|
此版本仍在开发中,尚未被视为稳定版本。如需最新的稳定版本,请使用 Spring Data Neo4j 7.4.0! |
常见问题
SDN 与 Neo4j-OGM 有什么关系?
Neo4j-OGM 是一个对象图映射库,主要被以前版本的 Spring Data Neo4j 用作后端,用于将节点和关系映射到域对象的繁重工作。 目前的 SDN 不需要也不支持 Neo4j-OGM。 SDN 使用 Spring Data 的映射上下文专门用于扫描类和构建元模型。
虽然这将 SDN 与 Spring 生态系统挂钩,但它有几个优势,其中包括 CPU 和内存使用占用更少,尤其是 Spring 映射上下文的所有功能。
为什么我应该使用 SDN 而不是 SDN+OGM
SDN 具有 SDN+OGM 中不存在的几个功能,特别是
-
完全支持 Springs 反应式 story,包括反应式事务
-
完全支持 Query By Example
-
完全支持完全不可变的实体
-
支持派生的 finder 方法的所有修饰符和变体,包括空间查询
SDN 是否支持嵌入式 Neo4j?
嵌入式 Neo4j 有多个方面:
SDN 是否直接与嵌入式实例交互?
不。
嵌入式数据库通常由 的实例表示,并且没有开箱即用的 Bolt 连接器。org.neo4j.graphdb.GraphDatabaseService
然而,SDN 可以与 Neo4j 的测试工具非常兼容,测试工具专门用于替代真实数据库。
对 Neo4j 3.5、4.x 和 5.x 测试框架的支持是通过驱动程序的 Spring Boot Starters实现的。
看看相应的 module 。org.neo4j.driver:neo4j-java-driver-test-harness-spring-boot-autoconfigure
可以使用哪种 Neo4j Java 驱动程序以及如何使用?
SDN 依赖于 Neo4j Java 驱动程序。 每个 SDN 版本都使用一个 Neo4j Java 驱动程序版本,该版本与发布时可用的最新 Neo4j 兼容 释放。 虽然 Neo4j Java 驱动程序的补丁版本通常是直接替换版本,但 SDN 确保即使是次要版本 是可互换的,因为它会检查是否存在方法或接口更改(如有必要)。
因此,您可以将任何 4.x Neo4j Java 驱动程序与任何 SDN 6.x 版本一起使用。 以及任何 SDN 7.x 版本的任意 5.x Neo4j 驱动程序。
使用 Spring Boot
如今,Spring Boot 部署是最有可能的基于 Spring Data 的应用程序部署。请使用 Spring Boots 依赖管理来更改驱动程序版本,如下所示:
<properties>
<neo4j-java-driver.version>5.4.0</neo4j-java-driver.version>
</properties>或
neo4j-java-driver.version = 5.4.0不使用 Spring Boot
如果没有 Spring Boot,您只需手动声明依赖项。对于 Maven,我们建议使用如下部分:<dependencyManagement />
<dependencyManagement>
<dependency>
<groupId>org.neo4j.driver</groupId>
<artifactId>neo4j-java-driver</artifactId>
<version>5.4.0</version>
</dependency>
</dependencyManagement>
Neo4j 4 支持多个数据库 - 如何使用它们?
您可以静态配置数据库名称,也可以运行自己的数据库名称提供程序。 请记住,SDN 不会为您创建数据库。 您可以借助迁移工具执行此操作,当然也可以使用简单的脚本。
静态配置
配置要在 Spring Boot 配置中使用的数据库名称,如下所示(相同的属性当然适用于 YML 或基于环境的配置,并应用了 Spring Boot 的约定):
spring.data.neo4j.database = yourDatabase有了该配置,由 SDN 存储库的所有实例(反应式和命令式)和分别生成的所有查询都将针对数据库执行。ReactiveNeo4jTemplateNeo4jTemplateyourDatabase
动态配置
提供具有类型或取决于 Spring 应用程序的类型的 Bean。Neo4jDatabaseNameProviderReactiveDatabaseSelectionProvider
例如,该 bean 可以使用 Spring 的安全上下文来检索租户。 以下是使用 Spring Security 保护的命令式应用程序的工作示例:
import org.neo4j.springframework.data.core.DatabaseSelection;
import org.neo4j.springframework.data.core.DatabaseSelectionProvider;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.security.core.Authentication;
import org.springframework.security.core.context.SecurityContext;
import org.springframework.security.core.context.SecurityContextHolder;
import org.springframework.security.core.userdetails.User;
@Configuration
public class Neo4jConfig {
@Bean
DatabaseSelectionProvider databaseSelectionProvider() {
return () -> Optional.ofNullable(SecurityContextHolder.getContext()).map(SecurityContext::getAuthentication)
.filter(Authentication::isAuthenticated).map(Authentication::getPrincipal).map(User.class::cast)
.map(User::getUsername).map(DatabaseSelection::byName).orElseGet(DatabaseSelection::undecided);
}
}| 请注意,不要将从一个数据库检索到的实体与另一个数据库混淆。 每个新事务都会请求数据库名称,因此在两次调用之间更改数据库名称时,您最终得到的实体可能会比预期的要少或多。 或者更糟糕的是,您不可避免地会将错误的实体存储在错误的数据库中。 |
Spring Boot Neo4j 健康指示器针对默认数据库,如何更改它?
