemplate.query("select id, a_clob, a_blob from lob_table") { rs, _ ->
val clobText = lobHandler.getClobAsString(rs, "a_clob") (1)
val blobBytes = lobHandler.getBlobAsBytes(rs, "a_blob") (2)
mapOf("CLOB" to clobText, "BLOB" to blobBytes)
}| 1 | 使用该方法检索 CLOB 的内容。getClobAsString |
| 2 | 使用该方法检索 BLOB 的内容。getBlobAsBytes |
3.8.3. 传入 IN 子句的值列表
SQL 标准允许根据包含
variable 的值列表。一个典型的例子是 。准备好的语句不直接支持此变量列表
JDBC 标准。不能声明可变数量的占位符。您需要一个号码
的变体,并准备好所需数量的占位符,或者您需要生成
SQL 字符串,一旦您知道需要多少个占位符。命名的
Parameter support 采用后一种方法。
您可以将值作为简单值的 (或任何) 传入。
此列表用于将所需的占位符插入到实际的 SQL 语句中
并在语句执行期间传入值。select * from t_actor where id in
(1, 2, 3)NamedParameterJdbcTemplatejava.util.ListIterable
传入许多值时要小心。JDBC 标准不保证
表达式列表可以有 100 个以上的值。各种数据库超过
这个数字,但它们通常对允许的值数量有硬性限制。
例如,Oracle 的限制为 1000。IN |
除了值列表中的基元值之外,您还可以创建 of 对象数组。此列表可以支持为子句定义的多个表达式,例如 .当然,这需要您的数据库支持此语法。java.util.Listinselect * from t_actor where (id, last_name) in ((1, 'Johnson'), (2,
'Harrop'))
3.8.4. 处理存储过程调用的复杂类型
调用存储过程时,有时可以使用特定于
数据库。为了适应这些类型,Spring 提供了一个用于处理
当它们从存储过程调用返回时,以及当它们
作为参数传递给存储过程。SqlReturnTypeSqlTypeValue
接口有一个方法(名为 ),该方法必须是
实现。此接口用作 .
以下示例显示如何返回用户的 Oracle 对象的值
声明类型 :SqlReturnTypegetTypeValueSqlOutParameterSTRUCTITEM_TYPE
public class TestItemStoredProcedure extends StoredProcedure {
public TestItemStoredProcedure(DataSource dataSource) {
// ...
declareParameter(new SqlOutParameter("item", OracleTypes.STRUCT, "ITEM_TYPE",
(CallableStatement cs, int colIndx, int sqlType, String typeName) -> {
STRUCT struct = (STRUCT) cs.getObject(colIndx);
Object[] attr = struct.getAttributes();
TestItem item = new TestItem();
item.setId(((Number) attr[0]).longValue());
item.setDescription((String) attr[1]);
item.setExpirationDate((java.util.Date) attr[2]);
return item;
}));
// ...
}class TestItemStoredProcedure(dataSource: DataSource) : StoredProcedure() {
init {
// ...
declareParameter(SqlOutParameter("item", OracleTypes.STRUCT, "ITEM_TYPE") { cs, colIndx, sqlType, typeName ->
val struct = cs.getObject(colIndx) as STRUCT
val attr = struct.getAttributes()
TestItem((attr[0] as Long, attr[1] as String, attr[2] as Date)
})
// ...
}
}您可以使用 将 Java 对象(例如 )的值传递给
stored 过程。该接口具有您必须实现的单个方法 (名为 )。活动连接传入,您
可以使用它来创建特定于数据库的对象,例如实例
或 instances 的 S 。以下示例创建一个实例:SqlTypeValueTestItemSqlTypeValuecreateTypeValueStructDescriptorArrayDescriptorStructDescriptor
final TestItem testItem = new TestItem(123L, "A test item",
new SimpleDateFormat("yyyy-M-d").parse("2010-12-31"));
SqlTypeValue value = new AbstractSqlTypeValue() {
protected Object createTypeValue(Connection conn, int sqlType, String typeName) throws SQLException {
StructDescriptor itemDescriptor = new StructDescriptor(typeName, conn);
Struct item = new STRUCT(itemDescriptor, conn,
new Object[] {
testItem.getId(),
testItem.getDescription(),
new java.sql.Date(testItem.getExpirationDate().getTime())
});
return item;
}
};val (id, description, expirationDate) = TestItem(123L, "A test item",
SimpleDateFormat("yyyy-M-d").parse("2010-12-31"))
val value = object : AbstractSqlTypeValue() {
override fun createTypeValue(conn: Connection, sqlType: Int, typeName: String?): Any {
val itemDescriptor = StructDescriptor(typeName, conn)
return STRUCT(itemDescriptor, conn,
arrayOf(id, description, java.sql.Date(expirationDate.time)))
}
}现在可以将其添加到包含存储过程调用的输入参数的 中。SqlTypeValueMapexecute
的另一个用途是将值数组传递给存储的 Oracle
程序。在这种情况下,必须使用 Oracle 自己的内部类,并且
您可以使用 创建 Oracle 的实例并填充
它与来自 Java 的值,如下例所示:SqlTypeValueARRAYSqlTypeValueARRAYARRAY
final Long[] ids = new Long[] {1L, 2L};
SqlTypeValue value = new AbstractSqlTypeValue() {
protected Object createTypeValue(Connection conn, int sqlType, String typeName) throws SQLException {
ArrayDescriptor arrayDescriptor = new ArrayDescriptor(typeName, conn);
ARRAY idArray = new ARRAY(arrayDescriptor, conn, ids);
return idArray;
}
};class TestItemStoredProcedure(dataSource: DataSource) : StoredProcedure() {
init {
val ids = arrayOf(1L, 2L)
val value = object : AbstractSqlTypeValue() {
override fun createTypeValue(conn: Connection, sqlType: Int, typeName: String?): Any {
val arrayDescriptor = ArrayDescriptor(typeName, conn)
return ARRAY(arrayDescriptor, conn, ids)
}
}
}
}3.9. 嵌入式数据库支持
该软件包支持嵌入式
Java 数据库引擎。提供对 HSQL、H2 和 Derby 的支持
本地。您还可以使用可扩展 API 插入新的嵌入式数据库类型和实现。org.springframework.jdbc.datasource.embeddedDataSource
3.9.2. 使用 Spring XML 创建嵌入式数据库
如果要将嵌入式数据库实例作为 Spring 中的 bean 公开,可以在命名空间中使用该标签:ApplicationContextembedded-databasespring-jdbc
<jdbc:embedded-database id="dataSource" generate-name="true">
<jdbc:script location="classpath:schema.sql"/>
<jdbc:script location="classpath:test-data.sql"/>
</jdbc:embedded-database>前面的配置创建了一个嵌入式 HSQL 数据库,该数据库填充了 SQL
和 类路径根目录中的资源。此外,由于
最佳做法是,为 Embedded Database 分配一个唯一生成的 Name。这
嵌入式数据库作为 Bean 类型提供给 Spring 容器,然后可以根据需要将其注入到数据访问对象中。schema.sqltest-data.sqljavax.sql.DataSource
3.9.3. 以编程方式创建嵌入式数据库
该类提供了一个 Fluent API,用于构造嵌入式
数据库。当您需要在
独立环境或独立集成测试中,如以下示例所示:EmbeddedDatabaseBuilder
EmbeddedDatabase db = new EmbeddedDatabaseBuilder()
.generateUniqueName(true)
.setType(H2)
.setScriptEncoding("UTF-8")
.ignoreFailedDrops(true)
.addScript("schema.sql")
.addScripts("user_data.sql", "country_data.sql")
.build();
// perform actions against the db (EmbeddedDatabase extends javax.sql.DataSource)
db.shutdown()val db = EmbeddedDatabaseBuilder()
.generateUniqueName(true)
.setType(H2)
.setScriptEncoding("UTF-8")
.ignoreFailedDrops(true)
.addScript("schema.sql")
.addScripts("user_data.sql", "country_data.sql")
.build()
// perform actions against the db (EmbeddedDatabase extends javax.sql.DataSource)
db.shutdown()有关所有支持选项的更多详细信息,请参阅 EmbeddedDatabaseBuilder 的 javadoc。
您还可以使用 通过 Java 创建嵌入式数据库
配置,如下例所示:EmbeddedDatabaseBuilder
@Configuration
public class DataSourceConfig {
@Bean
public DataSource dataSource() {
return new EmbeddedDatabaseBuilder()
.generateUniqueName(true)
.setType(H2)
.setScriptEncoding("UTF-8")
.ignoreFailedDrops(true)
.addScript("schema.sql")
.addScripts("user_data.sql", "country_data.sql")
.build();
}
}@Configuration
class DataSourceConfig {
@Bean
fun dataSource(): DataSource {
return EmbeddedDatabaseBuilder()
.generateUniqueName(true)
.setType(H2)
.setScriptEncoding("UTF-8")
.ignoreFailedDrops(true)
.addScript("schema.sql")
.addScripts("user_data.sql", "country_data.sql")
.build()
}
}3.9.4. 选择嵌入式数据库类型
本节介绍如何选择 Spring 支持。它包括以下主题:
使用 HSQL
Spring 支持 HSQL 1.8.0 及更高版本。HSQL 是默认嵌入式数据库(如果 no type 为
显式指定。要显式指定 HSQL,请将标记的属性设置为 。如果您使用构建器 API,请使用 .typeembedded-databaseHSQLsetType(EmbeddedDatabaseType)EmbeddedDatabaseType.HSQL
3.9.5. 使用嵌入式数据库测试数据访问逻辑
嵌入式数据库提供了一种测试数据访问代码的轻量级方法。下一个示例是
使用嵌入式数据库的数据访问集成测试模板。使用此类模板
当嵌入式数据库不需要在测试中重复使用时,对于一次性操作可能很有用
类。但是,如果您希望创建在测试套件中共享的嵌入式数据库,
考虑使用 Spring TestContext 框架和
在 Spring 中将嵌入式数据库配置为 Bean,如
在使用 Spring XML 创建嵌入式数据库和以编程方式创建嵌入式数据库中。以下清单
显示测试模板:ApplicationContext
public class DataAccessIntegrationTestTemplate {
private EmbeddedDatabase db;
@BeforeEach
public void setUp() {
// creates an HSQL in-memory database populated from default scripts
// classpath:schema.sql and classpath:data.sql
db = new EmbeddedDatabaseBuilder()
.generateUniqueName(true)
.addDefaultScripts()
.build();
}
@Test
public void testDataAccess() {
