Tasks
This section goes into more detail about how you can orchestrate Spring Cloud Task applications on Spring Cloud Data Flow.
If you are just starting out with Spring Cloud Data Flow, you should probably read the Getting Started guide for “Local” , “Cloud Foundry”, or “Kubernetes” before diving into this section.
25. Introduction
A task application is short-lived, meaning that it stops running on purpose and can be run on demand or scheduled for later. One use case might be to scrape a web page and write to the database.
The Spring Cloud Task framework is based on Spring Boot and adds the ability for Boot applications to record the lifecycle events of a short-lived application, such as when it starts, when it ends, and the exit status.
The TaskExecution documentation shows which information is stored in the database.
The entry point for code execution in a Spring Cloud Task application is most often an implementation of Boot’s CommandLineRunner interface, as shown in this example.
The Spring Batch project is probably what comes to mind for Spring developers writing short-lived applications.
Spring Batch provides a much richer set of functionality than Spring Cloud Task and is recommended when processing large volumes of data.
One use case might be to read many CSV files, transform each row of data, and write each transformed row to a database.
Spring Batch provides its own database schema with a much more rich set of information about the execution of a Spring Batch job.
Spring Cloud Task is integrated with Spring Batch so that, if a Spring Cloud Task application defines a Spring Batch Job, a link between the Spring Cloud Task and Spring Cloud Batch execution tables is created.
When running Data Flow on your local machine, Tasks are launched in a separate JVM.
When running on Cloud Foundry, tasks are launched by using Cloud Foundry’s Task functionality. When running on Kubernetes, tasks are launched by using either a Pod or a Job resource.
26. The Lifecycle of a Task
Before you dive deeper into the details of creating Tasks, you should understand the typical lifecycle for tasks in the context of Spring Cloud Data Flow:
26.1. Creating a Task Application
While Spring Cloud Task does provide a number of out-of-the-box applications (at spring-cloud-task-app-starters), most task applications require custom development. To create a custom task application:
-
Use the Spring Initializer to create a new project, making sure to select the following starters:
-
Cloud Task: This dependency is thespring-cloud-starter-task. -
JDBC: This dependency is thespring-jdbcstarter. -
Select your database dependency: Enter the database dependency that Data Flow is currently using. For example:
H2.
-
-
Within your new project, create a new class to serve as your main class, as follows:
@EnableTask @SpringBootApplication public class MyTask { public static void main(String[] args) { SpringApplication.run(MyTask.class, args); } } -
With this class, you need one or more
CommandLineRunnerorApplicationRunnerimplementations within your application. You can either implement your own or use the ones provided by Spring Boot (there is one for running batch jobs, for example). -
Packaging your application with Spring Boot into an über jar is done through the standard Spring Boot conventions. The packaged application can be registered and deployed as noted below.
26.1.1. Task Database Configuration
| When launching a task application, be sure that the database driver that is being used by Spring Cloud Data Flow is also a dependency on the task application. For example, if your Spring Cloud Data Flow is set to use Postgresql, be sure that the task application also has Postgresql as a dependency. |
| When you run tasks externally (that is, from the command line) and you want Spring Cloud Data Flow to show the TaskExecutions in its UI, be sure that common datasource settings are shared among them both. By default, Spring Cloud Task uses a local H2 instance, and the execution is recorded to the database used by Spring Cloud Data Flow. |
26.2. Registering a Task Application
You can register a Task application with the App Registry by using the Spring Cloud Data Flow Shell app register command.
You must provide a unique name and a URI that can be resolved to the application artifact. For the type, specify task.
The following listing shows three examples:
dataflow:>app register --name task1 --type task --uri maven://com.example:mytask:1.0.2
dataflow:>app register --name task2 --type task --uri file:///Users/example/mytask-1.0.2.jar
dataflow:>app register --name task3 --type task --uri https://example.com/mytask-1.0.2.jarWhen providing a URI with the maven scheme, the format should conform to the following:
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version>If you would like to register multiple applications at one time, you can store them in a properties file where the keys are formatted as <type>.<name> and the values are the URIs.
For example, the following listing would be a valid properties file:
task.cat=file:///tmp/cat-1.2.1.BUILD-SNAPSHOT.jar
task.hat=file:///tmp/hat-1.2.1.BUILD-SNAPSHOT.jarThen you can use the app import command and provide the location of the properties file by using the --uri option, as follows:
app import --uri file:///tmp/task-apps.propertiesFor example, if you would like to register all the task applications that ship with Data Flow in a single operation, you can do so with the following command:
dataflow:>app import --uri https://dataflow.spring.io/task-maven-latestYou can also pass the --local option (which is TRUE by default) to indicate whether the properties file location should be resolved within the shell process itself.