Spring Boot 带有命令式和反应式 Neo4j 健康指标。两种变体都能够检测应用程序上下文中的多个 bean,并提供
对每个实例的整体运行状况的贡献。
但是,Neo4j 驱动程序确实连接到服务器,而不是该服务器中的特定数据库。
Spring Boot 能够在没有 Spring Data Neo4j 的情况下配置驱动程序,并作为要使用的数据库的信息
与 Spring Data Neo4j 相关联,则此信息不适用于内置运行状况指示器。org.neo4j.driver.Driver
在许多部署方案中,这很可能不是问题。 但是,如果配置的数据库用户至少没有对默认数据库的访问权限,则运行状况检查将失败。
这可以通过了解数据库选择的自定义 Neo4j 健康贡献者来缓解。
命令式变体
import java.util.Optional;
import org.neo4j.driver.Driver;
import org.neo4j.driver.Result;
import org.neo4j.driver.SessionConfig;
import org.neo4j.driver.summary.DatabaseInfo;
import org.neo4j.driver.summary.ResultSummary;
import org.neo4j.driver.summary.ServerInfo;
import org.springframework.boot.actuate.health.AbstractHealthIndicator;
import org.springframework.boot.actuate.health.Health;
import org.springframework.data.neo4j.core.DatabaseSelection;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.util.StringUtils;
public class DatabaseSelectionAwareNeo4jHealthIndicator extends AbstractHealthIndicator {
private final Driver driver;
private final DatabaseSelectionProvider databaseSelectionProvider;
public DatabaseSelectionAwareNeo4jHealthIndicator(
Driver driver, DatabaseSelectionProvider databaseSelectionProvider
) {
this.driver = driver;
this.databaseSelectionProvider = databaseSelectionProvider;
}
@Override
protected void doHealthCheck(Health.Builder builder) {
try {
SessionConfig sessionConfig = Optional
.ofNullable(databaseSelectionProvider.getDatabaseSelection())
.filter(databaseSelection -> databaseSelection != DatabaseSelection.undecided())
.map(DatabaseSelection::getValue)
.map(v -> SessionConfig.builder().withDatabase(v).build())
.orElseGet(SessionConfig::defaultConfig);
class Tuple {
String edition;
ResultSummary resultSummary;
Tuple(String edition, ResultSummary resultSummary) {
this.edition = edition;
this.resultSummary = resultSummary;
}
}
String query =
"CALL dbms.components() YIELD name, edition WHERE name = 'Neo4j Kernel' RETURN edition";
Tuple health = driver.session(sessionConfig)
.writeTransaction(tx -> {
Result result = tx.run(query);
String edition = result.single().get("edition").asString();
return new Tuple(edition, result.consume());
});
addHealthDetails(builder, health.edition, health.resultSummary);
} catch (Exception ex) {
builder.down().withException(ex);
}
}
static void addHealthDetails(Health.Builder builder, String edition, ResultSummary resultSummary) {
ServerInfo serverInfo = resultSummary.server();
builder.up()
.withDetail(
"server", serverInfo.version() + "@" + serverInfo.address())
.withDetail("edition", edition);
DatabaseInfo databaseInfo = resultSummary.database();
if (StringUtils.hasText(databaseInfo.name())) {
builder.withDetail("database", databaseInfo.name());
}
}
}这将使用可用的数据库选择来运行与 Boot 相同的查询,以检查连接是否正常。 使用以下配置来应用它:
import java.util.Map;
import org.neo4j.driver.Driver;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.boot.actuate.health.CompositeHealthContributor;
import org.springframework.boot.actuate.health.HealthContributor;
import org.springframework.boot.actuate.health.HealthContributorRegistry;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
@Configuration(proxyBeanMethods = false)
public class Neo4jHealthConfig {
@Bean (1)
DatabaseSelectionAwareNeo4jHealthIndicator databaseSelectionAwareNeo4jHealthIndicator(
Driver driver, DatabaseSelectionProvider databaseSelectionProvider
) {
return new DatabaseSelectionAwareNeo4jHealthIndicator(driver, databaseSelectionProvider);
}
@Bean (2)
HealthContributor neo4jHealthIndicator(
Map<String, DatabaseSelectionAwareNeo4jHealthIndicator> customNeo4jHealthIndicators) {
return CompositeHealthContributor.fromMap(customNeo4jHealthIndicators);
}
@Bean (3)
InitializingBean healthContributorRegistryCleaner(
HealthContributorRegistry healthContributorRegistry,
Map<String, DatabaseSelectionAwareNeo4jHealthIndicator> customNeo4jHealthIndicators
) {
return () -> customNeo4jHealthIndicators.keySet()
.stream()
.map(HealthContributorNameFactory.INSTANCE)
.forEach(healthContributorRegistry::unregisterContributor);
}
}| 1 | 如果您有多个驱动程序和数据库选择提供程序,则需要为每个组合创建一个指标 |
| 2 | 这确保了所有这些指标都归类在 Neo4j 下,取代了默认的 Neo4j 健康指标 |
| 3 | 这可以防止单个贡献者直接显示在运行状况终端节点中 |
反应式变体
反应式变体基本相同,使用反应式类型和相应的反应式基础设施类:
import reactor.core.publisher.Mono;
import reactor.util.function.Tuple2;
import org.neo4j.driver.Driver;
import org.neo4j.driver.SessionConfig;
import org.neo4j.driver.reactivestreams.RxResult;
import org.neo4j.driver.reactivestreams.RxSession;
import org.neo4j.driver.summary.DatabaseInfo;
import org.neo4j.driver.summary.ResultSummary;
import org.neo4j.driver.summary.ServerInfo;
import org.reactivestreams.Publisher;
import org.springframework.boot.actuate.health.AbstractReactiveHealthIndicator;
import org.springframework.boot.actuate.health.Health;
import org.springframework.data.neo4j.core.DatabaseSelection;
import org.springframework.data.neo4j.core.ReactiveDatabaseSelectionProvider;
import org.springframework.util.StringUtils;
public final class DatabaseSelectionAwareNeo4jReactiveHealthIndicator
extends AbstractReactiveHealthIndicator {
private final Driver driver;
private final ReactiveDatabaseSelectionProvider databaseSelectionProvider;
public DatabaseSelectionAwareNeo4jReactiveHealthIndicator(
Driver driver,
ReactiveDatabaseSelectionProvider databaseSelectionProvider
) {
this.driver = driver;
this.databaseSelectionProvider = databaseSelectionProvider;
}
@Override
protected Mono<Health> doHealthCheck(Health.Builder builder) {
String query =
"CALL dbms.components() YIELD name, edition WHERE name = 'Neo4j Kernel' RETURN edition";
return databaseSelectionProvider.getDatabaseSelection()
.map(databaseSelection -> databaseSelection == DatabaseSelection.undecided() ?
SessionConfig.defaultConfig() :
SessionConfig.builder().withDatabase(databaseSelection.getValue()).build()
)
.flatMap(sessionConfig ->
Mono.usingWhen(
Mono.fromSupplier(() -> driver.rxSession(sessionConfig)),
s -> {
Publisher<Tuple2<String, ResultSummary>> f = s.readTransaction(tx -> {
RxResult result = tx.run(query);
return Mono.from(result.records())
.map((record) -> record.get("edition").asString())
.zipWhen((edition) -> Mono.from(result.consume()));
});
return Mono.fromDirect(f);
},
RxSession::close
)
).map((result) -> {
addHealthDetails(builder, result.getT1(), result.getT2());
return builder.build();
});
}
static void addHealthDetails(Health.Builder builder, String edition, ResultSummary resultSummary) {
ServerInfo serverInfo = resultSummary.server();
builder.up()
.withDetail(
"server", serverInfo.version() + "@" + serverInfo.address())
.withDetail("edition", edition);
DatabaseInfo databaseInfo = resultSummary.database();
if (StringUtils.hasText(databaseInfo.name())) {
builder.withDetail("database", databaseInfo.name());
}
}
}当然,还有 configuration 的 reactive 变体。它需要两个不同的注册表清理器,因为 Spring Boot 会 包装现有的 reactive Indicators 以与 non-reactive actuator 端点一起使用。
import java.util.Map;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.boot.actuate.health.CompositeReactiveHealthContributor;
import org.springframework.boot.actuate.health.HealthContributorNameFactory;
import org.springframework.boot.actuate.health.HealthContributorRegistry;
import org.springframework.boot.actuate.health.ReactiveHealthContributor;
import org.springframework.boot.actuate.health.ReactiveHealthContributorRegistry;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration(proxyBeanMethods = false)
public class Neo4jHealthConfig {
@Bean
ReactiveHealthContributor neo4jHealthIndicator(
Map<String, DatabaseSelectionAwareNeo4jReactiveHealthIndicator> customNeo4jHealthIndicators) {
return CompositeReactiveHealthContributor.fromMap(customNeo4jHealthIndicators);
}
@Bean
InitializingBean healthContributorRegistryCleaner(HealthContributorRegistry healthContributorRegistry,
Map<String, DatabaseSelectionAwareNeo4jReactiveHealthIndicator> customNeo4jHealthIndicators) {
return () -> customNeo4jHealthIndicators.keySet()
.stream()
.map(HealthContributorNameFactory.INSTANCE)
.forEach(healthContributorRegistry::unregisterContributor);
}
@Bean
InitializingBean reactiveHealthContributorRegistryCleaner(
ReactiveHealthContributorRegistry healthContributorRegistry,
Map<String, DatabaseSelectionAwareNeo4jReactiveHealthIndicator> customNeo4jHealthIndicators) {
return () -> customNeo4jHealthIndicators.keySet()
.stream()
.map(HealthContributorNameFactory.INSTANCE)
.forEach(healthContributorRegistry::unregisterContributor);
}
}Neo4j 4.4+ 支持模拟不同的用户 - 如何使用它们?