JdbcTemplate template = new JdbcTemplate(db);
template.query( /* ... */ );
}
@AfterEach
public void tearDown() {
db.shutdown();
}
}class DataAccessIntegrationTestTemplate {
private lateinit var db: EmbeddedDatabase
@BeforeEach
fun setUp() {
// creates an HSQL in-memory database populated from default scripts
// classpath:schema.sql and classpath:data.sql
db = EmbeddedDatabaseBuilder()
.generateUniqueName(true)
.addDefaultScripts()
.build()
}
@Test
fun testDataAccess() {
val template = JdbcTemplate(db)
template.query( /* ... */)
}
@AfterEach
fun tearDown() {
db.shutdown()
}
}3.9.6. 为嵌入式数据库生成唯一名称
如果开发团队的测试套件
无意中尝试重新创建同一数据库的其他实例。这可以
如果 XML 配置文件或类负责
创建嵌入式数据库,然后重用相应的配置
跨同一测试套件(即,在同一个 JVM 中)中的多个测试场景
process) — 例如,针对嵌入式数据库进行集成测试,这些数据库的配置仅在 bean 定义方面有所不同
配置文件处于活动状态。@ConfigurationApplicationContext
此类错误的根本原因是 Spring 的(使用
在 XML 命名空间元素和 for Java 配置内部)将嵌入式数据库的名称设置为(如果未另行指定)。对于 的情况 ,
Embedded Database 通常被分配一个等于 Bean 的名称(通常为
类似于 )。因此,后续尝试创建嵌入式数据库
不会导致新数据库。相反,相同的 JDBC 连接 URL 被重用,
并且尝试创建新的嵌入式数据库实际上指向现有的
从相同配置创建的嵌入式数据库。EmbeddedDatabaseFactory<jdbc:embedded-database>EmbeddedDatabaseBuildertestdb<jdbc:embedded-database>iddataSource
为了解决这个常见问题,Spring Framework 4.2 提供了对生成 嵌入式数据库的唯一名称。要启用生成名称的使用,请使用 以下选项。
-
EmbeddedDatabaseFactory.setGenerateUniqueDatabaseName() -
EmbeddedDatabaseBuilder.generateUniqueName() -
<jdbc:embedded-database generate-name="true" … >
3.9.7. 扩展嵌入式数据库支持
您可以通过两种方式扩展 Spring JDBC 嵌入式数据库支持:
-
Implement 以支持新的嵌入式数据库类型。
EmbeddedDatabaseConfigurer -
Implement 以支持新的实现,例如 连接池,用于管理嵌入式数据库连接。
DataSourceFactoryDataSource
我们鼓励您在 GitHub Issues 上为 Spring 社区贡献扩展。
3.10. 初始化DataSource
该软件包支持初始化
现有的 .嵌入式数据库支持提供了一个用于创建
以及初始化 for for 应用程序。但是,有时可能需要初始化
在某处的服务器上运行的实例。org.springframework.jdbc.datasource.initDataSourceDataSource
3.10.1. 使用 Spring XML 初始化数据库
如果要初始化数据库并且可以提供对 bean 的引用,则可以在名称空间中使用标记:DataSourceinitialize-databasespring-jdbc
<jdbc:initialize-database data-source="dataSource">
<jdbc:script location="classpath:com/foo/sql/db-schema.sql"/>
<jdbc:script location="classpath:com/foo/sql/db-test-data.sql"/>
</jdbc:initialize-database>前面的示例对数据库运行两个指定的脚本。第一个
script 创建一个架构,第二个 script 使用测试数据集填充 table。剧本
locations 也可以是带有通配符的模式,采用通常用于资源的 Ant 样式
在 Spring 中(例如 )。如果您使用
pattern,则脚本将按其 URL 或文件名的词法顺序运行。classpath*:/com/foo/**/sql/*-data.sql
数据库初始值设定项的默认行为是无条件地运行提供的 脚本。这可能并不总是您想要的 — 例如,如果您运行 针对已包含测试数据的数据库的脚本。可能性 的意外删除数据通过遵循常见模式来减少(如前所示) 首先创建表,然后插入数据。如果出现以下情况,则第一步失败 表已存在。
但是,为了更好地控制现有数据的创建和删除,XML namespace 提供了一些其他选项。第一个是用于将 initialization on 和 off。你可以根据环境进行设置(比如拉取 boolean 值)。以下示例从 system 属性获取值:
<jdbc:initialize-database data-source="dataSource"
enabled="#{systemProperties.INITIALIZE_DATABASE}"> (1)
<jdbc:script location="..."/>
</jdbc:initialize-database>| 1 | 从名为 的系统属性中获取 的值。enabledINITIALIZE_DATABASE |
控制现有数据发生情况的第二个选项是更宽容 失败。为此,您可以控制初始化器忽略某些 错误,如下例所示:
<jdbc:initialize-database data-source="dataSource" ignore-failures="DROPS">
<jdbc:script location="..."/>
</jdbc:initialize-database>在前面的示例中,我们表示我们期望有时运行脚本
针对空数据库,并且脚本中有一些语句
因此,会失败。因此,失败的 SQL 语句将被忽略,但其他失败的语句将被忽略
将导致异常。如果您的 SQL 方言不支持(或类似),但您希望在之前无条件地删除所有测试数据,这将非常有用
重新创建它。在这种情况下,第一个脚本通常是一组语句
后跟一组语句。DROPDROPDROP … IF
EXISTSDROPCREATE
该选项可以设置为 (默认)、(ignore failed
drops) 或 (ignore all failures) 的 Launch。ignore-failuresNONEDROPSALL
每个语句都应该用 or 换行符分隔(如果字符不是)
完全存在于脚本中。您可以全局控制它,也可以逐个脚本控制它,因为
以下示例显示:;;
<jdbc:initialize-database data-source="dataSource" separator="@@"> (1)
<jdbc:script location="classpath:com/myapp/sql/db-schema.sql" separator=";"/> (2)
<jdbc:script location="classpath:com/myapp/sql/db-test-data-1.sql"/>
<jdbc:script location="classpath:com/myapp/sql/db-test-data-2.sql"/>
</jdbc:initialize-database>| 1 | 将分隔符脚本设置为 .@@ |
| 2 | 将 的分隔符设置为 。db-schema.sql; |
在此示例中,这两个脚本使用 as 语句分隔符,并且仅使用
用途 .此配置指定默认分隔符
is 并覆盖脚本的默认值。test-data@@db-schema.sql;@@db-schema
如果您需要的控制比从 XML 命名空间获得的控制更多,则可以直接使用 并将其定义为应用程序中的一个组件。DataSourceInitializer
初始化依赖于数据库的其他组件
一大类应用程序(那些在 Spring 上下文具有 started) 可以使用数据库初始化器,而无需再使用 并发症。如果您的应用程序不是其中之一,则可能需要阅读其余部分 本节。
数据库初始值设定项依赖于实例并运行脚本
在其初始化回调中提供(类似于 XML Bean 中的 an
definition、组件中的方法或实现 ) 的组件中的方法 。如果其他 bean 依赖于
相同的数据源并在初始化回调中使用数据源,则
可能是个问题,因为数据尚未初始化。一个常见的例子
这是一个 Cache 缓存,它预先初始化并从 Application 上的数据库加载数据
启动。DataSourceinit-method@PostConstructafterPropertiesSet()InitializingBean
要解决此问题,您有两个选择:更改缓存初始化策略 添加到稍后的阶段,或者确保先初始化数据库初始值设定项。
如果应用程序由您控制,则更改缓存初始化策略可能很容易。 有关如何实现此功能的一些建议包括:
-
使缓存在首次使用时延迟初始化,从而改善应用程序启动 时间。
-
让您的缓存或初始化缓存的单独组件实现 或 .当应用程序上下文启动时,您可以 通过设置它的标志来自动启动 A,你可以 通过调用 Enclosing 上下文手动启动 A。
LifecycleSmartLifecycleSmartLifecycleautoStartupLifecycleConfigurableApplicationContext.start() -
使用 Spring 或类似的自定义观察者机制来触发 cache 初始化。 始终由 context 发布,当 它已准备好使用(在所有 bean 都已初始化之后),因此这通常是有用的 hook (这是默认的工作方式)。
ApplicationEventContextRefreshedEventSmartLifecycle
确保首先初始化数据库初始值设定项也很容易。有关如何实现此功能的一些建议包括:
-
依赖于 Spring 的默认行为,即 bean 是 按注册顺序初始化。您可以通过采用通用的 在 XML 配置中对一组元素进行排序的实践 应用程序模块,并确保数据库和数据库初始化 列在第一位。
BeanFactory<import/> -
分离 和 使用它的业务组件并控制它们的 启动顺序,将它们放在单独的实例中(例如, 父上下文包含 ,子上下文包含业务 组件)。这种结构在 Spring Web 应用程序中很常见,但可能更多 普遍适用。
DataSourceApplicationContextDataSource
4. 使用 R2DBC 进行数据访问
R2DBC(“反应式关系数据库连接”)是一个社区驱动的 规范工作,以使用反应模式标准化对 SQL 数据库的访问。
4.1. 包层次结构
Spring 框架的 R2DBC 抽象框架由两个不同的包组成:
-
core:该包包含类以及各种相关类。请参阅使用 R2DBC 核心类控制基本的 R2DBC 处理和错误处理。org.springframework.r2dbc.coreDatabaseClient -
connection:包包含一个实用程序类 用于轻松访问和各种简单的实施 可用于测试和运行未修改的 R2DBC。请参阅控制数据库连接。org.springframework.r2dbc.connectionConnectionFactoryConnectionFactory
4.2. 使用 R2DBC 核心类控制基本的 R2DBC 处理和错误处理
本节介绍如何使用 R2DBC 核心类来控制基本的 R2DBC 处理。 包括错误处理。它包括以下主题:
4.2.1. 使用DatabaseClient
DatabaseClient是 R2DBC 核心包中的中心类。它处理
创建和释放资源,这有助于避免常见错误,例如
忘记关闭连接。它执行内核 R2DBC 的基本任务
工作流(例如语句创建和执行),让应用程序代码提供
SQL 并提取结果。类:DatabaseClient
-
运行 SQL 查询
-
更新语句和存储过程调用
-
对实例执行迭代
Result -
捕获 R2DBC 异常,并将其转换为泛型、信息量更大的异常 hierarchy 中定义的 Hierarchy。(请参阅一致的异常层次结构。
org.springframework.dao
客户端有一个功能齐全的 Fluent API,使用反应式类型进行声明式组合。
当你将 the 用于你的代码时,你只需要实现接口,为它们提供一个明确定义的协定。
给定类提供的 a,回调会创建一个 .对于映射函数也是如此,这些函数
提取结果。DatabaseClientjava.util.functionConnectionDatabaseClientFunctionPublisherRow
您可以通过直接实例化在 DAO 实现中使用
替换为引用,或者您可以在 Spring IoC 容器中配置它
并将其作为 bean 引用提供给 DAO。DatabaseClientConnectionFactory
创建对象的最简单方法是通过静态工厂方法,如下所示:DatabaseClient
DatabaseClient client = DatabaseClient.create(connectionFactory);val client = DatabaseClient.create(connectionFactory)应该始终在 Spring IoC 中配置为 bean
容器。ConnectionFactory |
上述方法使用默认设置创建一个。DatabaseClient
您还可以从 获取实例。
您可以通过以下方法自定义客户端:BuilderDatabaseClient.builder()
-
….bindMarkers(…):提供特定的 to configure named 参数绑定到数据库绑定标记翻译。BindMarkersFactory -
….executeFunction(…):设置对象获取 跑。ExecuteFunctionStatement -
….namedParameters(false):禁用命名参数扩展。默认启用。
方言由 BindMarkersFactoryResolver 从 中解析,通常是通过检查 .你可以让 Spring 通过注册一个 通过 . 发现 Bind Marker Provider 实现 使用 Spring 的 . ConnectionFactoryConnectionFactoryMetadataBindMarkersFactoryorg.springframework.r2dbc.core.binding.BindMarkersFactoryResolver$BindMarkerFactoryProviderMETA-INF/spring.factoriesBindMarkersFactoryResolverSpringFactoriesLoader |
当前支持的数据库包括:
-
H2 系列
-
MariaDB的
-
Microsoft SQL 服务器
-
MySQL (MySQL的
-
Postgres
此类发出的所有 SQL 都记录在类别
对应于 Client 端实例的完全限定类名(通常为 )。此外,每次执行都会在
reactive 序列来帮助调试。DEBUGDefaultDatabaseClient
以下部分提供了一些用法示例。这些例子
并不是 .