If the location should be resolved from the Data Flow Server process, specify --local false.
When using either app register or app import, if a task application is already registered with
the provided name and version, it is not overridden by default. If you would like to override the
pre-existing task application with a different uri or uri-metadata location, include the --force option.
| In some cases, the resource is resolved on the server side. In other cases, the URI is passed to a runtime container instance, where it is resolved. Consult the specific documentation of each Data Flow Server for more detail. |
26.3. Creating a Task Definition
You can create a task definition from a task application by providing a definition name as well as
properties that apply to the task execution. You can create a task definition through
the RESTful API or the shell. To create a task definition by using the shell, use the
task create command to create the task definition, as shown in the following example:
dataflow:>task create mytask --definition "timestamp --format=\"yyyy\""
Created new task 'mytask'You can obtain a listing of the current task definitions through the RESTful API or the shell.
To get the task definition list by using the shell, use the task list command.
26.3.1. Maximum Task Definition Name Length
The maximum character length of a task definition name is dependent on the platform.
| Consult the platform documents for specifics on resource naming. The Local platform stores the task definition name in a database column with a maximum size of 255. |
| Kubernetes Bare Pods | Kubernetes Jobs | Cloud Foundry | Local |
|---|---|---|---|
63 |
52 |
63 |
255 |
26.3.2. Automating the Creation of Task Definitions
As of version 2.3.0, you can configure the Data Flow server to automatically create task definitions by setting spring.cloud.dataflow.task.autocreate-task-definitions to true.
This is not the default behavior but is provided as a convenience.
When this property is enabled, a task launch request can specify the registered task application name as the task name.
If the task application is registered, the server creates a basic task definition that specifies only the application name, as required. This eliminates a manual step similar to:
dataflow:>task create mytask --definition "mytask"You can still specify command-line arguments and deployment properties for each task launch request.
26.4. Launching a Task
An ad hoc task can be launched through the RESTful API or the shell.
To launch an ad hoc task through the shell, use the task launch command, as shown in the following example:
dataflow:>task launch mytask
Launched task 'mytask'When a task is launched, you can set any properties that need to be passed as command-line arguments to the task application when you launch the task, as follows:
dataflow:>task launch mytask --arguments "--server.port=8080 --custom=value"| The arguments need to be passed as space-delimited values. |
You can pass in additional properties meant for a TaskLauncher itself by using the --properties option.
The format of this option is a comma-separated string of properties prefixed with app.<task definition name>.<property>.
Properties are passed to TaskLauncher as application properties.
It is up to an implementation to choose how those are passed into an actual task application.
If the property is prefixed with deployer instead of app, it is passed to TaskLauncher as a deployment property, and its meaning may be TaskLauncher implementation specific.
dataflow:>task launch mytask --properties "deployer.timestamp.custom1=value1,app.timestamp.custom2=value2"26.4.1. Application properties
Each application takes properties to customize its behavior. For example, the timestamp task format setting establishes an output format that is different from the default value.
dataflow:> task create --definition "timestamp --format=\"yyyy\"" --name printTimeStampThis timestamp property is actually the same as the timestamp.format property specified by the timestamp application.
Data Flow adds the ability to use the shorthand form format instead of timestamp.format.
You can also specify the longhand version as well, as shown in the following example:
dataflow:> task create --definition "timestamp --timestamp.format=\"yyyy\"" --name printTimeStampThis shorthand behavior is discussed more in the section on Stream Application Properties.
If you have registered application property metadata, you can use tab completion in the shell after typing -- to get a list of candidate property names.
The shell provides tab completion for application properties. The app info --name <appName> --type <appType> shell command provides additional documentation for all the supported properties. The supported task <appType> is task.
When restarting Spring Batch Jobs on Kubernetes, you must use the entry point of shell or boot.
|
Application Properties With Sensitive Information on Kubernetes
When launching task applications where some of the properties may contain sensitive information, use the shell or boot as the entryPointStyle. This is because the exec (default) converts all properties to command-line arguments and, as a result, may not be secure in some environments.
26.4.2. Common application properties
In addition to configuration through DSL, Spring Cloud Data Flow provides a mechanism for setting properties that are common to all the task applications that are launched by it.
You can do so by adding properties prefixed with spring.cloud.dataflow.applicationProperties.task when starting the server.