用户模拟在大型多租户设置中特别有趣,其中物理连接(或技术连接) 用户可以模拟多个租户。根据您的设置,这将大大减少所需的物理驱动程序实例的数量。
该功能需要服务器端的 Neo4j Enterprise 4.4+ 和客户端(或更高版本)的 4.4+ 驱动程序。org.neo4j.driver:neo4j-java-driver:4.4.0
对于命令式和反应式版本,您需要分别提供 a .
同一个实例需要分别传递给 和 它们的响应式变体。UserSelectionProviderReactiveUserSelectionProviderNeo4ClientNeo4jTransactionManager
在 Bootless 命令式和反应式配置中,你只需要提供一个 bean 的 有问题的类型:
import org.springframework.data.neo4j.core.UserSelection;
import org.springframework.data.neo4j.core.UserSelectionProvider;
public class CustomConfig {
@Bean
public UserSelectionProvider getUserSelectionProvider() {
return () -> UserSelection.impersonate("someUser");
}
}在典型的 Spring Boot 场景中,此功能需要更多的工作,因为 Boot 还支持没有该功能的 SDN 版本。 因此,给定 User selection provider bean 中的 bean,您将需要完全自定义 Client 端和事务管理器:
import org.neo4j.driver.Driver;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.data.neo4j.core.Neo4jClient;
import org.springframework.data.neo4j.core.UserSelectionProvider;
import org.springframework.data.neo4j.core.transaction.Neo4jTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
public class CustomConfig {
@Bean
public Neo4jClient neo4jClient(
Driver driver,
DatabaseSelectionProvider databaseSelectionProvider,
UserSelectionProvider userSelectionProvider
) {
return Neo4jClient.with(driver)
.withDatabaseSelectionProvider(databaseSelectionProvider)
.withUserSelectionProvider(userSelectionProvider)
.build();
}
@Bean
public PlatformTransactionManager transactionManager(
Driver driver,
DatabaseSelectionProvider databaseSelectionProvider,
UserSelectionProvider userSelectionProvider
) {
return Neo4jTransactionManager
.with(driver)
.withDatabaseSelectionProvider(databaseSelectionProvider)
.withUserSelectionProvider(userSelectionProvider)
.build();
}
}使用 Spring Data Neo4j 中的 Neo4j 集群实例
以下问题适用于 Neo4j AuraDB 以及 Neo4j 本地集群实例。
我是否需要特定的配置才能使事务与 Neo4j 因果集群无缝协作?
不,你不需要。 SDN 在内部使用 Neo4j Causal Cluster 书签,无需您进行任何配置。 同一线程或同一反应式流中的事务将能够像你所期望的那样读取它们之前更改的值。
对 Neo4j 集群使用只读事务重要吗?
是的,它是。 Neo4j 集群架构是一种因果集群架构,它区分了主服务器和辅助服务器。 主服务器可以是单个实例或核心实例。它们都可以响应读取和写入操作。 写入操作从核心实例传播到集群内的只读副本,或者更普遍地传播到追随者。 这些 follower 是辅助服务器。 辅助服务器不响应写入操作。
在标准部署方案中,集群中将有一些核心实例和许多只读副本。 因此,将操作或查询标记为只读非常重要,以便以领导者 永远不会不堪重负,并且查询会尽可能多地传播到只读副本。
Spring Data Neo4j 和底层 Java 驱动程序都不进行 Cypher 解析,并且两个构建块都假定 write 操作。做出此决定是为了支持所有开箱即用的操作。如果 默认情况下,堆栈将假定为只读,则堆栈最终可能会向只读副本发送写入查询并失败 执行它们。
默认情况下,所有 、 和 预定义存在方法都标记为只读。findByIdfindAllByIdfindAll |
下面介绍了一些选项:
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.transaction.annotation.Transactional;
@Transactional(readOnly = true)
interface PersonRepository extends Neo4jRepository<Person, Long> {
}import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.data.neo4j.repository.query.Query;
import org.springframework.transaction.annotation.Transactional;
interface PersonRepository extends Neo4jRepository<Person, Long> {
@Transactional(readOnly = true)
Person findOneByName(String name); (1)
@Transactional(readOnly = true)
@Query("""
CALL apoc.search.nodeAll('{Person: "name",Movie: ["title","tagline"]}','contains','her')
YIELD node AS n RETURN n""")
Person findByCustomQuery(); (2)
}| 1 | 为什么只读不是默认的?虽然它适用于上面的派生 finder(我们实际上知道它是只读的),
我们经常看到用户添加自定义并通过 construct 实现它的情况,
这当然是一个写入操作。@QueryMERGE |
| 2 | 自定义过程可以做各种各样的事情,目前没有办法在这里为我们检查只读还是写入。 |
import java.util.Optional;
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.transaction.annotation.Transactional;
interface PersonRepository extends Neo4jRepository<Person, Long> {
}
interface MovieRepository extends Neo4jRepository<Movie, Long> {
List<Movie> findByLikedByPersonName(String name);
}
public class PersonService {
private final PersonRepository personRepository;
private final MovieRepository movieRepository;
public PersonService(PersonRepository personRepository,
MovieRepository movieRepository) {
this.personRepository = personRepository;
this.movieRepository = movieRepository;
}
@Transactional(readOnly = true)
public Optional<PersonDetails> getPerson(Long id) { (1)
return this.repository.findById(id)
.map(person -> {
var movies = this.movieRepository
.findByLikedByPersonName(person.getName());
return new PersonDetails(person, movies);
});
}
}| 1 | 在这里,对多个存储库的多次调用被包装在一个只读事务中。 |
TransactionTemplateimport java.util.Collection;
import org.neo4j.driver.types.Node;
import org.springframework.data.neo4j.core.Neo4jClient;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.TransactionDefinition;
import org.springframework.transaction.support.TransactionTemplate;
public class PersonService {
private final TransactionTemplate readOnlyTx;
private final Neo4jClient neo4jClient;
public PersonService(PlatformTransactionManager transactionManager, Neo4jClient neo4jClient) {
this.readOnlyTx = new TransactionTemplate(transactionManager, (1)
new TransactionDefinition() {
@Override public boolean isReadOnly() {
return true;
}
}
);
this.neo4jClient = neo4jClient;
}
void internalOperation() { (2)
Collection<Node> nodes = this.readOnlyTx.execute(state -> {
return neo4jClient.query("MATCH (n) RETURN n").fetchAs(Node.class) (3)
.mappedBy((types, record) -> record.get(0).asNode())
.all();
});
}
}| 1 | 创建具有所需特征的实例。
当然,这也可以是一个全球性的 bean。TransactionTemplate |
| 2 | 使用事务模板的第一个原因:声明式事务不起作用
在 package private 或 private methods中,也不在内部方法调用中(想象另一个方法
)由于它们的性质是通过 Aspects 实现的
和代理。internalOperation |
| 3 | 这是 SDN 提供的固定实用程序。它不能被注释,但它与 Spring 集成。
因此,它为您提供了使用纯驱动程序执行的所有操作,无需自动映射,并且
交易。它还服从声明性事务。Neo4jClient |
我可以检索最新的书签或为事务管理器设定种子吗?