有关此内容,请参阅随附的 javadoc。DatabaseClientDatabaseClient
执行语句
DatabaseClient提供运行语句的基本功能。
以下示例显示了您需要包含的最小但功能齐全的内容
创建新表的代码:
Mono<Void> completion = client.sql("CREATE TABLE person (id VARCHAR(255) PRIMARY KEY, name VARCHAR(255), age INTEGER);")
.then();client.sql("CREATE TABLE person (id VARCHAR(255) PRIMARY KEY, name VARCHAR(255), age INTEGER);")
.await()DatabaseClient旨在方便、流畅地使用。
它在
执行规范。上面的示例用于返回一个完成,该完成在查询(或 queries,如果 SQL 查询包含
multiple statements) 完成。then()Publisher
execute(…)接受 SQL 查询字符串或查询,以将实际的查询创建推迟到执行。Supplier<String> |
查询 (SELECT)
SQL 查询可以通过对象或受影响的行数返回值。 可以返回更新的行数或行本身,
取决于发出的查询。RowDatabaseClient
以下查询从表中获取 and 列:idname
Mono<Map<String, Object>> first = client.sql("SELECT id, name FROM person")
.fetch().first();val first = client.sql("SELECT id, name FROM person")
.fetch().awaitSingle()以下查询使用 bind 变量:
Mono<Map<String, Object>> first = client.sql("SELECT id, name FROM person WHERE first_name = :fn")
.bind("fn", "Joe")
.fetch().first();val first = client.sql("SELECT id, name FROM person WHERE WHERE first_name = :fn")
.bind("fn", "Joe")
.fetch().awaitSingle()您可能已经注意到了上面示例中的 of 用法。 是一个
continuation 运算符,用于指定要使用的数据量。fetch()fetch()
调用 返回结果中的第一行并丢弃其余行。
您可以使用以下运算符来使用数据:first()
-
first()返回整个结果的第一行。其 Kotlin 协程变体 针对不可为 null 的返回值命名,并且该值是可选的。awaitSingle()awaitSingleOrNull() -
one()只返回一个结果,如果结果包含更多行,则失败。 使用 Kotlin 协程,对于一个值,或者该值可能是 .awaitOne()awaitOneOrNull()null -
all()返回结果的所有行。使用 Kotlin 协程时,请使用 .flow() -
rowsUpdated()返回受影响的行数 (// count)。其 Kotlin 协程变体名为 。INSERTUPDATEDELETEawaitRowsUpdated()
在不指定进一步的映射详细信息的情况下,查询将返回表格结果
as 的键是映射到其列值的不区分大小写的列名。Map
您可以通过提供一个 get
调用,以便它可以返回任意值(奇异值、
集合和映射以及对象)。Function<Row, T>Row
以下示例提取列并发出其值:name
Flux<String> names = client.sql("SELECT name FROM person")
.map(row -> row.get("name", String.class))
.all();val names = client.sql("SELECT name FROM person")
.map{ row: Row -> row.get("name", String.class) }
.flow()更新 (, , 和 )INSERTUPDATEDELETEDatabaseClient
修改语句的唯一区别是这些语句通常
不返回表格数据,以便您用于使用结果。rowsUpdated()
以下示例显示了一个返回数字
的更新行数:UPDATE
Mono<Integer> affectedRows = client.sql("UPDATE person SET first_name = :fn")
.bind("fn", "Joe")
.fetch().rowsUpdated();val affectedRows = client.sql("UPDATE person SET first_name = :fn")
.bind("fn", "Joe")
.fetch().awaitRowsUpdated()将值绑定到查询
典型的应用程序需要参数化的 SQL 语句来 select 或
根据一些输入更新 Rows。这些通常是语句
受子句约束的 OR AND 语句接受
input 参数。如果满足以下条件,参数化语句会有 SQL 注入的风险
参数没有正确转义。 利用 R2DBC 的 API 来消除查询参数的 SQL 注入风险。
您可以使用运算符
并将参数绑定到实际的 .然后,您的 R2DBC 驱动程序运行
使用准备好的语句和参数替换的语句。SELECTWHEREINSERTUPDATEDatabaseClientbindexecute(…)Statement
参数绑定支持两种绑定策略:
-
By Index,使用从 0 开始的参数索引。
-
By Name (按名称) 使用占位符名称。
以下示例显示了查询的参数绑定:
db.sql("INSERT INTO person (id, name, age) VALUES(:id, :name, :age)")
.bind("id", "joe")
.bind("name", "Joe")
.bind("age", 34);query-preprocessor 将命名参数展开到一系列 bind 中
标记,无需根据参数数量创建动态查询。
嵌套对象数组已扩展以允许使用(例如)选择列表。Collection
请考虑以下查询:
SELECT id, name, state FROM table WHERE (name, age) IN (('John', 35), ('Ann', 50))上述查询可以参数化并运行,如下所示:
List<Object[]> tuples = new ArrayList<>();
tuples.add(new Object[] {"John", 35});
tuples.add(new Object[] {"Ann", 50});
client.sql("SELECT id, name, state FROM table WHERE (name, age) IN (:tuples)")
.bind("tuples", tuples);val tuples: MutableList<Array<Any>> = ArrayList()
tuples.add(arrayOf("John", 35))
tuples.add(arrayOf("Ann", 50))
client.sql("SELECT id, name, state FROM table WHERE (name, age) IN (:tuples)")
.bind("tuples", tuples)| 选择列表的使用取决于供应商。 |
以下示例显示了使用谓词的更简单的变体:IN
client.sql("SELECT id, name, state FROM table WHERE age IN (:ages)")
.bind("ages", Arrays.asList(35, 50));val tuples: MutableList<Array<Any>> = ArrayList()
tuples.add(arrayOf("John", 35))
tuples.add(arrayOf("Ann", 50))
client.sql("SELECT id, name, state FROM table WHERE age IN (:ages)")
.bind("tuples", arrayOf(35, 50))R2DBC 本身不支持类似 Collection 的值。不过
在上面的例子中展开 given 适用于命名参数
在 Spring 的 R2DBC 支持中,例如用于上面所示的子句中。
但是,插入或更新数组类型的列(例如在 Postgres 中)
需要底层 R2DBC 驱动程序支持的数组类型:
通常是一个 Java 数组,例如 以更新列。
不要将 or 等作为数组参数传递。ListINString[]text[]Collection<String> |
语句筛选器
有时,您需要在运行之前对实际选项进行微调。注册筛选器
() 到 intercept 和
modify 语句的执行情况,如下例所示:StatementStatementStatementFilterFunctionDatabaseClient
client.sql("INSERT INTO table (name, state) VALUES(:name, :state)")
.filter((s, next) -> next.execute(s.returnGeneratedValues("id")))
.bind("name", …)
.bind("state", …);client.sql("INSERT INTO table (name, state) VALUES(:name, :state)")
.filter { s: Statement, next: ExecuteFunction -> next.execute(s.returnGeneratedValues("id")) }
.bind("name", …)
.bind("state", …)DatabaseClient暴露还简化了 overload 接受:filter(…)Function<Statement, Statement>
client.sql("INSERT INTO table (name, state) VALUES(:name, :state)")
.filter(statement -> s.returnGeneratedValues("id"));
client.sql("SELECT id, name, state FROM table")
.filter(statement -> s.fetchSize(25));client.sql("INSERT INTO table (name, state) VALUES(:name, :state)")
.filter { statement -> s.returnGeneratedValues("id") }
client.sql("SELECT id, name, state FROM table")
.filter { statement -> s.fetchSize(25) }StatementFilterFunctionimplementations 允许过滤 the 和 filter of objects。StatementResult
DatabaseClient最佳实践
类的实例一旦配置,就是线程安全的。这是
重要,因为这意味着您可以配置单个实例,然后将此共享引用安全地注入多个 DAO(或存储库)。
它是有状态的,因为它维护对 ,
但此状态不是对话状态。DatabaseClientDatabaseClientDatabaseClientConnectionFactory
使用该类时的常见做法是在 Spring 配置文件中配置 a,然后 dependency-inject
将 bean 共享到您的 DAO 类中。在
.这导致了类似于以下内容的 DAO:DatabaseClientConnectionFactoryConnectionFactoryDatabaseClientConnectionFactory
public class R2dbcCorporateEventDao implements CorporateEventDao {
private DatabaseClient databaseClient;
public void setConnectionFactory(ConnectionFactory connectionFactory) {
this.databaseClient = DatabaseClient.create(connectionFactory);
}
// R2DBC-backed implementations of the methods on the CorporateEventDao follow...
}class R2dbcCorporateEventDao(connectionFactory: ConnectionFactory) : CorporateEventDao {
private val databaseClient = DatabaseClient.create(connectionFactory)
// R2DBC-backed implementations of the methods on the CorporateEventDao follow...
}显式配置的替代方法是使用组件扫描和注释
支持依赖项注入。在这种情况下,你可以用 (这使它成为组件扫描的候选者) 来注释类,并 注释 setter
方法与 .以下示例显示了如何执行此操作:@ComponentConnectionFactory@Autowired
@Component (1)
public class R2dbcCorporateEventDao implements CorporateEventDao {
private DatabaseClient databaseClient;
@Autowired (2)
public void setConnectionFactory(ConnectionFactory connectionFactory) {
this.databaseClient = DatabaseClient.create(connectionFactory); (3)
}
// R2DBC-backed implementations of the methods on the CorporateEventDao follow...
}| 1 | 用 .@Component |
| 2 | 使用 .ConnectionFactory@Autowired |
| 3 | 使用 创建新的 .DatabaseClientConnectionFactory |
@Component (1)
class R2dbcCorporateEventDao(connectionFactory: ConnectionFactory) : CorporateEventDao { (2)
private val databaseClient = DatabaseClient(connectionFactory) (3)
// R2DBC-backed implementations of the methods on the CorporateEventDao follow...
}| 1 | 用 .@Component |
| 2 | 构造函数注入 .ConnectionFactory |
| 3 | 使用 创建新的 .DatabaseClientConnectionFactory |
无论您选择使用上述哪种模板初始化样式(或
not),则很少需要为每个
运行时间。配置后,实例是线程安全的。
如果您的应用程序访问多个
databases 中,您可能需要多个实例,这需要多个实例,然后需要多个不同配置的实例。DatabaseClientDatabaseClientDatabaseClientConnectionFactoryDatabaseClient
4.3. 检索自动生成的 Key
INSERT语句可能会在表中插入行时生成键
定义 auto-increment 或 identity 列。要完全控制
要生成的列名,只需注册一个
请求为所需列生成的键。StatementFilterFunction
Mono<Integer> generatedId = client.sql("INSERT INTO table (name, state) VALUES(:name, :state)")
.filter(statement -> s.returnGeneratedValues("id"))
.map(row -> row.get("id", Integer.class))
.first();
// generatedId emits the generated key once the INSERT statement has finishedval generatedId = client.sql("INSERT INTO table (name, state) VALUES(:name, :state)")
.filter { statement -> s.returnGeneratedValues("id") }
.map { row -> row.get("id", Integer.class) }
.awaitOne()
// generatedId emits the generated key once the INSERT statement has finished4.4. 控制数据库连接
本节涵盖:
4.4.1. 使用ConnectionFactory
Spring 通过 .