The server then passes all the properties, without the prefix, to the instances it launches.
For example, you can configure all the launched applications to use the prop1 and prop2 properties by launching the Data Flow server with the following options:
--spring.cloud.dataflow.applicationProperties.task.prop1=value1
--spring.cloud.dataflow.applicationProperties.task.prop2=value2This causes the prop1=value1 and prop2=value2 properties to be passed to all the launched applications.
Properties configured by using this mechanism have lower precedence than task deployment properties.
They are overridden if a property with the same key is specified at task launch time (for example, app.trigger.prop2
overrides the common property).
|
26.5. Limit the number concurrent task launches
Spring Cloud Data Flow lets a user limit the maximum number of concurrently running tasks for each configured platform to prevent the saturation of IaaS or hardware resources.
By default, the limit is set to 20 for all supported platforms. If the number of concurrently running tasks on a platform instance is greater than or equal to the limit, the next task launch request fails, and an error message is returned through the RESTful API, the Shell, or the UI.
You can configure this limit for a platform instance by setting the corresponding deployer property, spring.cloud.dataflow.task.platform.<platform-type>.accounts[<account-name>].maximumConcurrentTasks, where <account-name> is the name of a configured platform account (default if no accounts are explicitly configured).
The <platform-type> refers to one of the currently supported deployers: local or kubernetes. For cloudfoundry, the property is spring.cloud.dataflow.task.platform.<platform-type>.accounts[<account-name>].deployment.maximumConcurrentTasks. (The difference is that deployment has been added to the path).
The TaskLauncher implementation for each supported platform determines the number of currently running tasks by querying the underlying platform’s runtime state, if possible. The method for identifying a task varies by platform.
For example, launching a task on the local host uses the LocalTaskLauncher. LocalTaskLauncher runs a process for each launch request and keeps track of these processes in memory. In this case, we do not query the underlying OS, as it is impractical to identify tasks this way.
For Cloud Foundry, tasks are a core concept supported by its deployment model. The state of all tasks ) is available directly through the API.
This means that every running task container in the account’s organization and space is included in the running execution count, whether or not it was launched by using Spring Cloud Data Flow or by invoking the CloudFoundryTaskLauncher directly.
For Kubernetes, launching a task through the KubernetesTaskLauncher, if successful, results in a running pod, which we expect to eventually complete or fail.
In this environment, there is generally no easy way to identify pods that correspond to a task.
For this reason, we count only pods that were launched by the KubernetesTaskLauncher.
Since the task launcher provides task-name label in the pod’s metadata, we filter all running pods by the presence of this label.
26.6. Reviewing Task Executions
Once the task is launched, the state of the task is stored in a relational database. The state includes:
-
Task Name
-
Start Time
-
End Time
-
Exit Code
-
Exit Message
-
Last Updated Time
-
Parameters
You can check the status of your task executions through the RESTful API or the shell.
To display the latest task executions through the shell, use the task execution list command.
To get a list of task executions for just one task definition, add --name and
the task definition name — for example, task execution list --name foo. To retrieve full
details for a task execution, use the task execution status command with the ID of the task execution,
for example task execution status --id 549.
26.7. Destroying a Task Definition
Destroying a task definition removes the definition from the definition repository.
This can be done through the RESTful API or the shell.
To destroy a task through the shell, use the task destroy command, as shown in the following example:
dataflow:>task destroy mytask
Destroyed task 'mytask'The task destroy command also has an option to cleanup the task executions of the task being destroyed, as shown in the following example:
dataflow:>task destroy mytask --cleanup
Destroyed task 'mytask'By default, the cleanup option is set to false (that is, by default, the task executions are not cleaned up when the task is destroyed).
To destroy all tasks through the shell, use the task all destroy command as shown in the following example:
dataflow:>task all destroy
Really destroy all tasks? [y, n]: y
All tasks destroyedIf need be, you can use the force switch:
dataflow:>task all destroy --force
All tasks destroyedThe task execution information for previously launched tasks for the definition remains in the task repository.
| This does not stop any currently running tasks for this definition. Instead, it removes the task definition from the database. |
|
+
. Obtain a list of the apps by using the |
26.8. Validating a Task
Sometimes, an application contained within a task definition has an invalid URI in its registration.
This can be caused by an invalid URI being entered at application-registration time or the by the application being removed from the repository from which it was to be drawn.