正如 书签管理 中简要提到的,无需配置与书签有关的任何内容。
但是,检索从数据库接收的 SDN 事务系统的最新书签可能很有用。
您可以添加 like 来执行此操作:@BeanBookmarkCapture
import java.util.Set;
import org.neo4j.driver.Bookmark;
import org.springframework.context.ApplicationListener;
public final class BookmarkCapture
implements ApplicationListener<Neo4jBookmarksUpdatedEvent> {
@Override
public void onApplicationEvent(Neo4jBookmarksUpdatedEvent event) {
// We make sure that this event is called only once,
// the thread safe application of those bookmarks is up to your system.
Set<Bookmark> latestBookmarks = event.getBookmarks();
}
}要为事务系统设定种子,需要一个自定义的事务管理器,如下所示:
import java.util.Set;
import java.util.function.Supplier;
import org.neo4j.driver.Bookmark;
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.data.neo4j.core.transaction.Neo4jBookmarkManager;
import org.springframework.data.neo4j.core.transaction.Neo4jTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
public class BookmarkSeedingConfig {
@Bean
public PlatformTransactionManager transactionManager(
Driver driver, DatabaseSelectionProvider databaseNameProvider) { (1)
Supplier<Set<Bookmark>> bookmarkSupplier = () -> { (2)
Bookmark a = null;
Bookmark b = null;
return Set.of(a, b);
};
Neo4jBookmarkManager bookmarkManager =
Neo4jBookmarkManager.create(bookmarkSupplier); (3)
return new Neo4jTransactionManager(
driver, databaseNameProvider, bookmarkManager); (4)
}
}| 1 | 让 Spring 注入这些 |
| 2 | 此供应商可以是包含您要引入系统的最新书签的任何内容 |
| 3 | 使用它创建书签管理器 |
| 4 | 将其传递给自定义事务管理器 |
| 无需执行上述任何操作,除非您的应用程序需要访问或提供 这个数据。如有疑问,也不要这样做。 |
我可以禁用书签管理吗?
我们提供了一个 Noop 书签管理器,可以有效地禁用书签管理。
| 使用此书签管理器的风险由您自己承担,它将通过全部删除来有效地禁用任何书签管理 书签,并且从不提供任何。在集群中,您将面临过时读取的高风险。在单个 实例,它很可能不会产生任何影响。 |
+ 在集群中,这可能是一种明智的方法,前提是您可以容忍过时的读取并且不会面临 覆盖旧数据。
以下配置创建书签管理器的 “noop” 变体,该变体将从相关类中获取。
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.core.transaction.Neo4jBookmarkManager;
@Configuration
public class BookmarksDisabledConfig {
@Bean
public Neo4jBookmarkManager neo4jBookmarkManager() {
return Neo4jBookmarkManager.noop();
}
}您可以单独配置 和 对,但我们建议您仅在已针对特定数据库选择需求配置它们时才这样做。Neo4jTransactionManager/Neo4jClientReactiveNeo4jTransactionManager/ReactiveNeo4jClient
我需要使用 Neo4j 特定的注释吗?
不。 您可以自由使用以下等效的 Spring Data 注释:
| SDN 特定注释 | Spring Data 通用注释 | 目的 | 差异 |
|---|---|---|---|
|
|
将带注释的属性标记为唯一 ID。 |
特定注释没有其他功能。 |
|
|
将类标记为持久实体。 |
|
如何使用分配的 ID?
只需使用 without 并通过构造函数参数或 setter 或 wither 填充你的 id 属性。
有关查找良好 ID 的一些一般性说明,请参阅此博客文章。@Id@GeneratedValue
如何使用外部生成的 ID?
我们提供接口 .
以您想要的任何方式实现它,并像这样配置您的实现:org.springframework.data.neo4j.core.schema.IdGenerator
@Node
public class ThingWithGeneratedId {
@Id @GeneratedValue(TestSequenceGenerator.class)
private String theId;
}如果将类的名称传递给 ,则此类必须具有 no-args 默认构造函数。
但是,您也可以使用 string:@GeneratedValue
@Node
public class ThingWithIdGeneratedByBean {
@Id @GeneratedValue(generatorRef = "idGeneratingBean")
private String theId;
}这样,指的是 Spring 上下文中的 bean。
这可能对序列生成有用。idGeneratingBean
| id 的非 final 字段不需要 setter。 |
我是否必须为每个域类创建存储库?