A 是 R2DBC 规范的一部分,是一个常见的入口点
对于Drivers。它允许容器或框架隐藏连接池
以及应用程序代码中的事务管理问题。作为开发人员,
您无需了解有关如何连接到数据库的详细信息。那就是
设置 的管理员的责任。你
在开发和测试代码时,很可能会同时担任这两个角色,但您不会
必须知道生产数据源的配置方式。ConnectionFactoryConnectionFactoryConnectionFactory
当您使用 Spring 的 R2DBC 层时,您可以使用
连接池实现由第三方提供。一个流行的
implementation 是 R2DBC Pool ()。Spring 中的实现
distribution 仅用于测试目的,不提供池化。r2dbc-pool
要配置 :ConnectionFactory
-
获取连接,就像通常获取 R2DBC 一样。
ConnectionFactoryConnectionFactory -
提供 R2DBC URL (有关正确的值,请参阅驱动程序的文档)。
以下示例显示如何配置 :ConnectionFactory
ConnectionFactory factory = ConnectionFactories.get("r2dbc:h2:mem:///test?options=DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE");val factory = ConnectionFactories.get("r2dbc:h2:mem:///test?options=DB_CLOSE_DELAY=-1;DB_CLOSE_ON_EXIT=FALSE");4.4.2. 使用ConnectionFactoryUtils
该类是一个方便而强大的辅助类
,它提供了从连接获取和关闭连接的方法(如有必要)。ConnectionFactoryUtilsstaticConnectionFactory
它支持订阅者绑定连接,例如 .ContextR2dbcTransactionManager
4.4.3. 使用SingleConnectionFactory
该类是 interface 的实现,它包装了一个在每次使用后都不会关闭的 single。SingleConnectionFactoryDelegatingConnectionFactoryConnection
如果任何客户端代码在假设池连接的情况下调用(如使用
持久性工具),则应将该属性设置为 。此设置
返回包装物理连接的关闭抑制代理。请注意,您可以
不再将此对象强制转换为本机或类似对象。closesuppressClosetrueConnection
SingleConnectionFactory主要是一个测试类,可用于特定要求
例如 pipelining (如果您的 R2DBC 驱动程序允许此类使用)。
与 pooled 相比,它始终重用相同的连接,从而避免
过度创建物理连接。ConnectionFactory
4.4.4. 使用TransactionAwareConnectionFactoryProxy
TransactionAwareConnectionFactoryProxy是目标 的代理。
代理包装该目标以增加对 Spring 管理的事务的感知。ConnectionFactoryConnectionFactory
如果您使用未以其他方式集成的 R2DBC 客户端,则需要使用此类
具有 Spring 的 R2DBC 支持。在这种情况下,您仍然可以使用此客户端,并且
同时,让这个 Client 端参与 Spring 管理的事务。它通常是
最好将 R2DBC 客户端与适当的访问权限集成以进行资源管理。ConnectionFactoryUtils |
有关更多详细信息,请参见 TransactionAwareConnectionFactoryProxy javadoc。
4.4.5. 使用R2dbcTransactionManager
该类是
单个 R2DBC 。它将 R2DBC 从指定绑定到 subscriber ,可能允许每个 有一个 subscriber 。R2dbcTransactionManagerReactiveTransactionManagerConnectionFactoryConnectionConnectionFactoryContextConnectionConnectionFactory
需要应用程序代码才能通过 检索 R2DBC,而不是 R2DBC 的标准 .所有框架类(例如 )都使用 this
策略。如果不与事务管理器一起使用,则查找策略的行为为
完全一样,因此可以在任何情况下使用。ConnectionConnectionFactoryUtils.getConnection(ConnectionFactory)ConnectionFactory.create()DatabaseClientConnectionFactory.create()
5. 对象关系映射 (ORM) 数据访问
本节介绍使用对象关系映射 (ORM) 时的数据访问。
5.1. 使用 Spring 的 ORM 简介
Spring Framework 支持与 Java Persistence API (JPA) 和 支持用于资源管理的原生 Hibernate、数据访问对象 (DAO) 实现、 和交易策略。例如,对于 Hibernate,有一流的支持 几个方便的 IoC 功能,解决了许多典型的 Hibernate 集成问题。 您可以为 OR(对象关系)映射配置所有支持的功能 工具。他们可以参与 Spring 的资源和 事务管理,并且它们符合 Spring 的通用事务和 DAO 异常层次结构。推荐的集成样式是针对普通 DAO 编写代码 Hibernate 或 JPA API。
Spring 在创建时为您选择的 ORM 层添加了重要的增强功能 数据访问应用程序。您可以利用尽可能多的集成支持 wish 的 Wish 进行 API 的 API 集成,您应该将这种集成工作与构建的成本和风险进行比较 类似的内部基础设施。您可以像使用 库,无论技术如何,因为一切都被设计为一组可重用的 JavaBeans 的 Java Beans 中。Spring IoC 容器中的 ORM 有助于配置和部署。因此 本节中的大多数示例都显示了 Spring 容器内的配置。
使用 Spring Framework 创建 ORM DAO 的好处包括:
-
更轻松的测试。Spring 的 IoC 方法使交换实现变得容易 以及 Hibernate 实例、JDBC 实例、事务管理器和映射对象实现(如果需要)的配置位置。这 反过来,可以更轻松地在 隔离。
SessionFactoryDataSource -
常见的数据访问异常。Spring 可以从您的 ORM 工具包装异常, 将它们从专有 (可能选中) 异常转换为通用运行时层次结构。此功能允许您处理大多数持久性 异常,这些异常是不可恢复的,仅在适当的层中,没有 烦人的样板捕获、抛出和异常声明。您仍然可以诱捕 并根据需要处理异常。请记住,JDBC 异常(包括 特定于 DB 的方言)也会转换为相同的层次结构,这意味着您可以 在一致的编程模型中使用 JDBC 执行一些操作。
DataAccessException -
一般资源管理。Spring 应用程序上下文可以处理位置 以及 Hibernate 实例、JPA 实例、JDBC 实例和其他相关资源的配置。这使得这些 值易于管理和更改。Spring 提供高效、轻松和安全的处理 持久性资源。例如,使用 Hibernate 的相关代码通常需要 使用相同的 Hibernate 来确保效率和适当的事务处理。 Spring 使 创建一个 并透明地绑定到当前线程变得容易, 通过 Hibernate 公开电流。因此,Spring 解决了许多典型 Hibernate 使用的长期问题,适用于任何本地或 JTA 事务环境。
SessionFactoryEntityManagerFactoryDataSourceSessionSessionSessionSessionFactory -
集成交易管理。你可以用声明式的 面向方面编程 (AOP) 风格的方法拦截器,或者通过在 XML 配置文件。在这两种情况下,事务语义和异常处理 (回滚等)将为您处理。如 资源和事务管理 中所述, 您还可以交换各种事务 Management 器,而不会影响与 ORM 相关的代码。 例如,您可以在 local transactions 和 JTA 之间进行交换,具有相同的完整服务 (例如声明式事务)在这两种情况下都可用。此外 与 JDBC 相关的代码可以在事务上与您用于执行 ORM 的代码完全集成。 这对于不适合 ORM 的数据访问(例如批处理和 BLOB 流),但这仍然需要与 ORM 操作共享公共事务。
@Transactional
| 提供更全面的 ORM 支持,包括对替代数据库的支持 技术,您可能希望查看 Spring Data 项目套件。如果你是 JPA 用户,则 Getting Started Access https://spring.io 的 Data with JPA 指南提供了很好的介绍。 |
5.2. 一般 ORM 集成注意事项
本节重点介绍适用于所有 ORM 技术的注意事项。 Hibernate 部分提供了更多详细信息,还显示了这些功能和 配置。
Spring 的 ORM 集成的主要目标是清晰的应用程序分层(包含任何数据 Access 和 Transaction 技术)以及应用程序对象的松散耦合 — 否 更多的业务服务依赖于数据访问或事务策略,仅此而已 硬编码的资源查找,不再有难以替换的单例,不再有自定义服务 登记处。目标是使用一种简单而一致的方法来连接应用程序对象,同时保持 它们尽可能可重用且不受容器依赖项的约束。所有个体 数据访问功能可以单独使用,但可以与 Spring 的 application context 概念,提供基于 XML 的配置和 不需要 Spring 感知的普通 JavaBean 实例。在典型的 Spring 应用程序中, 许多重要的对象都是 JavaBeans:数据访问模板、数据访问对象、 事务管理器、使用数据访问对象和事务的业务服务 管理器、Web 视图解析程序、使用业务服务的 Web 控制器等。
5.2.1. 资源和事务管理
典型的业务应用程序充满了重复的资源管理代码。 许多项目试图发明自己的解决方案,有时会牺牲适当的处理方式 的失败。Spring 提倡简单的解决方案 资源处理,即在 JDBC 的情况下通过模板进行 IoC 并应用 AOP ORM 技术的拦截器。
基础设施提供适当的资源处理和
特定 API 异常添加到未经检查的基础架构异常层次结构中。Spring
引入了 DAO 异常层次结构,适用于任何数据访问策略。对于直接
JDBC 是上一节中提到的类,它提供连接处理和到层次结构的正确转换,包括特定于数据库的 SQL 错误的转换
代码转换为有意义的异常类。对于 ORM 技术,请参阅下一节以了解如何获得相同的异常
翻译的好处。JdbcTemplateSQLExceptionDataAccessException
当涉及到事务管理时,该类与 Spring 挂钩
事务支持并支持 JTA 和 JDBC 事务,通过各自的
Spring 事务管理器。对于支持的 ORM 技术,Spring 提供了 Hibernate
以及通过 Hibernate 和 JPA 事务管理器以及 JTA 支持实现的 JPA 支持。
有关事务支持的详细信息,请参阅 事务管理 章节。JdbcTemplate
5.2.2. 异常转换
在 DAO 中使用 Hibernate 或 JPA 时,必须决定如何处理持久性
technology 的原生异常类。DAO 根据技术抛出 a 或 的子类。这些异常都是运行时的
exceptions 的,并且不必声明或捕获。您可能还必须处理 和 。这意味着调用方只能
将异常视为通常是致命的,除非它们想要依赖于持久性
技术自身的异常结构。捕获特定原因(例如乐观的
locking failure)如果不将调用者绑定到 implementation strategy,就不可能。
这种权衡对于强基于 ORM 或
不需要任何特殊的异常处理(或两者)。但是,Spring 允许例外
通过注释透明地应用翻译。以下内容
示例(一个用于 Java 配置,一个用于 XML 配置)展示了如何做到这一点:HibernateExceptionPersistenceExceptionIllegalArgumentExceptionIllegalStateException@Repository
@Repository
public class ProductDaoImpl implements ProductDao {
// class body here...
}@Repository
class ProductDaoImpl : ProductDao {
// class body here...
}<beans>
<!-- Exception translation bean post processor -->
<bean class="org.springframework.dao.annotation.PersistenceExceptionTranslationPostProcessor"/>
<bean id="myProductDao" class="product.ProductDaoImpl"/>
</beans>后处理器会自动查找所有异常转换器(
接口)并通知所有标有 Comments 的 bean,以便发现的翻译者可以拦截并应用
对引发的异常进行适当的翻译。PersistenceExceptionTranslator@Repository
总之,您可以基于普通持久化技术的 API 和 注解,同时仍然受益于 Spring 管理的事务、依赖性 injection 和透明异常转换(如果需要)到 Spring 的自定义 异常层次结构。
5.3. 休眠
我们首先在 Spring 环境中介绍 Hibernate 5, 使用它来演示 Spring 集成 OR 映射器所采用的方法。 本节详细介绍了许多问题,并展示了 DAO 的不同变体 实现和事务划分。这些模式中的大多数可以直接 转换为所有其他支持的 ORM 工具。然后,本章后面的章节 介绍其他 ORM 技术并显示简要示例。
从 Spring Framework 5.3 开始,Spring 需要 Hibernate ORM 5.2+ 用于 Spring 以及本机 Hibernate 设置。
对于新启动的应用程序,强烈建议使用 Hibernate ORM 5.4。
要与 一起使用,Hibernate Search 需要升级到 5.11.6。HibernateJpaVendorAdapterSessionFactoryHibernateJpaVendorAdapter |
5.3.1. 在 Spring 容器中设置SessionFactory
为避免将应用程序对象绑定到硬编码的资源查找,您可以定义
资源(例如 JDBC 或 Hibernate )作为 bean 中的
Spring 容器。需要访问资源的应用程序对象接收引用
通过 bean 引用传递给此类预定义实例,如 DAO 中所示
定义。DataSourceSessionFactory
以下摘自 XML 应用程序上下文定义的部分显示了如何设置
JDBC 和它之上的 Hibernate:DataSourceSessionFactory
<beans>
<bean id="myDataSource" class="org.apache.commons.dbcp.BasicDataSource" destroy-method="close">
<property name="driverClassName" value="org.hsqldb.jdbcDriver"/>
<property name="url" value="jdbc:hsqldb:hsql://localhost:9001"/>
<property name="username" value="sa"/>
<property name="password" value=""/>
</bean>
<bean id="mySessionFactory" class="org.springframework.orm.hibernate5.LocalSessionFactoryBean">
<property name="dataSource" ref="myDataSource"/>
<property name="mappingResources">
<list>
<value>product.hbm.xml</value>
</list>
</property>
<property name="hibernateProperties">
<value>
hibernate.dialect=org.hibernate.dialect.HSQLDialect
</value>
</property>
</bean>
</beans>从本地 Jakarta Commons DBCP 切换到位于 JNDI 的位置(通常由应用程序服务器管理)只是一个问题
配置,如下例所示:BasicDataSourceDataSource
<beans>
<jee:jndi-lookup id="myDataSource" jndi-name="java:comp/env/jdbc/myds"/>
</beans>您还可以使用 Spring 的 / 访问位于 JNDI 的位置来检索和公开它。
但是,这在 EJB 上下文之外通常并不常见。SessionFactoryJndiObjectFactoryBean<jee:jndi-lookup>
|
Spring 还提供了一个 variant,无缝集成
使用样式配置和编程设置(不涉及)。 两者和支持背景
引导,Hibernate 初始化与应用程序并行运行
给定 bootstrap 执行程序(如 a )上的 bootstrap 线程。
在 上,这可以通过属性获得。在 programmatic 上,有一个采用 bootstrap executor 参数的重载方法。 从 Spring Framework 5.1 开始,这种本机 Hibernate 设置还可以在本机 Hibernate 访问旁边公开用于标准 JPA 交互的 JPA。
有关详细信息,请参阅 JPA 的本机 Hibernate 设置。 |
5.3.2. 基于普通 Hibernate API 实现 DAO
Hibernate 有一个称为上下文会话的功能,其中 Hibernate 自己管理
每笔交易 1 个 current。这大致相当于 Spring 的
每个事务同步一个 Hibernate。相应的 DAO
实现类似于以下示例,基于普通的 Hibernate API:SessionSession
public class ProductDaoImpl implements ProductDao {
private SessionFactory sessionFactory;
public void setSessionFactory(SessionFactory sessionFactory) {
this.sessionFactory = sessionFactory;
}
public Collection loadProductsByCategory(String category) {
return this.sessionFactory.getCurrentSession()
.createQuery("from test.Product product where product.category=?")
.setParameter(0, category)
.list();
}
}class ProductDaoImpl(private val sessionFactory: SessionFactory) : ProductDao {
fun loadProductsByCategory(category: String): Collection<*> {
return sessionFactory.currentSession
.createQuery("from test.Product product where product.category=?")
.setParameter(0, category)
.list()
}
}这种风格类似于 Hibernate 参考文档和示例的风格。
除了持有 in an instance 变量。我们强烈建议
这种基于实例的设置,而不是 old-school 类
Hibernate 的 CaveatEmptor 示例应用程序。(通常,除非绝对必要,否则不要在 variables 中保留任何资源。SessionFactorystaticHibernateUtilstatic
前面的 DAO 示例遵循依赖关系注入模式。它非常适合 Spring IoC
container 的 .
您还可以在纯 Java 中设置这样的 DAO(例如,在单元测试中)。为此,
实例化它并使用所需的 Factory Reference.作为
Spring bean 定义,DAO 将类似于以下内容:HibernateTemplatesetSessionFactory(..)