To verify that all the applications contained in a task are resolve-able, use the validate command, as follows:
dataflow:>task validate time-stamp
╔══════════╤═══════════════╗
║Task Name │Task Definition║
╠══════════╪═══════════════╣
║time-stamp│timestamp ║
╚══════════╧═══════════════╝
time-stamp is a valid task.
╔═══════════════╤═════════════════╗
║ App Name │Validation Status║
╠═══════════════╪═════════════════╣
║task:timestamp │valid ║
╚═══════════════╧═════════════════╝In the preceding example, the user validated their time-stamp task. The task:timestamp application is valid.
Now we can see what happens if we have a stream definition with a registered application that has an invalid URI:
dataflow:>task validate bad-timestamp
╔═════════════╤═══════════════╗
║ Task Name │Task Definition║
╠═════════════╪═══════════════╣
║bad-timestamp│badtimestamp ║
╚═════════════╧═══════════════╝
bad-timestamp is an invalid task.
╔══════════════════╤═════════════════╗
║ App Name │Validation Status║
╠══════════════════╪═════════════════╣
║task:badtimestamp │invalid ║
╚══════════════════╧═════════════════╝In this case, Spring Cloud Data Flow states that the task is invalid because task:badtimestamp has an invalid URI.
26.9. Stopping a Task Execution
In some cases, a task that is running on a platform may not stop because of a problem on the platform or the application business logic itself.
For such cases, Spring Cloud Data Flow offers the ability to send a request to the platform to end the task.
To do this, submit a task execution stop for a given set of task executions, as follows:
task execution stop --ids 5
Request to stop the task execution with id(s): 5 has been submittedWith the preceding command, the trigger to stop the execution of id=5 is submitted to the underlying deployer implementation. As a result, the operation stops that task. When we view the result for the task execution, we see that the task execution completed with a 0 exit code:
dataflow:>task execution list
╔══════════╤══╤════════════════════════════╤════════════════════════════╤═════════╗
║Task Name │ID│ Start Time │ End Time │Exit Code║
╠══════════╪══╪════════════════════════════╪════════════════════════════╪═════════╣
║batch-demo│5 │Mon Jul 15 13:58:41 EDT 2019│Mon Jul 15 13:58:55 EDT 2019│0 ║
║timestamp │1 │Mon Jul 15 09:26:41 EDT 2019│Mon Jul 15 09:26:41 EDT 2019│0 ║
╚══════════╧══╧════════════════════════════╧════════════════════════════╧═════════╝If you submit a stop for a task execution that has child task executions associated with it, such as a composed task, a stop request is sent for each of the child task executions.
When stopping a task execution that has a running Spring Batch job, the job is left with a batch status of STARTED.
Each of the supported platforms sends a SIG-INT to the task application when a stop is requested. That allows Spring Cloud Task to capture the state of the app. However, Spring Batch does not handle a SIG-INT and, as a result, the job stops but remains in the STARTED status.
|
26.9.1. Stopping a Task Execution that was Started Outside of Spring Cloud Data Flow
You may wish to stop a task that has been launched outside of Spring Cloud Data Flow. An example of this is the worker applications launched by a remote batch partitioned application.
In such cases, the remote batch partitioned application stores the external-execution-id for each of the worker applications. However, no platform information is stored.
So when Spring Cloud Data Flow has to stop a remote batch partitioned application and its worker applications, you need to specify the platform name, as follows:
dataflow:>task execution stop --ids 1 --platform myplatform
Request to stop the task execution with id(s): 1 for platform myplatform has been submitted27. Subscribing to Task and Batch Events
You can also tap into various task and batch events when the task is launched.
If the task is enabled to generate task or batch events (with the additional dependencies of spring-cloud-task-stream and, in the case of Kafka as the binder, spring-cloud-stream-binder-kafka), those events are published during the task lifecycle.
By default, the destination names for those published events on the broker (Rabbit, Kafka, and others) are the event names themselves (for instance: task-events, job-execution-events, and so on).
dataflow:>task create myTask --definition "myBatchJob"
dataflow:>stream create task-event-subscriber1 --definition ":task-events > log" --deploy
dataflow:>task launch myTaskYou can control the destination name for those events by specifying explicit names when launching the task, as follows:
dataflow:>stream create task-event-subscriber2 --definition ":myTaskEvents > log" --deploy
dataflow:>task launch myTask --properties "app.myBatchJob.spring.cloud.stream.bindings.task-events.destination=myTaskEvents"The following table lists the default task and batch event and destination names on the broker:
Event |
Destination |
Task events |
|
Job Execution events |
|
Step Execution events |
|
Item Read events |
|
Item Process events |
|
Item Write events |
|
Skip events |
|
28. Composed Tasks
Spring Cloud Data Flow lets you create a directed graph, where each node of the graph is a task application. This is done by using the DSL for composed tasks. You can create a composed task through the RESTful API, the Spring Cloud Data Flow Shell, or the Spring Cloud Data Flow UI.