不。
查看 SDN 构建基块并找到 或 。Neo4jTemplateReactiveNeo4jTemplate
这些模板了解您的域,并提供用于检索、写入和计数实体的所有必要基本 CRUD 方法。
这是我们使用命令式模板的规范电影示例:
import static org.assertj.core.api.Assertions.assertThat;
import java.util.Collections;
import java.util.Optional;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.neo4j.core.Neo4jTemplate;
import org.springframework.data.neo4j.documentation.domain.MovieEntity;
import org.springframework.data.neo4j.documentation.domain.PersonEntity;
import org.springframework.data.neo4j.documentation.domain.Roles;
@DataNeo4jTest
public class TemplateExampleTest {
@Test
void shouldSaveAndReadEntities(@Autowired Neo4jTemplate neo4jTemplate) {
MovieEntity movie = new MovieEntity("The Love Bug",
"A movie that follows the adventures of Herbie, Herbie's driver, "
+ "Jim Douglas (Dean Jones), and Jim's love interest, " + "Carole Bennett (Michele Lee)");
Roles roles1 = new Roles(new PersonEntity(1931, "Dean Jones"), Collections.singletonList("Didi"));
Roles roles2 = new Roles(new PersonEntity(1942, "Michele Lee"), Collections.singletonList("Michi"));
movie.getActorsAndRoles().add(roles1);
movie.getActorsAndRoles().add(roles2);
MovieEntity result = neo4jTemplate.save(movie);
assertThat(result.getActorsAndRoles()).allSatisfy(relationship -> assertThat(relationship.getId()).isNotNull());
Optional<PersonEntity> person = neo4jTemplate.findById("Dean Jones", PersonEntity.class);
assertThat(person).map(PersonEntity::getBorn).hasValue(1931);
assertThat(neo4jTemplate.count(PersonEntity.class)).isEqualTo(2L);
}
}这是响应式版本,为简洁起见,省略了设置:
import reactor.test.StepVerifier;
import java.util.Collections;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.neo4j.core.ReactiveNeo4jTemplate;
import org.springframework.data.neo4j.documentation.domain.MovieEntity;
import org.springframework.data.neo4j.documentation.domain.PersonEntity;
import org.springframework.data.neo4j.documentation.domain.Roles;
import org.springframework.test.context.DynamicPropertyRegistry;
import org.springframework.test.context.DynamicPropertySource;
import org.testcontainers.containers.Neo4jContainer;
import org.testcontainers.junit.jupiter.Container;
import org.testcontainers.junit.jupiter.Testcontainers;
@Testcontainers
@DataNeo4jTest
class ReactiveTemplateExampleTest {
@Container private static Neo4jContainer<?> neo4jContainer = new Neo4jContainer<>("neo4j:5");
@DynamicPropertySource
static void neo4jProperties(DynamicPropertyRegistry registry) {
registry.add("org.neo4j.driver.uri", neo4jContainer::getBoltUrl);
registry.add("org.neo4j.driver.authentication.username", () -> "neo4j");
registry.add("org.neo4j.driver.authentication.password", neo4jContainer::getAdminPassword);
}
@Test
void shouldSaveAndReadEntities(@Autowired ReactiveNeo4jTemplate neo4jTemplate) {
MovieEntity movie = new MovieEntity("The Love Bug",
"A movie that follows the adventures of Herbie, Herbie's driver, Jim Douglas (Dean Jones), and Jim's love interest, Carole Bennett (Michele Lee)");
Roles role1 = new Roles(new PersonEntity(1931, "Dean Jones"), Collections.singletonList("Didi"));
Roles role2 = new Roles(new PersonEntity(1942, "Michele Lee"), Collections.singletonList("Michi"));
movie.getActorsAndRoles().add(role1);
movie.getActorsAndRoles().add(role2);
StepVerifier.create(neo4jTemplate.save(movie)).expectNextCount(1L).verifyComplete();
StepVerifier.create(neo4jTemplate.findById("Dean Jones", PersonEntity.class).map(PersonEntity::getBorn))
.expectNext(1931).verifyComplete();
StepVerifier.create(neo4jTemplate.count(PersonEntity.class)).expectNext(2L).verifyComplete();
}
}请注意,这两个示例都使用 Spring Boot。@DataNeo4jTest
如何在存储库方法返回 or 的情况下使用自定义查询?Page<T>Slice<T>
虽然您不必在派生的 finder 方法上提供除 a 作为参数之外的任何其他内容
返回 a 或 a ,则必须准备自定义查询来处理 pageable。Pages and Slices 为您提供有关所需内容的概述。PageablePage<T>Slice<T>
import org.springframework.data.domain.Pageable;
import org.springframework.data.neo4j.repository.Neo4jRepository;
import org.springframework.data.neo4j.repository.query.Query;
public interface MyPersonRepository extends Neo4jRepository<Person, Long> {
Page<Person> findByName(String name, Pageable pageable); (1)
@Query(""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n "
+ "ORDER BY n.name ASC SKIP $skip LIMIT $limit"
)
Slice<Person> findSliceByName(String name, Pageable pageable); (2)
@Query(
value = ""
+ "MATCH (n:Person) WHERE n.name = $name RETURN n "
+ "ORDER BY n.name ASC SKIP $skip LIMIT $limit",
countQuery = ""
+ "MATCH (n:Person) WHERE n.name = $name RETURN count(n)"
)
Page<Person> findPageByName(String name, Pageable pageable); (3)
}| 1 | 为您创建查询的派生 finder 方法。
它为您处理。
您应该使用已排序的 pageable。Pageable |
| 2 | 此方法用于定义自定义查询。它返回一个 .
切片不知道总页数,因此自定义查询
不需要专用的 count 查询。SDN 将通知您它会估计下一个切片。
Cypher 模板必须同时发现 Cypher 参数。
如果省略它们,SDN 将发出警告。这可能不符合您的期望。
此外,它们应该是 unsorted 的,您应该提供一个稳定的 order。
我们不会使用 pageable 中的排序信息。@QuerySlice<Person>$skip$limitPageable |
| 3 | 此方法返回一个页面。页面知道总页数的确切数量。 因此,您必须指定其他 count 查询。 第二种方法的所有其他限制均适用。 |
我可以映射命名路径吗?
一系列连接的节点和关系在 Neo4j 中称为 “路径”。 Cypher 允许使用标识符命名路径,例如:
p = (a)-[*3..5]->(b)或者如臭名昭著的 Movie 图形中所示,它包括以下路径(在这种情况下,两个角色之间的最短路径之一):
MATCH p=shortestPath((bacon:Person {name:"Kevin Bacon"})-[*]-(meg:Person {name:"Meg Ryan"}))
RETURN p如下所示:
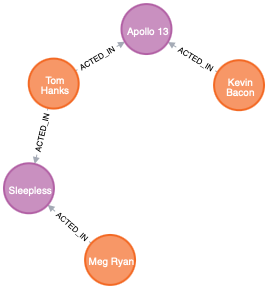
我们发现 3 个节点被标记,2 个节点被标记为 。两者都可以使用自定义查询进行映射。
假设有一个 node 实体用于 和 以及处理关系:VertexMovieVertexMovieActor
@Node
public final class Person {
@Id @GeneratedValue
private final Long id;
private final String name;
private Integer born;
@Relationship("REVIEWED")
private List<Movie> reviewed = new ArrayList<>();
}
@RelationshipProperties
public final class Actor {
@RelationshipId
private final Long id;
@TargetNode
private final Person person;
private final List<String> roles;
}
@Node
public final class Movie {
@Id
private final String title;
@Property("tagline")
private final String description;
@Relationship(value = "ACTED_IN", direction = Direction.INCOMING)
private final List<Actor> actors;
}当对类型的域类使用查询时,如 “Bacon” 距离所示Vertex
interface PeopleRepository extends Neo4jRepository<Person, Long> {
@Query(""
+ "MATCH p=shortestPath((bacon:Person {name: $person1})-[*]-(meg:Person {name: $person2}))\n"
+ "RETURN p"
)
List<Person> findAllOnShortestPathBetween(@Param("person1") String person1, @Param("person2") String person2);
}它将从路径中检索所有人员并映射他们。
如果路径上存在类似的关系类型,则域上也存在这些
将从 path 中相应地填充。REVIEWED
| 使用从基于路径的查询中冻结的节点来保存数据时,请特别小心。 如果不是所有关系都已冻结,则数据将丢失。 |
反之亦然。同一查询可用于实体。
然后,它只会填充电影。
以下清单显示了如何执行此操作,以及如何使用其他数据来丰富查询
在路径上未找到。该数据用于正确填充缺失的关系(在这种情况下,所有参与者)Movie
interface MovieRepository extends Neo4jRepository<Movie, String> {
@Query(""
+ "MATCH p=shortestPath(\n"
+ "(bacon:Person {name: $person1})-[*]-(meg:Person {name: $person2}))\n"
+ "WITH p, [n IN nodes(p) WHERE n:Movie] AS x\n"
+ "UNWIND x AS m\n"
+ "MATCH (m) <-[r:DIRECTED]-(d:Person)\n"
+ "RETURN p, collect(r), collect(d)"
)
List<Movie> findAllOnShortestPathBetween(@Param("person1") String person1, @Param("person2") String person2);
}该查询返回路径以及收集的所有关系和相关节点,以便电影实体完全冻结。
路径映射适用于单个路径以及多个路径记录(由函数返回)。allShortestPath
| 命名路径可以有效地用于填充和返回多个根节点,请参阅 appendix/custom-queries.adoc#custom-query.paths。 |
使用自定义查询是唯一的方法吗?@Query
否,这不是运行自定义查询的唯一方法。
在自定义查询完全填充您的域的情况下,该注释很舒适。
请记住,SDN 假定您的映射域模型是真实的。
这意味着,如果您使用的自定义查询仅部分填充模型,则有可能使用相同的查询
object 写回数据,这最终会擦除或覆盖您在查询中未考虑的数据。@Query@Query
因此,请在结果形状类似于您的域的所有情况下使用 repositories 和 declarative methods
model 的 model 或你确定你没有将部分映射的 model 用于 write 命令。@Query
有哪些选择?