<beans>
<bean id="myProductDao" class="product.ProductDaoImpl">
<property name="sessionFactory" ref="mySessionFactory"/>
</bean>
</beans>这种 DAO 风格的主要优点是它只依赖于 Hibernate API。无导入 的 Spring 类是必需的。这是非侵入性的吸引力 视角,并且对于 Hibernate 开发人员来说可能感觉更自然。
但是,DAO 会抛出 plain (这是未选中的,因此它没有
被声明或捕获),这意味着调用者只能将异常视为
通常是致命的 — 除非他们想依赖 Hibernate 自己的异常层次结构。
如果没有
将调用方绑定到 implementation strategy。这种权衡可能是可以接受的
强基于 Hibernate 的应用程序不需要任何特殊例外
治疗,或两者兼而有之。HibernateException
幸运的是,Spring 支持任何 Spring 事务策略的 Hibernate 方法,
返回当前 Spring 管理的 transactional ,即使使用 .该方法的标准行为保持不变
返回与正在进行的 JTA 事务关联的 current (如果有)。
无论您使用的是 Spring、EJB 容器管理事务 (CMT) 还是 JTA,此行为都适用。LocalSessionFactoryBeanSessionFactory.getCurrentSession()SessionHibernateTransactionManagerSessionJtaTransactionManager
总之,您可以基于普通的 Hibernate API 实现 DAO,同时仍然保持 能够参与 Spring 管理的事务。
5.3.3. 声明式事务划分
我们建议您使用 Spring 的声明式事务支持,它允许您 将 Java 代码中的显式事务划分 API 调用替换为 AOP 交易拦截器。您可以在 Spring 中配置此事务拦截器 container 结合使用。此声明式事务功能 让您保持业务服务没有重复的事务划分代码,并且 专注于添加业务逻辑,这是应用程序的真正价值。
| 在继续之前,我们强烈建议您阅读 Declarative Transaction Management(如果您还没有阅读)。 |
您可以使用注释注释来注释服务层,并指示
Spring 容器来查找这些注解并为
这些带注释的方法。以下示例显示了如何执行此操作:@Transactional
public class ProductServiceImpl implements ProductService {
private ProductDao productDao;
public void setProductDao(ProductDao productDao) {
this.productDao = productDao;
}
@Transactional
public void increasePriceOfAllProductsInCategory(final String category) {
List productsToChange = this.productDao.loadProductsByCategory(category);
// ...
}
@Transactional(readOnly = true)
public List<Product> findAllProducts() {
return this.productDao.findAllProducts();
}
}class ProductServiceImpl(private val productDao: ProductDao) : ProductService {
@Transactional
fun increasePriceOfAllProductsInCategory(category: String) {
val productsToChange = productDao.loadProductsByCategory(category)
// ...
}
@Transactional(readOnly = true)
fun findAllProducts() = productDao.findAllProducts()
}在容器中,您需要设置实现
(作为 Bean)和一个条目,选择在运行时进行处理。以下示例显示了如何执行此操作:PlatformTransactionManager<tx:annotation-driven/>@Transactional
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx
https://www.springframework.org/schema/tx/spring-tx.xsd
http://www.springframework.org/schema/aop
https://www.springframework.org/schema/aop/spring-aop.xsd">
<!-- SessionFactory, DataSource, etc. omitted -->
<bean id="transactionManager"
class="org.springframework.orm.hibernate5.HibernateTransactionManager">
<property name="sessionFactory" ref="sessionFactory"/>
</bean>
<tx:annotation-driven/>
<bean id="myProductService" class="product.SimpleProductService">
<property name="productDao" ref="myProductDao"/>
</bean>
</beans>5.3.4. 程序化事务划分
您可以在应用程序的更高级别中划分事务,除了
跨任意数量的操作的较低级别数据访问服务。限制也没有
存在于周围业务服务的实现中。它只需要一个 Spring .同样,后者可以来自任何地方,但最好是
作为 bean 引用。此外,应该由方法设置。以下代码段对显示
Spring 应用程序上下文中的事务管理器和业务服务定义
以及一个业务方法实现的示例:PlatformTransactionManagersetTransactionManager(..)productDAOsetProductDao(..)
<beans>
<bean id="myTxManager" class="org.springframework.orm.hibernate5.HibernateTransactionManager">
<property name="sessionFactory" ref="mySessionFactory"/>
</bean>
<bean id="myProductService" class="product.ProductServiceImpl">
<property name="transactionManager" ref="myTxManager"/>
<property name="productDao" ref="myProductDao"/>
</bean>
</beans>public class ProductServiceImpl implements ProductService {
private TransactionTemplate transactionTemplate;
private ProductDao productDao;
public void setTransactionManager(PlatformTransactionManager transactionManager) {
this.transactionTemplate = new TransactionTemplate(transactionManager);
}
public void setProductDao(ProductDao productDao) {
this.productDao = productDao;
}
public void increasePriceOfAllProductsInCategory(final String category) {
this.transactionTemplate.execute(new TransactionCallbackWithoutResult() {
public void doInTransactionWithoutResult(TransactionStatus status) {
List productsToChange = this.productDao.loadProductsByCategory(category);
// do the price increase...
}
});
}
}class ProductServiceImpl(transactionManager: PlatformTransactionManager,
private val productDao: ProductDao) : ProductService {
private val transactionTemplate = TransactionTemplate(transactionManager)
fun increasePriceOfAllProductsInCategory(category: String) {
transactionTemplate.execute {
val productsToChange = productDao.loadProductsByCategory(category)
// do the price increase...
}
}
}Spring 允许引发任何已检查的应用程序异常
替换为回调代码,while 限制为 un选中
exceptions 的 Exceptions 中。 在
未选中的应用程序异常,或者如果事务被标记为仅回滚
应用程序(通过设置 )。默认情况下,其行为方式相同,但允许每个方法的可配置回滚策略。TransactionInterceptorTransactionTemplateTransactionTemplateTransactionStatusTransactionInterceptor
5.3.5. 事务管理策略
Both 和 delegate 实际事务
处理到实例(可以是(对于单个 Hibernate ),通过在后台使用 a)或 a(委托给
JTA 子系统)用于 Hibernate 应用程序。您甚至可以使用自定义实现。从本机 Hibernate 事务切换
management 到 JTA(例如,当面对某些
deployments)只是一个配置问题。您可以将
Hibernate 事务管理器与 Spring 的 JTA 事务实现。双
事务划分和数据访问代码无需更改即可工作,因为它们
使用通用事务管理 API。TransactionTemplateTransactionInterceptorPlatformTransactionManagerHibernateTransactionManagerSessionFactoryThreadLocalSessionJtaTransactionManagerPlatformTransactionManager
对于跨多个 Hibernate 会话工厂的分布式事务,你可以作为具有多个定义的事务策略进行组合。然后,每个 DAO 都会获得一个传递到其相应 bean 属性中的特定引用。如果所有底层 JDBC 数据
源是事务性容器源,业务服务可以划分事务
在任意数量的 DAO 和任意数量的会话工厂中,没有特别考虑,作为
只要它用作策略。JtaTransactionManagerLocalSessionFactoryBeanSessionFactoryJtaTransactionManager
两者兼而有之,并允许适当的
使用 Hibernate 进行 JVM 级缓存处理,无需特定于容器的事务管理器
lookup 或 JCA 连接器(如果您不使用 EJB 启动事务)。HibernateTransactionManagerJtaTransactionManager
HibernateTransactionManager可以将 Hibernate JDBC 导出为普通 JDBC
特定 .此功能允许高级
混合 Hibernate 和 JDBC 数据访问的事务划分完全无需
JTA,前提是您只访问一个数据库。 自然而然
将 Hibernate 事务公开为 JDBC 事务,如果你已经使用 class 的 through 属性设置了传入的事务。或者,您可以通过类的属性显式指定应该公开事务的 the。ConnectionDataSourceHibernateTransactionManagerSessionFactoryDataSourcedataSourceLocalSessionFactoryBeanDataSourcedataSourceHibernateTransactionManager
5.3.6. 比较容器管理和本地定义的资源
您可以在容器管理的 JNDI 和本地定义的 JNDI 之间切换
一个,而无需更改任何一行应用程序代码。是否保留
容器中或应用程序本地的资源定义主要是
与您使用的事务策略有关。与 Spring-defined local 相比,手动注册的 JNDI 不提供任何
好处。通过 Hibernate 的 JCA 连接器部署提供了
参与 Java EE 服务器的管理基础架构的附加价值,但确实
不在此之后增加实际价值。SessionFactorySessionFactorySessionFactorySessionFactory
Spring 的事务支持未绑定到容器。当配置了任何策略时
除了 JTA 之外,事务支持还可以在独立或测试环境中工作。
特别是在单数据库事务的典型情况下, Spring 的单资源
本地事务支持是 JTA 的轻量级且功能强大的替代方案。当您使用
本地 EJB 无状态会话 bean 来驱动事务,则您都依赖于 EJB
容器和 JTA 上,即使您只访问单个数据库并且仅使用无状态
会话 Bean 通过容器管理的
交易。以编程方式直接使用 JTA 还需要 Java EE 环境。
JTA 不仅涉及 JTA 本身和
JNDI 实例。对于非 Spring、JTA 驱动的 Hibernate 事务,您有
使用 Hibernate JCA 连接器或额外的 Hibernate 事务代码,并配置适当的 JVM 级缓存。DataSourceTransactionManagerLookup
Spring 驱动的事务可以与本地定义的 Hibernate 一起工作,就像它们与本地 JDBC 一样,前提是它们访问
单个数据库。因此,当您
有分布式事务需求。JCA 连接器需要特定于容器的
部署步骤,以及(显然)首先是 JCA 支持。此配置
比使用本地资源部署简单的 Web 应用程序需要更多的工作
定义和 Spring 驱动的事务。此外,您经常需要 Enterprise Edition
如果您使用的 WebLogic Express 等,则不会
提供 JCA。具有本地资源和跨 1 的事务的 Spring 应用程序
single 数据库可以在任何 Java EE Web 容器(没有 JTA、JCA 或 EJB)中使用,例如
Tomcat、Resin 甚至普通的 Jetty。此外,您可以轻松地重复使用这样的中间
层。SessionFactoryDataSource
考虑到所有因素,如果您不使用 EJB,请坚持使用本地设置
和 Spring 的 或 .您将获得所有
好处,包括适当的事务性 JVM 级缓存和分布式
事务,没有容器部署的不便。JNDI 注册
通过 JCA 连接器进行的休眠仅在用于
与 EJB 结合使用。SessionFactoryHibernateTransactionManagerJtaTransactionManagerSessionFactory
5.3.7. Hibernate 的虚假应用服务器警告
在一些具有非常严格实现的 JTA 环境中(目前
某些 WebLogic Server 和 WebSphere 版本),当 Hibernate 配置为没有
关于该环境的 JTA 事务管理器、虚假警告或
异常可以显示在 Application Server 日志中。这些警告或例外
指示正在访问的连接不再有效或 JDBC 访问为 NO
不再有效,可能是因为事务不再有效。例如,
以下是 WebLogic 的实际异常:XADataSource
java.sql.SQLException: The transaction is no longer active - status: 'Committed'. No further JDBC access is allowed within this transaction.