28.1. Configuring the Composed Task Runner
Composed tasks are run through a task application called the Composed Task Runner.
28.1.1. Registering the Composed Task Runner
By default, Spring Cloud Data Flow retrieves the composed task runner application from Maven Central for Cloud Foundry and local deployments and DockerHub for Kubernetes. It retrieves the composed task runner upon the first use of composed tasks.
If Maven Central or DockerHub cannot be reached for a given Spring Cloud Data Flow
deployment, you can specify a new URI from which to retrieve the composed task runner by setting the
spring.cloud.dataflow.task.composedtaskrunner.uri property.
28.1.2. Configuring the Composed Task Runner
The composed task runner application has a dataflow-server-uri property that is used for validation and for launching child tasks.
This defaults to localhost:9393. If you run a distributed Spring Cloud Data Flow server, as you would if you deploy the server on Cloud Foundry or Kubernetes, you need to provide the URI that can be used to access the server.
You can either provide this by setting the dataflow-server-uri property for the composed task runner application when launching a composed task or by setting the spring.cloud.dataflow.server.uri property for the Spring Cloud Data Flow server when it is started.
For the latter case, the dataflow-server-uri composed task runner application property is automatically set when a composed task is launched.
Configuration Options
The ComposedTaskRunner task has the following options:
-
composed-task-argumentsThe command line arguments to be used for each of the tasks. (String, default: <none>). -
increment-instance-enabledAllows a singleComposedTaskRunnerinstance to be run again without changing the parameters. The default isfalse, which means aComposedTaskRunnerinstance can be started only once with a given set of parameters. Iftrueit can be re-started. (Boolean, default:false). ComposedTaskRunner is built by using Spring Batch. As a result, upon a successful execution, the batch job is considered to be complete. To launch the sameComposedTaskRunnerdefinition multiple times, you must set theincrement-instance-enabledproperty totrueor change the parameters for the definition for each launch. When using this option, it must be applied for all task launches for the desired application, including the first launch. -
interval-time-between-checksThe amount of time, in milliseconds, that theComposedTaskRunnerwaits between checks of the database to see if a task has completed. (Integer, default:10000).ComposedTaskRunneruses the datastore to determine the status of each child tasks. This interval indicates toComposedTaskRunnerhow often it should check the status its child tasks. -
max-wait-timeThe maximum amount of time, in milliseconds, that an individual step can run before the execution of the Composed task is failed (Integer, default: 0). Determines the maximum time each child task is allowed to run before the CTR ends with a failure. The default of0indicates no timeout. -
split-thread-allow-core-thread-timeoutSpecifies whether to allow split core threads to timeout. (Boolean, default:false) Sets the policy governing whether core threads may timeout and terminate if no tasks arrive within the keep-alive time, being replaced if needed when new tasks arrive. -
split-thread-core-pool-sizeSplit’s core pool size. (Integer, default:1) Each child task contained in a split requires a thread in order to execute. So, for example, a definition such as<AAA || BBB || CCC> && <DDD || EEE>would require asplit-thread-core-pool-sizeof3. This is because the largest split contains three child tasks. A count of2would mean thatAAAandBBBwould run in parallel, but CCC would wait until eitherAAAorBBBfinish in order to run. ThenDDDandEEEwould run in parallel. -
split-thread-keep-alive-secondsSplit’s thread keep alive seconds. (Integer, default:60) If the pool currently has more thancorePoolSizethreads, excess threads are stopped if they have been idle for more than thekeepAliveTime. -
split-thread-max-pool-sizeSplit’s maximum pool size. (Integer, default:Integer.MAX_VALUE). Establish the maximum number of threads allowed for the thread pool. -
split-thread-queue-capacity Capacity for Split’s
BlockingQueue. (Integer, default:Integer.MAX_VALUE)-
If fewer than
corePoolSizethreads are running, theExecutoralways prefers adding a new thread rather than queuing. -
If
corePoolSizeor more threads are running, theExecutoralways prefers queuing a request rather than adding a new thread. -
If a request cannot be queued, a new thread is created unless this would exceed
maximumPoolSize. In that case, the task is rejected.