-
投影可能已经足以在图表上塑造您的视图:它们可用于定义 以显式方式获取属性和相关实体的深度:通过对它们进行建模。
-
如果你的目标是只使查询的条件动态化,那么请看一下
QuerydslPredicateExecutor,尤其是我们自己的变体 .两个 mixin 都允许向 我们为您创建的完整查询。因此,您将完全填充域以及自定义条件。 当然,您的条件必须与我们生成的条件相适应。在此处查找根节点的名称、相关节点等。CypherdslConditionExecutor -
通过 或 使用 Cypher-DSL。 Cypher-DSL 注定要创建动态查询。最后,无论如何,这就是 SDN 在后台使用的东西。相应的 mixins 既可以与存储库本身的域类型一起使用,也可以与投影一起使用(用于添加 conditions 则不会)。
CypherdslStatementExecutorReactiveCypherdslStatementExecutor
如果您认为可以使用部分动态查询或完全动态查询以及投影来解决问题,那么 现在请跳回关于 Spring Data Neo4j Mixin 的章节。
为什么现在谈论自定义存储库片段?
-
您可能遇到更复杂的情况,即需要多个动态查询,但查询仍然属于 从概念上讲,在存储库中,而不是在服务层中
-
您的自定义查询会返回一个图形形状的结果,该结果不太适合您的域模型 因此,自定义查询也应附带自定义映射
-
您需要与驱动程序进行交互,即用于不应通过对象映射的批量加载。
假设以下存储库声明基本上聚合了一个基本存储库加 3 个片段:
import org.springframework.data.neo4j.repository.Neo4jRepository;
public interface MovieRepository extends Neo4jRepository<MovieEntity, String>,
DomainResults,
NonDomainResults,
LowlevelInteractions {
}存储库从中扩展的附加接口 (和 )
是解决上述所有问题的 fragments。DomainResultsNonDomainResultsLowlevelInteractions
使用复杂的动态自定义查询,但仍返回域类型
该 fragment 声明了一个附加方法 :DomainResultsfindMoviesAlongShortestPath
interface DomainResults {
@Transactional(readOnly = true)
List<MovieEntity> findMoviesAlongShortestPath(PersonEntity from, PersonEntity to);
}此方法带有注释,以指示读者可以回答它。
它不能由 SDN 派生,但需要自定义查询。
此自定义查询由该接口的一个实现提供。
该实现具有相同的名称,但后缀为 :@Transactional(readOnly = true)Impl
import static org.neo4j.cypherdsl.core.Cypher.anyNode;
import static org.neo4j.cypherdsl.core.Cypher.listWith;
import static org.neo4j.cypherdsl.core.Cypher.name;
import static org.neo4j.cypherdsl.core.Cypher.node;
import static org.neo4j.cypherdsl.core.Cypher.parameter;
import static org.neo4j.cypherdsl.core.Cypher.shortestPath;
import org.neo4j.cypherdsl.core.Cypher;
class DomainResultsImpl implements DomainResults {
private final Neo4jTemplate neo4jTemplate; (1)
DomainResultsImpl(Neo4jTemplate neo4jTemplate) {
this.neo4jTemplate = neo4jTemplate;
}
@Override
public List<MovieEntity> findMoviesAlongShortestPath(PersonEntity from, PersonEntity to) {
var p1 = node("Person").withProperties("name", parameter("person1"));
var p2 = node("Person").withProperties("name", parameter("person2"));
var shortestPath = shortestPath("p").definedBy(
p1.relationshipBetween(p2).unbounded()
);
var p = shortestPath.getRequiredSymbolicName();
var statement = Cypher.match(shortestPath)
.with(p, listWith(name("n"))
.in(Cypher.nodes(shortestPath))
.where(anyNode().named("n").hasLabels("Movie")).returning().as("mn")
)
.unwind(name("mn")).as("m")
.with(p, name("m"))
.match(node("Person").named("d")
.relationshipTo(anyNode("m"), "DIRECTED").named("r")
)
.returning(p, Cypher.collect(name("r")), Cypher.collect(name("d")))
.build();
Map<String, Object> parameters = new HashMap<>();
parameters.put("person1", from.getName());
parameters.put("person2", to.getName());
return neo4jTemplate.findAll(statement, parameters, MovieEntity.class); (2)
}
}| 1 | 它由运行时通过 的构造函数注入。不需要 .Neo4jTemplateDomainResultsImpl@Autowired |
| 2 | Cypher-DSL 用于构建复杂的语句(与 path mapping 中显示的几乎相同。 该语句可以直接传递给模板。 |
该模板还具有基于 String 的查询的重载,因此您也可以将查询写为 String。 这里的重要收获是:
-
该模板 “了解” 您的域对象并相应地映射它们
-
@Query不是定义自定义查询的唯一选项 -
它们可以通过多种方式生成
-
遵循注释
@Transactional
使用自定义查询和自定义映射
通常,自定义查询会指示自定义结果。
所有这些结果都应该映射为 ?当然不是!很多时候,这些对象表示读取命令
,并且不用作写入命令。
SDN 不能或不想使用 Cypher 映射所有可能的东西,这并非不可能。
但是,它确实提供了几个钩子来运行您自己的映射:在 .