另一个常见的问题是 JTA 事务后的连接泄漏,使用 Hibernate sessions(以及可能的基础 JDBC 连接)未正确关闭。
您可以通过让 Hibernate 识别 JTA 事务管理器来解决此类问题。 它与它同步(与 Spring 一起)。您有两种选择来执行此操作:
-
将 Spring bean 传递给 Hibernate 设置。最简单的 way 是 bean 属性的 bean 引用(参见 Hibernate Transaction Setup)。 然后,Spring 将相应的 JTA 策略提供给 Hibernate。
JtaTransactionManagerjtaTransactionManagerLocalSessionFactoryBean -
你也可以显式地配置 Hibernate 的 JTA 相关属性,特别是 “hibernate.transaction.coordinator_class”、“hibernate.connection.handling_mode” 以及 “hibernateProperties” 中可能出现的 “hibernate.transaction.jta.platform” on(有关这些属性的详细信息,请参见 Hibernate 的手册)。
LocalSessionFactoryBean
本节的其余部分描述了使用 和 发生的事件序列
没有 Hibernate 对 JTA 的认知。PlatformTransactionManager
当 Hibernate 未配置任何 JTA 事务管理器时, 提交 JTA 事务时,将发生以下事件:
-
JTA 事务提交。
-
Spring 的与 JTA 事务同步,因此它是 通过 JTA 事务管理器的回调回调。
JtaTransactionManagerafterCompletion -
在其他活动中,此同步可以触发 Spring 对 Hibernate,通过 Hibernate 的回调(用于清除 Hibernate 缓存),然后对 Hibernate 会话进行显式调用, 这会导致 Hibernate 尝试 JDBC Connection。
afterTransactionCompletionclose()close() -
在某些环境中,此调用会触发警告或 错误,因为应用程序服务器不再认为 可用, ,因为事务已经提交。
Connection.close()Connection
当 Hibernate 配置了 JTA 事务管理器时, 提交 JTA 事务时,将发生以下事件:
-
JTA 事务已准备好提交。
-
Spring 的 与 JTA 事务同步,因此 transaction 通过 JTA 的回调回调 事务管理器。
JtaTransactionManagerbeforeCompletion -
Spring 知道 Hibernate 本身与 JTA 事务同步,并且 的行为与上一个场景中的行为不同。特别是,它与 Hibernate 的事务性资源管理。
-
JTA 事务提交。
-
Hibernate 与 JTA 事务同步,因此该事务被回调 通过 JTA 事务管理器的回调,并且可以 正确清除其缓存。
afterCompletion
5.4. 日JPA
该软件包下提供的 Spring JPA 提供
对 Java 持久性的全面支持
API 以类似于与 Hibernate 集成的方式进行,同时了解
底层实现,以便提供额外的功能。org.springframework.orm.jpa
5.4.1. 在 Spring 环境中设置 JPA 的三个选项
Spring JPA 支持提供了三种设置 JPA 的方法,应用程序使用该 JPA 来获取实体管理器。EntityManagerFactory
用LocalEntityManagerFactoryBean
您只能在简单的部署环境(如独立部署环境)中使用此选项 应用程序和集成测试。
创建适合
应用程序仅使用 JPA 进行数据访问的简单部署环境。
工厂 Bean 使用 JPA 自动检测机制(根据
添加到 JPA 的 Java SE 引导),并且在大多数情况下,要求您仅指定
持久性单元名称。下面的 XML 示例配置了这样的 bean:LocalEntityManagerFactoryBeanEntityManagerFactoryPersistenceProvider
<beans>
<bean id="myEmf" class="org.springframework.orm.jpa.LocalEntityManagerFactoryBean">
<property name="persistenceUnitName" value="myPersistenceUnit"/>
</bean>
</beans>这种形式的 JPA 部署是最简单且最有限的。您不能引用
现有的 JDBC bean 定义,并且不支持全局事务
存在。此外,持久化类的编织(字节码转换)是
特定于提供程序,通常需要在启动时指定特定的 JVM 代理。这
选项仅适用于独立应用程序和测试环境,对于这些应用程序和测试环境
设计了 JPA 规范。DataSource
从 JNDI 获取 EntityManagerFactory
部署到 Java EE 服务器时,可以使用此选项。查看服务器的文档 了解如何将自定义 JPA 提供程序部署到您的服务器中,从而允许不同的 provider 而不是服务器的默认值。
从 JNDI 获取 (例如在 Java EE 环境中),
是更改 XML 配置的问题,如下例所示:EntityManagerFactory
<beans>
<jee:jndi-lookup id="myEmf" jndi-name="persistence/myPersistenceUnit"/>
</beans>此操作假定标准 Java EE 引导。Java EE 服务器自动检测
持久性单元(实际上是应用程序 jar 中的文件)和 Java EE 部署描述符中的条目(例如),并定义这些持久性单元的环境命名上下文位置。META-INF/persistence.xmlpersistence-unit-refweb.xml
在这种情况下,整个持久化单元部署,包括编织
(字节码转换)的持久化类,则取决于 Java EE 服务器。JDBC 是通过文件中的 JNDI 位置定义的。 事务与服务器的 JTA 子系统集成。仅 Spring
使用获取的 ,通过
持久性单元的依赖关系注入和管理事务(通常
通过 )。DataSourceMETA-INF/persistence.xmlEntityManagerEntityManagerFactoryJtaTransactionManager
如果在同一应用程序中使用多个持久性单元,则此类
JNDI 检索到的持久性单元应与
application 用于引用它们(例如,IN 和 Annotations)。@PersistenceUnit@PersistenceContext
用LocalContainerEntityManagerFactoryBean
您可以在基于 Spring 的应用程序环境中使用此选项来获得完整的 JPA 功能。 这包括 Web 容器(如 Tomcat)、独立应用程序以及 具有复杂持久性要求的集成测试。
如果您想专门配置 Hibernate 设置,则立即选择一种
是设置本机 Hibernate 而不是普通的 JPA,让它与 JPA 访问代码交互
以及本机 Hibernate 访问代码。
有关详细信息,请参阅 JPA 交互的本机 Hibernate 设置。LocalSessionFactoryBeanLocalContainerEntityManagerFactoryBean |
可以完全控制配置,适用于满足以下条件的环境
需要精细的自定义。将基于文件创建一个实例,
提供的策略和指定的 .因此,
可以在 JNDI 之外使用自定义数据源并控制编织
过程。以下示例显示了 a 的典型 bean 定义:LocalContainerEntityManagerFactoryBeanEntityManagerFactoryLocalContainerEntityManagerFactoryBeanPersistenceUnitInfopersistence.xmldataSourceLookuploadTimeWeaverLocalContainerEntityManagerFactoryBean
<beans>
<bean id="myEmf" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="dataSource" ref="someDataSource"/>
<property name="loadTimeWeaver">
<bean class="org.springframework.instrument.classloading.InstrumentationLoadTimeWeaver"/>
</property>
</bean>
</beans>以下示例显示了一个典型文件:persistence.xml
<persistence xmlns="http://java.sun.com/xml/ns/persistence" version="1.0">
<persistence-unit name="myUnit" transaction-type="RESOURCE_LOCAL">
<mapping-file>META-INF/orm.xml</mapping-file>
<exclude-unlisted-classes/>
</persistence-unit>
</persistence>该快捷方式表示不扫描
带注释的实体类应该出现。显式的 'true' 值
() 也表示不扫描。 会触发扫描。
但是,我们建议省略元素
如果您希望进行实体类扫描。<exclude-unlisted-classes/><exclude-unlisted-classes>true</exclude-unlisted-classes/><exclude-unlisted-classes>false</exclude-unlisted-classes/>exclude-unlisted-classes |
使用 是最强大的 JPA 设置
选项,允许在应用程序内进行灵活的本地配置。它支持
链接到现有 JDBC ,支持本地和全局事务,并且
等等。但是,它也对运行时环境提出了要求,例如
如果持久性提供程序需要,则提供支持 Weaving 的类加载器的可用性
字节码转换。LocalContainerEntityManagerFactoryBeanDataSource
此选项可能与 Java EE 服务器的内置 JPA 功能冲突。在
完整的 Java EE 环境,请考虑从 JNDI 获取 YOUR 。
或者,在定义中指定自定义(例如
META-INF/my-persistence.xml),并在
应用程序 jar 文件。由于 Java EE 服务器仅查找默认文件,因此它会忽略此类自定义持久性单元,因此,
避免与 Spring 驱动的 JPA 预先设置冲突。(这适用于 Resin 3.1,用于
示例。EntityManagerFactorypersistenceXmlLocationLocalContainerEntityManagerFactoryBeanMETA-INF/persistence.xml
该接口是 Spring 提供的类,它允许以特定方式插入 JPA 实例,具体取决于
environment 是 Web 容器或应用程序服务器。通过代理程序进行挂钩通常效率不高。代理针对整个虚拟机工作,并且
检查加载的每个类,这在生产中通常是不可取的
服务器环境。LoadTimeWeaverClassTransformerClassTransformers
Spring 为各种环境提供了许多实现,
让实例仅应用于每个类加载器,而不是
对于每个 VM。LoadTimeWeaverClassTransformer
请参阅 AOP 章节中的 Spring 配置
有关实施及其设置的更多见解
通用或针对各种平台(如 Tomcat、JBoss 和 WebSphere)进行定制。LoadTimeWeaver
如 Spring 配置中所述,您可以配置
使用 annotation 或 XML 元素进行上下文范围的调用。这样的全局 weaver 会自动被选中
按所有 JPA 实例。以下示例
显示设置加载时编织机的首选方法,提供自动检测
平台(例如 Tomcat 的具有 weaving 功能的类加载器或 Spring 的 JVM 代理)
以及将 Weaver 自动传播到所有可识别 Weaver 的 bean:LoadTimeWeaver@EnableLoadTimeWeavingcontext:load-time-weaverLocalContainerEntityManagerFactoryBean
<context:load-time-weaver/>
<bean id="emf" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
...
</bean>但是,如果需要,您可以通过该属性手动指定专用编织器,如下例所示:loadTimeWeaver
<bean id="emf" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="loadTimeWeaver">
<bean class="org.springframework.instrument.classloading.ReflectiveLoadTimeWeaver"/>
</property>
</bean>无论 LTW 是如何配置的,通过使用这种技术,依赖于 插桩可以在目标平台(例如 Tomcat)中运行,而无需代理。 当托管应用程序依赖于不同的 JPA 时,这一点尤其重要 实现,因为 JPA 转换器只应用于类加载器级别,而 因此,彼此隔离。
处理多个持久性单元
对于依赖多个持久化单元位置(存储在各种
JARS),Spring 提供了 to 作为
中央存储库,并避免 Persistence Units 发现过程,该过程可以是
贵。默认实现允许指定多个位置。这些位置是
解析,然后通过 Persistence Unit Name 检索。(默认情况下,类路径
将搜索文件。以下示例配置
多个地点:PersistenceUnitManagerMETA-INF/persistence.xml
<bean id="pum" class="org.springframework.orm.jpa.persistenceunit.DefaultPersistenceUnitManager">
<property name="persistenceXmlLocations">
<list>
<value>org/springframework/orm/jpa/domain/persistence-multi.xml</value>
<value>classpath:/my/package/**/custom-persistence.xml</value>
<value>classpath*:META-INF/persistence.xml</value>
</list>
</property>
<property name="dataSources">
<map>
<entry key="localDataSource" value-ref="local-db"/>
<entry key="remoteDataSource" value-ref="remote-db"/>
</map>
</property>
<!-- if no datasource is specified, use this one -->
<property name="defaultDataSource" ref="remoteDataSource"/>
</bean>
<bean id="emf" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="persistenceUnitManager" ref="pum"/>
<property name="persistenceUnitName" value="myCustomUnit"/>
</bean>默认实现允许自定义实例
(在它们被提供给 JPA 提供程序之前)要么声明地(通过其属性,要么
影响所有托管单位)或编程方式(通过 ,允许选择持久性单位)。如果未指定 no,则创建一个 .PersistenceUnitInfoPersistenceUnitPostProcessorPersistenceUnitManagerLocalContainerEntityManagerFactoryBean
后台引导
LocalContainerEntityManagerFactoryBean支持后台引导
该属性,如下例所示:bootstrapExecutor
<bean id="emf" class="org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean">
<property name="bootstrapExecutor">
<bean class="org.springframework.core.task.SimpleAsyncTaskExecutor"/>
</property>
</bean>实际的 JPA 提供程序引导将移交给指定的执行程序,然后
并行运行,以执行应用程序引导线程。公开的代理可以注入到其他应用程序组件中,甚至能够响应配置检查。但是,一旦实际的 JPA 提供程序
正在被其他组件访问(例如,调用 ),这些调用
阻止,直到后台引导完成。特别是,当您使用
Spring Data JPA,请确保还为其存储库设置延迟引导。EntityManagerFactoryEntityManagerFactoryInfocreateEntityManager
5.4.2. 基于 JPA 实现 DAO:和EntityManagerFactoryEntityManager
尽管实例是线程安全的,但实例是
不。注入的 JPA 的行为类似于从
应用程序服务器的 JNDI 环境,如 JPA 规范所定义。它委派
对当前 transactional 的所有调用(如果有)。否则,它会回退
添加到新创建的 per 操作中,实际上使其使用线程安全。EntityManagerFactoryEntityManagerEntityManagerEntityManagerEntityManagerEntityManager |
可以针对普通 JPA 编写代码,而没有任何 Spring 依赖项,方法是