-
-
split-thread-wait-for-tasks-to-complete-on-shutdownWhether to wait for scheduled tasks to complete on shutdown, not interrupting running tasks and running all tasks in the queue. (Boolean, default:false) -
dataflow-server-uriThe URI for the Data Flow server that receives task launch requests. (String, default:localhost:9393) -
dataflow-server-usernameThe optional username for the Data Flow server that receives task launch requests. Used to access the the Data Flow server by using Basic Authentication. Not used ifdataflow-server-access-tokenis set. -
dataflow-server-passwordThe optional password for the Data Flow server that receives task launch requests. Used to access the the Data Flow server by using Basic Authentication. Not used ifdataflow-server-access-tokenis set. -
dataflow-server-access-tokenThis property sets an optional OAuth2 Access Token. Typically, the value is automatically set by using the token from the currently logged-in user, if available. However, for special use-cases, this value can also be set explicitly.
A special boolean property, dataflow-server-use-user-access-token, exists for when you want to use the access token of the currently logged-in user and propagate it to the Composed Task Runner. This property is used
by Spring Cloud Data Flow and, if set to true, auto-populates the dataflow-server-access-token property. When using dataflow-server-use-user-access-token, it must be passed for each task execution.
In some cases, it may be preferred that the user’s dataflow-server-access-token must be passed for each composed task launch by default.
In this case, set the Spring Cloud Data Flow spring.cloud.dataflow.task.useUserAccessToken property to true.
To set a property for Composed Task Runner you will need to prefix the property with app.composed-task-runner..
For example to set the dataflow-server-uri property the property will look like app.composed-task-runner.dataflow-server-uri.
28.2. The Lifecycle of a Composed Task
The lifecycle of a composed task has three parts:
28.2.1. Creating a Composed Task
The DSL for the composed tasks is used when creating a task definition through the task create command, as shown in the following example:
dataflow:> app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:
dataflow:> app register --name mytaskapp --type task --uri file:///home/tasks/mytask.jar
dataflow:> task create my-composed-task --definition "mytaskapp && timestamp"
dataflow:> task launch my-composed-task In the preceding example, we assume that the applications to be used by our composed task have not yet been registered.
Consequently, in the first two steps, we register two task applications.
We then create our composed task definition by using the task create command.
The composed task DSL in the preceding example, when launched, runs mytaskapp and then runs the timestamp application.
But before we launch the my-composed-task definition, we can view what Spring Cloud Data Flow generated for us.
This can be done by using the task list command, as shown (including its output) in the following example:
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│unknown ║
║my-composed-task-mytaskapp│mytaskapp │unknown ║
║my-composed-task-timestamp│timestamp │unknown ║
╚══════════════════════════╧══════════════════════╧═══════════╝In the example, Spring Cloud Data Flow created three task definitions, one for each of the applications that makes up our composed task (my-composed-task-mytaskapp and my-composed-task-timestamp) as well as the composed task (my-composed-task) definition.
We also see that each of the generated names for the child tasks is made up of the name of the composed task and the name of the application, separated by a hyphen - (as in my-composed-task - mytaskapp).
Task Application Parameters
The task applications that make up the composed task definition can also contain parameters, as shown in the following example:
dataflow:> task create my-composed-task --definition "mytaskapp --displayMessage=hello && timestamp --format=YYYY"28.2.2. Launching a Composed Task
Launching a composed task is done in the same way as launching a stand-alone task, as follows:
task launch my-composed-taskOnce the task is launched, and assuming all the tasks complete successfully, you can see three task executions when you run a task execution list, as shown in the following example:
dataflow:>task execution list
╔══════════════════════════╤═══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID │ Start Time │ End Time │Exit Code║
╠══════════════════════════╪═══╪════════════════════════════╪════════════════════════════╪═════════╣
║my-composed-task-timestamp│713│Wed Apr 12 16:43:07 EDT 2017│Wed Apr 12 16:43:07 EDT 2017│0 ║
║my-composed-task-mytaskapp│712│Wed Apr 12 16:42:57 EDT 2017│Wed Apr 12 16:42:57 EDT 2017│0 ║
║my-composed-task │711│Wed Apr 12 16:42:55 EDT 2017│Wed Apr 12 16:43:15 EDT 2017│0 ║
╚══════════════════════════╧═══╧════════════════════════════╧════════════════════════════╧═════════╝In the preceding example, we see that my-compose-task launched and that the other tasks were also launched in sequential order.
Each of them ran successfully with an Exit Code as 0.