使用 SDN 优于驱动程序的优势:@NodeNeo4jClientNeo4jClient
-
与 Springs 事务管理集成
Neo4jClient -
它有一个用于绑定参数的 Fluent API
-
它有一个流畅的 API,公开了记录和 Neo4j 类型的系统,以便您可以访问 执行映射
声明 fragment 与之前完全相同:
interface NonDomainResults {
class Result { (1)
public final String name;
public final String typeOfRelation;
Result(String name, String typeOfRelation) {
this.name = name;
this.typeOfRelation = typeOfRelation;
}
}
@Transactional(readOnly = true)
Collection<Result> findRelationsToMovie(MovieEntity movie); (2)
}| 1 | 这是一个虚构的非域结果。实际的查询结果可能看起来更复杂。 |
| 2 | 此 fragment 添加的方法。同样,该方法使用 Spring 的@Transactional |
如果没有该 fragment 的实现,启动将失败,因此如下所示:
class NonDomainResultsImpl implements NonDomainResults {
private final Neo4jClient neo4jClient; (1)
NonDomainResultsImpl(Neo4jClient neo4jClient) {
this.neo4jClient = neo4jClient;
}
@Override
public Collection<Result> findRelationsToMovie(MovieEntity movie) {
return this.neo4jClient
.query(""
+ "MATCH (people:Person)-[relatedTo]-(:Movie {title: $title}) "
+ "RETURN people.name AS name, "
+ " Type(relatedTo) as typeOfRelation"
) (2)
.bind(movie.getTitle()).to("title") (3)
.fetchAs(Result.class) (4)
.mappedBy((typeSystem, record) -> new Result(record.get("name").asString(),
record.get("typeOfRelation").asString())) (5)
.all(); (6)
}
}| 1 | 在这里,我们使用基础设施提供的 。Neo4jClient |
| 2 | 客户端只接受 Strings,但在渲染为 String 时仍然可以使用 Cypher-DSL |
| 3 | 将一个值绑定到命名参数。还有一个重载来绑定整个参数映射 |
| 4 | 这是您想要的结果类型 |
| 5 | 最后是方法,为结果中的每个条目公开一个,如果需要,还可以公开 drivers 类型系统。
这是您挂接自定义映射的 APImappedByRecord |
整个查询在 Spring 事务的上下文中运行,在本例中为只读事务。
低级交互
有时,您可能希望从存储库进行批量加载或删除整个子图或以非常特定的方式进行交互 使用 Neo4j Java 驱动程序。这也是可能的。以下示例显示了如何操作:
interface LowlevelInteractions {
int deleteGraph();
}
class LowlevelInteractionsImpl implements LowlevelInteractions {
private final Driver driver; (1)
LowlevelInteractionsImpl(Driver driver) {
this.driver = driver;
}
@Override
public int deleteGraph() {
try (Session session = driver.session()) {
SummaryCounters counters = session
.executeWrite(tx -> tx.run("MATCH (n) DETACH DELETE n").consume()) (2)
.counters();
return counters.nodesDeleted() + counters.relationshipsDeleted();
}
}
}| 1 | 直接与驱动程序合作。与所有示例一样:不需要魔法。所有片段
实际上是可以单独测试的。@Autowired |
| 2 | 用例是虚构的。这里我们使用一个驱动程序管理的事务,删除整个图形并返回 已删除的节点和关系 |
这种交互当然不会在 Spring 事务中运行,因为驱动程序不知道 Spring。
综上所述,此测试成功:
@Test
void customRepositoryFragmentsShouldWork(
@Autowired PersonRepository people,
@Autowired MovieRepository movies
) {
PersonEntity meg = people.findById("Meg Ryan").get();
PersonEntity kevin = people.findById("Kevin Bacon").get();
List<MovieEntity> moviesBetweenMegAndKevin = movies.
findMoviesAlongShortestPath(meg, kevin);
assertThat(moviesBetweenMegAndKevin).isNotEmpty();
Collection<NonDomainResults.Result> relatedPeople = movies
.findRelationsToMovie(moviesBetweenMegAndKevin.get(0));
assertThat(relatedPeople).isNotEmpty();
assertThat(movies.deleteGraph()).isGreaterThan(0);
assertThat(movies.findAll()).isEmpty();
assertThat(people.findAll()).isEmpty();
}最后:Spring Data Neo4j 会自动选择所有三个接口和实现。 无需进一步配置。 此外,可以仅使用一个附加片段(定义所有三种方法的接口)创建相同的整个存储库 以及一个 implementation。该实现将注入所有三个抽象(template、client 和 driver)。
当然,所有这些都适用于反应式存储库。
他们将使用 and 以及驱动程序提供的 reactive 会话。ReactiveNeo4jTemplateReactiveNeo4jClient
如果您为所有存储库都有重复方法,则可以换出默认存储库实现。
如何使用自定义的 Spring Data Neo4j 基础存储库?
与共享的 Spring Data Commons 文档在自定义基本存储库中为 Spring Data JPA 显示的方式基本相同。 只是在我们的例子中,您将从
public class MyRepositoryImpl<T, ID> extends SimpleNeo4jRepository<T, ID> {
MyRepositoryImpl(
Neo4jOperations neo4jOperations,
Neo4jEntityInformation<T, ID> entityInformation
) {
super(neo4jOperations, entityInformation); (1)
}
@Override
public List<T> findAll() {
throw new UnsupportedOperationException("This implementation does not support `findAll`");
}
}| 1 | 基类需要此签名。取 (实际规格的 )
和实体信息,并在需要时将它们存储在属性上。Neo4jOperationsNeo4jTemplate |
在此示例中,我们禁止使用该方法。
您可以添加采用获取深度的方法,并根据该深度运行自定义查询。
DomainResults 片段中显示了一种执行此操作的方法。findAll
要为所有声明的存储库启用此基本存储库,请使用以下命令启用 Neo4j 存储库:。@EnableNeo4jRepositories(repositoryBaseClass = MyRepositoryImpl.class)
如何审计实体?
支持所有 Spring Data 注释。 这些是
-
org.springframework.data.annotation.CreatedBy -
org.springframework.data.annotation.CreatedDate -
org.springframework.data.annotation.LastModifiedBy -
org.springframework.data.annotation.LastModifiedDate
审计为您提供了如何在 Spring Data Commons 的更大上下文中使用审计的一般视图。 下面的清单显示了 Spring Data Neo4j 提供的每个配置选项:
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.data.auditing.DateTimeProvider;
import org.springframework.data.domain.AuditorAware;
@Configuration
@EnableNeo4jAuditing(
modifyOnCreate = false, (1)
auditorAwareRef = "auditorProvider", (2)
dateTimeProviderRef = "fixedDateTimeProvider" (3)
)
class AuditingConfig {
@Bean
public AuditorAware<String> auditorProvider() {
return () -> Optional.of("A user");
}
@Bean
public DateTimeProvider fixedDateTimeProvider() {
return () -> Optional.of(AuditingITBase.DEFAULT_CREATION_AND_MODIFICATION_DATE);
}
}| 1 | 如果希望在创建期间也写入修改数据,请设置为 true |
| 2 | 使用此属性可以指定提供审计员的 bean 的名称(即用户名) |
| 3 | 使用此属性可以指定提供当前日期的 Bean 的名称。在这种情况下 使用固定日期,因为上述配置是我们测试的一部分 |
反应式版本基本上是相同的,除了审计员感知 bean 的类型为 ,
因此,检索 auditor 是反应式流程的一部分。ReactiveAuditorAware
除了这些审计机制之外,您还可以添加任意数量的 bean implementation 或 到上下文中。这些 bean 将被 Spring Data Neo4j 拾取并按顺序调用(如果它们实现或
在 ) 中进行批注。BeforeBindCallback<T>ReactiveBeforeBindCallback<T>Ordered@Order
他们可以修改实体或返回全新的实体。 以下示例将一个回调添加到上下文中,该回调在持久保存实体之前更改一个属性:
import java.util.UUID;
import java.util.stream.StreamSupport;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.core.mapping.callback.AfterConvertCallback;
import org.springframework.data.neo4j.core.mapping.callback.BeforeBindCallback;
@Configuration
class CallbacksConfig {
@Bean
BeforeBindCallback<ThingWithAssignedId> nameChanger() {
return entity -> {
ThingWithAssignedId updatedThing = new ThingWithAssignedId(
entity.getTheId(), entity.getName() + " (Edited)");
return updatedThing;
};
}
@Bean
AfterConvertCallback<ThingWithAssignedId> randomValueAssigner() {
return (entity, definition, source) -> {
entity.setRandomValue(UUID.randomUUID().toString());
return entity;
};
}
}无需额外配置。
如何使用“按示例查找”?