使用注入的 或 .Spring 可以在字段和方法级别理解 and 注解
如果启用了 A。以下示例显示了一个普通的 JPA DAO 实现
,它使用注解:EntityManagerFactoryEntityManager@PersistenceUnit@PersistenceContextPersistenceAnnotationBeanPostProcessor@PersistenceUnit
public class ProductDaoImpl implements ProductDao {
private EntityManagerFactory emf;
@PersistenceUnit
public void setEntityManagerFactory(EntityManagerFactory emf) {
this.emf = emf;
}
public Collection loadProductsByCategory(String category) {
EntityManager em = this.emf.createEntityManager();
try {
Query query = em.createQuery("from Product as p where p.category = ?1");
query.setParameter(1, category);
return query.getResultList();
}
finally {
if (em != null) {
em.close();
}
}
}
}class ProductDaoImpl : ProductDao {
private lateinit var emf: EntityManagerFactory
@PersistenceUnit
fun setEntityManagerFactory(emf: EntityManagerFactory) {
this.emf = emf
}
fun loadProductsByCategory(category: String): Collection<*> {
val em = this.emf.createEntityManager()
val query = em.createQuery("from Product as p where p.category = ?1");
query.setParameter(1, category);
return query.resultList;
}
}前面的 DAO 不依赖于 Spring,并且仍然非常适合 Spring
应用程序上下文。此外,DAO 利用注解来要求
注入默认的 ,如下例 bean 定义所示:EntityManagerFactory
<beans>
<!-- bean post-processor for JPA annotations -->
<bean class="org.springframework.orm.jpa.support.PersistenceAnnotationBeanPostProcessor"/>
<bean id="myProductDao" class="product.ProductDaoImpl"/>
</beans>作为显式定义 的替代方法 ,
考虑在应用程序中使用 Spring XML 元素
context 配置。这样做会自动注册所有 Spring 标准
后处理器 (post-processors) 用于基于注释的配置,包括 等。PersistenceAnnotationBeanPostProcessorcontext:annotation-configCommonAnnotationBeanPostProcessor
请考虑以下示例:
<beans>
<!-- post-processors for all standard config annotations -->
<context:annotation-config/>
<bean id="myProductDao" class="product.ProductDaoImpl"/>
</beans>这种 DAO 的主要问题是它总是创建一个新的
工厂。您可以通过请求事务性(以及
称为“共享 EntityManager”,因为它是实际
transactional EntityManager)而不是工厂。以下示例显示了如何执行此操作:EntityManagerEntityManager
public class ProductDaoImpl implements ProductDao {
@PersistenceContext
private EntityManager em;
public Collection loadProductsByCategory(String category) {
Query query = em.createQuery("from Product as p where p.category = :category");
query.setParameter("category", category);
return query.getResultList();
}
}class ProductDaoImpl : ProductDao {
@PersistenceContext
private lateinit var em: EntityManager
fun loadProductsByCategory(category: String): Collection<*> {
val query = em.createQuery("from Product as p where p.category = :category")
query.setParameter("category", category)
return query.resultList
}
}该批注具有一个名为 的可选属性,该属性默认为 。您可以使用此默认值来接收共享代理。替代项 , 是完全的
不同的事件。这导致了所谓的扩展 ,它不是
线程安全的,因此,不得在并发访问的组件中使用,例如
Spring 管理的单例 bean。扩展实例只应在
有状态组件,例如,驻留在 session 中,其生命周期不与当前事务绑定,而是完全取决于
应用。@PersistenceContexttypePersistenceContextType.TRANSACTIONEntityManagerPersistenceContextType.EXTENDEDEntityManagerEntityManagerEntityManager
注入的 is 由 Spring 管理的(知道正在进行的事务)。
即使新的 DAO 实现使用方法级
注入 an 而不是 an ,没有变化是
由于注释的使用,在应用程序上下文 XML 中是必需的。EntityManagerEntityManagerEntityManagerFactory
这种 DAO 风格的主要优点是它仅依赖于 Java 持久性 API。 不需要导入任何 Spring 类。此外,正如 JPA 注释所理解的那样, 注入由 Spring 容器自动应用。这很吸引人 非侵入性视角,对于 JPA 开发人员来说可能感觉更自然。
5.4.3. Spring 驱动的 JPA 事务
| 如果您还没有阅读,我们强烈建议您阅读声明式事务管理 已经这样做了,以获得 Spring 的声明式事务支持的更详细介绍。 |
JPA 的推荐策略是通过 JPA 的本机事务进行本地事务处理
支持。Spring 提供了许多已知于本地
JDBC 事务(例如特定于事务的隔离级别和资源级别的
read-only optimizations) 针对任何常规 JDBC 连接池(无 XA 要求)。JpaTransactionManager
Spring JPA 还允许配置的 JPA 事务
添加到访问相同 的 JDBC 访问代码中,前提是已注册支持检索底层 JDBC 。
Spring 为 EclipseLink 和 Hibernate JPA 实现提供了方言。
有关机制的详细信息,请参阅下一节。JpaTransactionManagerDataSourceJpaDialectConnectionJpaDialect
作为直接的替代方案,Spring 的 native 是 capable
与 JPA 访问代码交互,适应多个 Hibernate 细节并提供
JDBC 交互。这与 setup 结合使用特别有意义。有关详细信息,请参阅 JPA 交互的本机 Hibernate 设置。HibernateTransactionManagerLocalSessionFactoryBean |
5.4.4. 理解和JpaDialectJpaVendorAdapter
作为高级功能, 和 子类 允许将自定义传递到 bean 属性中。实施可以启用以下高级
Spring 支持的功能,通常以特定于供应商的方式:JpaTransactionManagerAbstractEntityManagerFactoryBeanJpaDialectjpaDialectJpaDialect
-
应用特定的事务语义(例如自定义隔离级别或事务 超时)
-
检索事务性 JDBC(用于向基于 JDBC 的 DAO 公开)
Connection -
到 Spring 的高级翻译
PersistenceExceptionDataAccessException
这对于特殊事务语义和高级
exception 的翻译。默认实现 () 会
不提供任何特殊功能,并且如果需要前面列出的功能,则您具有
以指定适当的方言。DefaultJpaDialect
作为一个更广泛的提供程序适配工具,主要针对 Spring 的全功能设置,它结合了
功能。指定 or 是最方便的
为 Hibernate 或 EclipseLink 自动配置设置的方式,
分别。请注意,这些提供程序适配器主要设计用于
Spring 驱动的事务管理(即,用于)。LocalContainerEntityManagerFactoryBeanJpaVendorAdapterJpaDialectHibernateJpaVendorAdapterEclipseLinkJpaVendorAdapterEntityManagerFactoryJpaTransactionManager |
请参阅 JpaDialect 和 JpaVendorAdapter javadoc 以获取
有关其操作的更多详细信息以及如何在 Spring 的 JPA 支持中使用它们。
5.4.5. 使用 JTA Transaction Management 设置 JPA
作为 的替代方法,Spring 还允许使用多资源
通过 JTA 进行事务协调,无论是在 Java EE 环境中还是使用
独立的事务协调器,例如 Atomikos。除了选择 Spring's 而不是 之外,您还需要更进一步
步骤:JpaTransactionManagerJtaTransactionManagerJpaTransactionManager
-
底层 JDBC 连接池需要支持 XA,并与 您的交易协调器。这在 Java EE 环境中通常很简单。 通过 JNDI 公开不同类型的 。查看您的应用程序服务器 documentation 了解详细信息。类似地,独立的事务协调器通常 带有特殊的 XA 集成变体。同样,请查看其文档。
DataSourceDataSource -
需要为 JTA 配置 JPA 设置。这是 特定于提供程序,通常通过特殊属性指定为 on 。在 Hibernate 的情况下,这些属性 甚至特定于版本。有关详细信息,请参阅 Hibernate 文档。
EntityManagerFactoryjpaPropertiesLocalContainerEntityManagerFactoryBean -
Spring 强制执行某些面向 Spring 的默认值,例如 作为连接释放模式,它与 Hibernate 自己在 Hibernate 5.0 版本,但在 Hibernate 5.1+ 中不再运行。对于 JTA 设置,请确保声明 您的 Persistence Unit 事务类型为 “JTA”。或者,将 Hibernate 5.2 的属性设置为以恢复 Hibernate 自己的默认值。 有关相关说明,请参阅 Spurious Application Server Warnings with Hibernate。
HibernateJpaVendorAdapteron-closehibernate.connection.handling_modeDELAYED_ACQUISITION_AND_RELEASE_AFTER_STATEMENT -
或者,考虑从您的应用程序中获取 server 本身(即,通过 JNDI 查找而不是 local declaration )。server-provided 可能需要在服务器配置中进行特殊定义(进行部署 不太可移植),但针对服务器的 JTA 环境进行了设置。
EntityManagerFactoryLocalContainerEntityManagerFactoryBeanEntityManagerFactory
5.4.6. 用于 JPA 交互的原生 Hibernate 设置和原生 Hibernate 事务
本机设置与 允许与其他 JPA 访问代码进行交互。Hibernate 现在原生实现了 JPA 的接口
Hibernate 句柄本身是 JPA 。
Spring 的 JPA 支持工具会自动检测本机 Hibernate 会话。LocalSessionFactoryBeanHibernateTransactionManager@PersistenceContextSessionFactoryEntityManagerFactorySessionEntityManager
因此,这种原生 Hibernate 设置可以替代标准 JPA 和组合
在许多情况下,允许与 (以及 ) 在 Within 之间进行交互
相同的本地事务。这样的设置还提供了更强的 Hibernate 集成
以及更大的配置灵活性,因为它不受 JPA 引导契约的约束。LocalContainerEntityManagerFactoryBeanJpaTransactionManagerSessionFactory.getCurrentSession()HibernateTemplate@PersistenceContext EntityManager
在这种情况下,您不需要配置,
因为 Spring 的原生 Hibernate 设置提供了更多功能
(例如,自定义 Hibernate Integrator 设置、Hibernate 5.3 Bean 容器集成、
以及对只读事务的更强优化)。最后但并非最不重要的一点是,您还可以
express native Hibernate 设置,通过 ,
与 style configuration 无缝集成(不涉及)。HibernateJpaVendorAdapterLocalSessionFactoryBuilder@BeanFactoryBean
|
在 上,这可以通过属性获得。在 programmatic 上,重载方法采用 bootstrap executor 参数。 |
6. 使用 Object-XML 映射器封送 XML
6.1. 简介
本章描述了 Spring 的 Object-XML Mapping 支持。对象 XML 映射(简称 O-X 映射)是将 XML 文档相互转换的过程 一个对象。此转换过程也称为 XML 封送或 XML 序列化。本章可以互换使用这些术语。
在 O-X 映射领域中,编组器负责序列化 object (graph) 转换为 XML。以类似的方式,解组器将 XML 反序列化为 对象图。此 XML 可以采用 DOM 文档、输入或输出的形式 stream 或 SAX 处理程序。
使用 Spring 满足您的 O/X 映射需求的一些好处是:
6.1.1. 易于配置
Spring 的 bean factory 使配置编组器变得容易,而无需 构造 JAXB 上下文、JiBX 绑定工厂等。您可以配置封送处理程序 就像您在应用程序上下文中的任何其他 bean 一样。此外,基于 XML 命名空间 配置可用于许多编组器,使配置均匀 简单。
6.1.2. 一致的接口
Spring 的 O-X 映射通过两个全局接口运行:Marshaller 和 Unmarshaller。这些抽象允许您切换 O-X 映射框架
相对容易,只需对执行
编组。这种方法还有一个额外的好处,就是可以执行 XML
使用混合匹配方法进行封送(例如,使用 JAXB 执行一些封送处理
还有一些由 XStream 提供),让您使用每个
科技。
6.2. 和MarshallerUnmarshaller
如简介中所述,编组处理程序序列化对象 转换为 XML,并且解组器将 XML 流反序列化为对象。本节介绍 用于此目的的两个 Spring 接口。
6.2.1. 理解Marshaller
Spring 抽象了接口后面的所有编组操作,其主要方法如下:org.springframework.oxm.Marshaller
public interface Marshaller {
/**
* Marshal the object graph with the given root into the provided Result.
*/
void marshal(Object graph, Result result) throws XmlMappingException, IOException;
}该接口有一个 main 方法,该方法将给定对象封送到
鉴于。结果是一个标记接口,基本上
表示 XML 输出抽象。具体实现包装各种 XML
表示形式,如下表所示:Marshallerjavax.xml.transform.Result
| 结果实现 | 包装 XML 表示 |
|---|---|
|
|
|
|
|
|
尽管该方法接受普通对象作为其第一个参数,但大多数实现无法处理任意对象。相反,对象类
必须在映射文件中映射,使用注释进行标记,并使用
marshaller 或具有公共基类。请参阅本章后面的章节
来确定您的 O-X 技术如何管理这一点。marshal()Marshaller |
6.2.2. 理解Unmarshaller
与 类似,我们有 interface ,下面的清单显示了该接口:Marshallerorg.springframework.oxm.Unmarshaller
public interface Unmarshaller {
/**
* Unmarshal the given provided Source into an object graph.