Passing Properties to the Child Tasks
To set the properties for child tasks in a composed task graph at task launch time,
use the following format: app.<composed task definition name>.<child task app name>.<property>.
The following listing shows a composed task definition as an example:
dataflow:> task create my-composed-task --definition "mytaskapp && mytimestamp"To have mytaskapp display 'HELLO' and set the mytimestamp timestamp format to YYYY for the composed task definition, use the following task launch format:
task launch my-composed-task --properties "app.my-composed-task.mytaskapp.displayMessage=HELLO,app.my-composed-task.mytimestamp.timestamp.format=YYYY"Similar to application properties, you can also set the deployer properties for child tasks by using the following format: deployer.<composed task definition name>.<child task app name>.<deployer-property>:
task launch my-composed-task --properties "deployer.my-composed-task.mytaskapp.memory=2048m,app.my-composed-task.mytimestamp.timestamp.format=HH:mm:ss"
Launched task 'a1'Passing Arguments to the Composed Task Runner
You can pass command-line arguments for the composed task runner by using the --arguments option:
dataflow:>task create my-composed-task --definition "<aaa: timestamp || bbb: timestamp>"
Created new task 'my-composed-task'
dataflow:>task launch my-composed-task --arguments "--increment-instance-enabled=true --max-wait-time=50000 --split-thread-core-pool-size=4" --properties "app.my-composed-task.bbb.timestamp.format=dd/MM/yyyy HH:mm:ss"
Launched task 'my-composed-task'Launching a Composed Task by using a Custom Composed Task Runner
In some cases, you need to launch a composed task by using a custom version of a composed task runner other than the default application that is shipped out-of-the-box.
To do this, you need to register the custom version of the composed task runner and then specify the composedTaskRunnerName property to point to the custom application at task launch, as follows:
dataflow:>app register --name best-ctr --type task --uri maven://the.best.ctr.composed-task-runner:1.0.0.RELEASE
dataflow:>task create mycomposedtask --definition "te:timestamp && tr:timestamp"
Created new task 'mycomposedtask'
dataflow:>task launch --name mycomposedtask --composedTaskRunnerName best-ctr
The application specified by the composedTaskRunnerName needs to be a task registered in the Application Registry.
|
Exit Statuses
The following list shows how the exit status is set for each step (task) contained in the composed task following each step execution:
-
If the
TaskExecutionhas anExitMessage, that is used as theExitStatus. -
If no
ExitMessageis present and theExitCodeis set to zero, theExitStatusfor the step isCOMPLETED. -
If no
ExitMessageis present and theExitCodeis set to any non-zero number, theExitStatusfor the step isFAILED.
28.2.3. Destroying a Composed Task
The command used to destroy a stand-alone task is the same as the command used to destroy a composed task.
The only difference is that destroying a composed task also destroys the child tasks associated with it.
The following example shows the task list before and after using the destroy command:
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│COMPLETED ║
║my-composed-task-mytaskapp│mytaskapp │COMPLETED ║
║my-composed-task-timestamp│timestamp │COMPLETED ║
╚══════════════════════════╧══════════════════════╧═══════════╝
...
dataflow:>task destroy my-composed-task
dataflow:>task list
╔═════════╤═══════════════╤═══════════╗
║Task Name│Task Definition│Task Status║
╚═════════╧═══════════════╧═══════════╝28.2.4. Stopping a Composed Task
In cases where a composed task execution needs to be stopped, you can do so through the:
-
RESTful API
-
Spring Cloud Data Flow Dashboard
To stop a composed task through the dashboard, select the Jobs tab and click the *Stop() button next to the job execution that you want to stop.
The composed task run is stopped when the currently running child task completes.
The step associated with the child task that was running at the time that the composed task was stopped is marked as STOPPED as well as the composed task job execution.
28.2.5. Restarting a Composed Task
In cases where a composed task fails during execution and the status of the composed task is FAILED, the task can be restarted.
You can do so through the:
-
RESTful API
-
The shell
-
Spring Cloud Data Flow Dashboard
To restart a composed task through the shell, launch the task with the same parameters. To restart a composed task through the dashboard, select the Jobs tab and click the Restart button next to the job execution that you want to restart.
Restarting a composed task job that has been stopped (through the Spring Cloud Data Flow Dashboard or RESTful API) relaunches the STOPPED child task and then launches the remaining (unlaunched) child tasks in the specified order.
|
29. Composed Tasks DSL
Composed tasks can be run in three ways:
29.1. Conditional Execution
Conditional execution is expressed by using a double ampersand symbol (&&).