“按示例查找”是 SDN 中的一项新功能。
您可以实例化实体或使用现有实体。
使用此实例,您可以创建一个 .
如果您的存储库扩展了 或 ,您可以立即使用示例中的可用方法,如 findByExample 中所示。org.springframework.data.domain.Exampleorg.springframework.data.neo4j.repository.Neo4jRepositoryorg.springframework.data.neo4j.repository.ReactiveNeo4jRepositoryfindBy
Example<MovieEntity> movieExample = Example.of(new MovieEntity("The Matrix", null));
Flux<MovieEntity> movies = this.movieRepository.findAll(movieExample);
movieExample = Example.of(
new MovieEntity("Matrix", null),
ExampleMatcher
.matchingAny()
.withMatcher(
"title",
ExampleMatcher.GenericPropertyMatcher.of(ExampleMatcher.StringMatcher.CONTAINING)
)
);
movies = this.movieRepository.findAll(movieExample);您还可以否定单个属性。这将添加一个适当的操作,从而将 an 转换为 .
支持所有标量数据类型和所有字符串运算符:NOT=<>
Example<MovieEntity> movieExample = Example.of(
new MovieEntity("Matrix", null),
ExampleMatcher
.matchingAny()
.withMatcher(
"title",
ExampleMatcher.GenericPropertyMatcher.of(ExampleMatcher.StringMatcher.CONTAINING)
)
.withTransformer("title", Neo4jPropertyValueTransformers.notMatching())
);
Flux<MovieEntity> allMoviesThatNotContainMatrix = this.movieRepository.findAll(movieExample);我需要 Spring Boot 才能使用 Spring Data Neo4j 吗?
不,你不需要。 虽然通过 Spring Boot 自动配置许多 Spring 方面消除了许多手动工作,并且是设置新 Spring 项目的推荐方法,但你不需要使用它。
上述解决方案需要以下依赖项:
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-neo4j</artifactId>
<version>7.3.7-SNAPSHOT</version>
</dependency>Gradle 设置的坐标相同。
要选择不同的数据库 - 静态或动态 - 你可以添加 Neo4j 4 支持多个数据库 - 如何使用它们?中所述的 Bean 类型。
对于反应式场景,我们提供 .DatabaseSelectionProviderReactiveDatabaseSelectionProvider
在没有 Spring Boot 的 Spring 上下文中使用 Spring Data Neo4j
我们提供了两个抽象配置类来支持您引入必要的 bean:用于命令式数据库访问和反应式版本。
它们分别与 和 一起使用。
有关示例用法,请参阅启用 Spring Data Neo4j 基础结构以进行命令式数据库访问和启用 Spring Data Neo4j 基础结构以进行反应式数据库访问。
这两个类都要求您覆盖应在其中创建驱动程序的位置。org.springframework.data.neo4j.config.AbstractNeo4jConfigorg.springframework.data.neo4j.config.AbstractReactiveNeo4jConfig@EnableNeo4jRepositories@EnableReactiveNeo4jRepositoriesdriver()
要获取 Neo4j 客户端的命令式版本、模板和对命令式存储库的支持,请使用类似于以下内容的内容,如下所示:
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.transaction.annotation.EnableTransactionManagement;
import org.springframework.data.neo4j.config.AbstractNeo4jConfig;
import org.springframework.data.neo4j.core.DatabaseSelectionProvider;
import org.springframework.data.neo4j.repository.config.EnableNeo4jRepositories;
@Configuration
@EnableNeo4jRepositories
@EnableTransactionManagement
class MyConfiguration extends AbstractNeo4jConfig {
@Override @Bean
public Driver driver() { (1)
return GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "secret"));
}
@Override
protected Collection<String> getMappingBasePackages() {
return Collections.singletonList(Person.class.getPackage().getName());
}
@Override @Bean (2)
protected DatabaseSelectionProvider databaseSelectionProvider() {
return DatabaseSelectionProvider.createStaticDatabaseSelectionProvider("yourDatabase");
}
}| 1 | 驱动程序 Bean 是必需的。 |
| 2 | 这将静态选择名为 and 的数据库,该数据库是可选的。yourDatabase |
下面的清单提供了反应式 Neo4j 客户端和模板,启用反应式事务管理并发现与 Neo4j 相关的存储库:
import org.neo4j.driver.Driver;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.neo4j.config.AbstractReactiveNeo4jConfig;
import org.springframework.data.neo4j.repository.config.EnableReactiveNeo4jRepositories;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@Configuration
@EnableReactiveNeo4jRepositories
@EnableTransactionManagement
class MyConfiguration extends AbstractReactiveNeo4jConfig {
@Bean
@Override
public Driver driver() {
return GraphDatabase.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "secret"));
}
@Override
protected Collection<String> getMappingBasePackages() {
return Collections.singletonList(Person.class.getPackage().getName());
}
}在 CDI 2.0 环境中使用 Spring Data Neo4j
为方便起见,我们提供了带有 .
当在兼容的 CDI 2.0 容器中运行时,它将通过 Java 的服务加载程序 SPI 自动注册和加载。Neo4jCdiExtension
您唯一需要引入应用程序的是生成 Neo4j Java 驱动程序的带注释的类型:
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
import org.neo4j.driver.AuthTokens;
import org.neo4j.driver.Driver;
import org.neo4j.driver.GraphDatabase;
public class Neo4jConfig {
@Produces @ApplicationScoped
public Driver driver() { (1)
return GraphDatabase
.driver("bolt://localhost:7687", AuthTokens.basic("neo4j", "secret"));
}
public void close(@Disposes Driver driver) {
driver.close();
}
@Produces @Singleton
public DatabaseSelectionProvider getDatabaseSelectionProvider() { (2)
return DatabaseSelectionProvider.createStaticDatabaseSelectionProvider("yourDatabase");
}
}| 1 | 与启用 Spring Data Neo4j 基础结构以进行命令式数据库访问中的普通 Spring 相同,但使用相应的 CDI 基础结构进行注释。 |
| 2 | 这是可选的。但是,如果运行自定义数据库选择提供程序,则不能限定此 Bean。 |
如果您在 SE 容器中运行 - 例如 Weld 提供的容器,您可以像这样启用扩展:
import javax.enterprise.inject.se.SeContainer;
import javax.enterprise.inject.se.SeContainerInitializer;
import org.springframework.data.neo4j.config.Neo4jCdiExtension;
public class SomeClass {
void someMethod() {
try (SeContainer container = SeContainerInitializer.newInstance()
.disableDiscovery()
.addExtensions(Neo4jCdiExtension.class)
.addBeanClasses(YourDriverFactory.class)
.addPackages(Package.getPackage("your.domain.package"))
.initialize()
) {
SomeRepository someRepository = container.select(SomeRepository.class).get();
}
}
}