*/
Object unmarshal(Source source) throws XmlMappingException, IOException;
}此接口还有一个方法,该方法从给定的(XML 输入抽象)中读取并返回读取的对象。如
其中 ,是一个具有三个具体实现的标记接口。每
包装不同的 XML 表示形式,如下表所示:javax.xml.transform.SourceResultSource
| 源实现 | 包装 XML 表示 |
|---|---|
|
|
|
|
|
|
即使有两个单独的编组接口( 和 ),Spring-WS 中的所有实现都在一个类中实现。
这意味着您可以连接一个 marshaller 类,并将其同时称为
编组程序和解组程序 .MarshallerUnmarshallerapplicationContext.xml
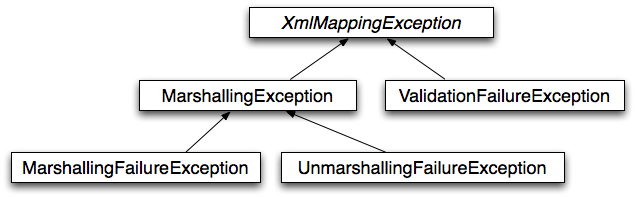
6.3. 使用 和MarshallerUnmarshaller
您可以将 Spring 的 OXM 用于各种情况。在下面的示例中,我们 使用它来将 Spring Management 的应用程序的设置编组为 XML 文件。在下面的示例中,我们 使用一个简单的 JavaBean 来表示设置:
public class Settings {
private boolean fooEnabled;
public boolean isFooEnabled() {
return fooEnabled;
}
public void setFooEnabled(boolean fooEnabled) {
this.fooEnabled = fooEnabled;
}
}class Settings {
var isFooEnabled: Boolean = false
}application 类使用此 bean 来存储其设置。除了 main 方法之外,
类有两种方法:将设置 Bean 保存到名为 的文件中,然后再次加载这些设置。以下方法
构造一个 Spring 应用程序上下文并调用以下两个方法:saveSettings()settings.xmlloadSettings()main()
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import javax.xml.transform.stream.StreamResult;
import javax.xml.transform.stream.StreamSource;
import org.springframework.context.ApplicationContext;
import org.springframework.context.support.ClassPathXmlApplicationContext;
import org.springframework.oxm.Marshaller;
import org.springframework.oxm.Unmarshaller;
public class Application {
private static final String FILE_NAME = "settings.xml";
private Settings settings = new Settings();
private Marshaller marshaller;
private Unmarshaller unmarshaller;
public void setMarshaller(Marshaller marshaller) {
this.marshaller = marshaller;
}
public void setUnmarshaller(Unmarshaller unmarshaller) {
this.unmarshaller = unmarshaller;
}
public void saveSettings() throws IOException {
try (FileOutputStream os = new FileOutputStream(FILE_NAME)) {
this.marshaller.marshal(settings, new StreamResult(os));
}
}
public void loadSettings() throws IOException {
try (FileInputStream is = new FileInputStream(FILE_NAME)) {
this.settings = (Settings) this.unmarshaller.unmarshal(new StreamSource(is));
}
}
public static void main(String[] args) throws IOException {
ApplicationContext appContext =
new ClassPathXmlApplicationContext("applicationContext.xml");
Application application = (Application) appContext.getBean("application");
application.saveSettings();
application.loadSettings();
}
}class Application {
lateinit var marshaller: Marshaller
lateinit var unmarshaller: Unmarshaller
fun saveSettings() {
FileOutputStream(FILE_NAME).use { outputStream -> marshaller.marshal(settings, StreamResult(outputStream)) }
}
fun loadSettings() {
FileInputStream(FILE_NAME).use { inputStream -> settings = unmarshaller.unmarshal(StreamSource(inputStream)) as Settings }
}
}
private const val FILE_NAME = "settings.xml"
fun main(args: Array<String>) {
val appContext = ClassPathXmlApplicationContext("applicationContext.xml")
val application = appContext.getBean("application") as Application
application.saveSettings()
application.loadSettings()
}这需要同时设置 a 和 an 属性。我们
可以使用以下方法执行此操作:ApplicationmarshallerunmarshallerapplicationContext.xml
<beans>
<bean id="application" class="Application">
<property name="marshaller" ref="xstreamMarshaller" />
<property name="unmarshaller" ref="xstreamMarshaller" />
</bean>
<bean id="xstreamMarshaller" class="org.springframework.oxm.xstream.XStreamMarshaller"/>
</beans>此应用程序上下文使用 XStream,但我们可以使用任何其他编组处理程序
实例。请注意,默认情况下,XStream 不需要
任何进一步的配置,因此 bean 定义相当简单。还要注意,这两个 都实现了 和 ,因此我们可以在
应用。XStreamMarshallerMarshallerUnmarshallerxstreamMarshallermarshallerunmarshaller
此示例应用程序生成以下文件:settings.xml
<?xml version="1.0" encoding="UTF-8"?>
<settings foo-enabled="false"/>6.4. XML 配置命名空间
您可以使用 OXM 命名空间中的标记更简洁地配置编组器。 要使这些标记可用,您必须首先在 XML 配置文件的序言。以下示例显示了如何执行此操作:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:oxm="http://www.springframework.org/schema/oxm" (1)
xsi:schemaLocation="http://www.springframework.org/schema/beans
https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/oxm https://www.springframework.org/schema/oxm/spring-oxm.xsd"> (2)| 1 | 引用架构。oxm |
| 2 | 指定架构位置。oxm |
该架构使以下元素可用:
每个标记在其各自的 marshaller's 部分中都有说明。不过,举个例子, JAXB2 编组器的配置可能类似于以下内容:
<oxm:jaxb2-marshaller id="marshaller" contextPath="org.springframework.ws.samples.airline.schema"/>6.5. JAXB
JAXB 绑定编译器将 W3C XML 模式转换为一个或多个 Java 类、一个文件,可能还有一些资源文件。JAXB 还提供了一种
从带注释的 Java 类生成架构。jaxb.properties
Spring 支持 JAXB 2.0 API 作为 XML 编组策略,遵循 Marshaller 和 Unmarshaller 中描述的 and 接口。
相应的集成类位于包中。MarshallerUnmarshallerorg.springframework.oxm.jaxb
6.5.1. 使用Jaxb2Marshaller
该类实现了 Spring 的 和 interfaces。它需要一个上下文路径才能运行。您可以通过设置属性来设置上下文路径。上下文路径是以冒号分隔的 Java 包的列表
包含架构派生类的名称。它还提供了一个属性,
它允许您设置编组器要支持的类数组。图式
通过向 Bean 指定一个或多个模式资源来执行验证,如下例所示:Jaxb2MarshallerMarshallerUnmarshallercontextPathclassesToBeBound
<beans>
<bean id="jaxb2Marshaller" class="org.springframework.oxm.jaxb.Jaxb2Marshaller">
<property name="classesToBeBound">
<list>
<value>org.springframework.oxm.jaxb.Flight</value>
<value>org.springframework.oxm.jaxb.Flights</value>
</list>
</property>
<property name="schema" value="classpath:org/springframework/oxm/schema.xsd"/>
</bean>
...
</beans>XML 配置命名空间
该元素配置一个 ,
如下例所示:jaxb2-marshallerorg.springframework.oxm.jaxb.Jaxb2Marshaller
<oxm:jaxb2-marshaller id="marshaller" contextPath="org.springframework.ws.samples.airline.schema"/>或者,可以使用 child 元素提供要绑定到编组处理程序的类列表:class-to-be-bound
<oxm:jaxb2-marshaller id="marshaller">
<oxm:class-to-be-bound name="org.springframework.ws.samples.airline.schema.Airport"/>
<oxm:class-to-be-bound name="org.springframework.ws.samples.airline.schema.Flight"/>
...
</oxm:jaxb2-marshaller>下表描述了可用属性:
| 属性 | 描述 | 必填 |
|---|---|---|
|
封送处理程序的 ID |
不 |
|
JAXB 上下文路径 |
不 |
6.6. JiBX
JiBX 框架提供了一个类似于 Hibernate 为 ORM 提供的解决方案:一个 binding 定义定义如何将 Java 对象转换为此对象或从中转换的规则 在准备绑定并编译类之后,JiBX 绑定编译器 增强了类文件并添加了代码以处理类实例的转换 from 或 to XML。
有关 JiBX 的更多信息,请参阅 JiBX Web
站点。Spring 集成类驻留在包中。org.springframework.oxm.jibx
6.6.1. 使用JibxMarshaller
该类同时实现 and 接口。要进行操作,它需要要封送的类的名称,您可以
set 使用属性。(可选)您可以通过设置属性来设置绑定名称。在下面的示例中,我们绑定了类:JibxMarshallerMarshallerUnmarshallertargetClassbindingNameFlights
<beans>
<bean id="jibxFlightsMarshaller" class="org.springframework.oxm.jibx.JibxMarshaller">
<property name="targetClass">org.springframework.oxm.jibx.Flights</property>
</bean>
...
</beans>A 配置为单个类。如果要封送多个
类,则必须配置具有不同属性值的多个实例。JibxMarshallerJibxMarshallertargetClass
6.7. XStream
XStream 是一个简单的库,用于将对象序列化为 XML,然后再序列化回来。它没有 需要任何映射并生成干净的 XML。
有关 XStream 的更多信息,请参阅 XStream
网站。Spring 集成类驻留在包中。org.springframework.oxm.xstream
6.7.1. 使用XStreamMarshaller
不需要任何配置,可以在
application context 直接访问。要进一步自定义 XML,您可以设置别名映射
由映射到类的字符串别名组成,如下例所示:XStreamMarshaller
<beans>
<bean id="xstreamMarshaller" class="org.springframework.oxm.xstream.XStreamMarshaller">
<property name="aliases">
<props>
<prop key="Flight">org.springframework.oxm.xstream.Flight</prop>
</props>
</property>
</bean>
...
</beans>|
默认情况下,XStream 允许对任意类进行解组,这可能导致
不安全的 Java 序列化效果。因此,我们不建议使用 the 从外部源(即 Web)解组 XML,因为这样做可能会
导致安全漏洞。 如果您选择使用从外部源解组 XML,
在 上设置 属性,如下例所示: 这样做可以确保只有已注册的类才有资格进行 unmarshalling。 此外,您还可以注册自定义
converters 来确保只有您支持的类可以解组。你可以
想要添加 a 作为列表中的最后一个转换器,除了
显式支持应支持的 Domain 类的转换器。作为
结果,默认 XStream 转换器具有较低的优先级和可能的安全性
漏洞不会被调用。 |
| 请注意,XStream 是一个 XML 序列化库,而不是一个数据绑定库。 因此,它对命名空间的支持有限。因此,它相当不适合使用 在 Web 服务中。 |
7. 附录
7.1. XML 架构
附录的这一部分列出了用于数据访问的 XML 架构,包括以下内容:
7.1.1. 模式tx
这些标记处理在 Spring 的全面支持中配置所有这些 bean
进行交易。这些标签在标题为 Transaction Management 的章节中介绍。tx
我们强烈建议您查看
Spring 发行版。此文件包含 Spring 事务的 XML Schema
配置,并涵盖命名空间中的所有各种元素,包括
属性默认值和类似信息。此文件以内联方式记录,因此,
为了遵守 DRY (不要
Repeat Yourself) 原则。'spring-tx.xsd'tx |
为了完整起见,要使用 schema 中的元素,您需要具有
以下 preamble 位于 Spring XML 配置文件的顶部。的
以下代码段引用了正确的架构,以便命名空间
可供您使用:txtx
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:aop="http://www.springframework.org/schema/aop"
xmlns:tx="http://www.springframework.org/schema/tx" (1)
xsi:schemaLocation="
http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/tx https://www.springframework.org/schema/tx/spring-tx.xsd (2)
http://www.springframework.org/schema/aop https://www.springframework.org/schema/aop/spring-aop.xsd">
<!-- bean definitions here -->
</beans>| 1 | 声明命名空间的用法。tx |
| 2 | 指定位置(包含其他架构位置)。 |
通常,当您使用命名空间中的元素时,您也在使用
元素(因为 Spring 中的声明式事务支持是
使用 AOP 实现)。前面的 XML 代码片段包含所需的相关行
引用架构,以便命名空间中的元素可用
给你。txaopaopaop |
7.1.2. 模式jdbc
这些元素允许您快速配置嵌入式数据库或初始化
现有数据源。这些元素分别记录在 Embedded Database Support 和 Initializing a DataSource 中。jdbc
要使用架构中的元素,您需要在
top 的 Spring XML 配置文件。以下代码段中的文本引用
正确的架构,以便命名空间中的元素可供您使用:jdbcjdbc
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:jdbc="http://www.springframework.org/schema/jdbc" (1)
xsi:schemaLocation="
http://www.springframework.org/schema/beans https://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/jdbc https://www.springframework.org/schema/jdbc/spring-jdbc.xsd"> (2)
<!-- bean definitions here -->
</beans>| 1 | 声明命名空间的用法。jdbc |
| 2 | 指定位置(包含其他架构位置)。 |