This lets each task in the sequence be launched only if the previous task
successfully completed, as shown in the following example:
task create my-composed-task --definition "task1 && task2"When the composed task called my-composed-task is launched, it launches the task called task1 and, if task1 completes successfully, the task called task2 is launched.
If task1 fails, task2 does not launch.
You can also use the Spring Cloud Data Flow Dashboard to create your conditional execution, by using the designer to drag and drop applications that are required and connecting them together to create your directed graph, as shown in the following image:
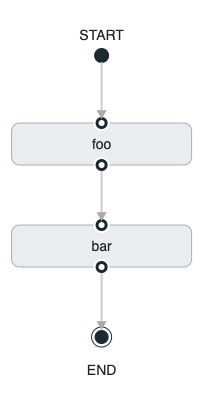
The preceding diagram is a screen capture of the directed graph as it being created by using the Spring Cloud Data Flow Dashboard. You can see that four components in the diagram comprise a conditional execution:
-
Start icon: All directed graphs start from this symbol. There is only one.
-
Task icon: Represents each task in the directed graph.
-
End icon: Represents the end of a directed graph.
-
Solid line arrow: Represents the flow conditional execution flow between:
-
Two applications.
-
The start control node and an application.
-
An application and the end control node.
-
-
End icon: All directed graphs end at this symbol.
| You can view a diagram of your directed graph by clicking the Detail button next to the composed task definition on the Definitions tab. |
29.2. Transitional Execution
The DSL supports fine-grained control over the transitions taken during the execution of the directed graph.
Transitions are specified by providing a condition for equality that is based on the exit status of the previous task.
A task transition is represented by the following symbol ->.
29.2.1. Basic Transition
A basic transition would look like the following:
task create my-transition-composed-task --definition "foo 'FAILED' -> bar 'COMPLETED' -> baz"In the preceding example, foo would launch, and, if it had an exit status of FAILED, the bar task would launch.
If the exit status of foo was COMPLETED, baz would launch.
All other statuses returned by cat have no effect, and the task would end normally.
Using the Spring Cloud Data Flow Dashboard to create the same “basic transition” would resemble the following image:
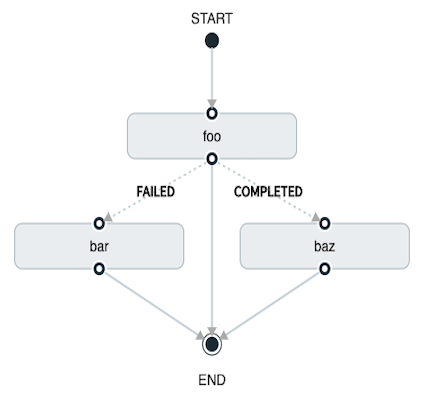
The preceding diagram is a screen capture of the directed graph as it being created in the Spring Cloud Data Flow Dashboard. Notice that there are two different types of connectors:
-
Dashed line: Represents transitions from the application to one of the possible destination applications.
-
Solid line: Connects applications in a conditional execution or a connection between the application and a control node (start or end).
To create a transitional connector:
-
When creating a transition, link the application to each possible destination by using the connector.
-
Once complete, go to each connection and select it by clicking it.
-
A bolt icon appears.
-
Click that icon.
-
Enter the exit status required for that connector.
-
The solid line for that connector turns to a dashed line.
29.2.2. Transition With a Wildcard
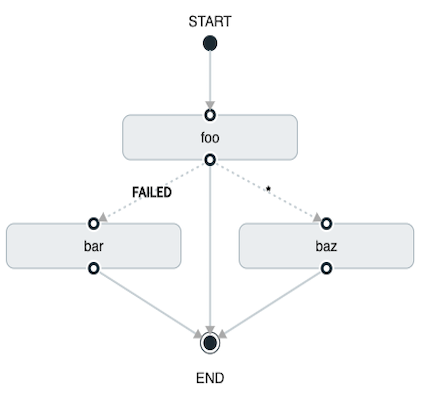
Wildcards are supported for transitions by the DSL, as shown in the following example:
task create my-transition-composed-task --definition "foo 'FAILED' -> bar '*' -> baz"In the preceding example, foo would launch, and, if it had an exit status of FAILED, bar task would launch.
For any exit status of cat other than FAILED, baz would launch.
Using the Spring Cloud Data Flow Dashboard to create the same “transition with wildcard” would resemble the following image:
29.2.3. Transition With a Following Conditional Execution
A transition can be followed by a conditional execution, so long as the wildcard is not used, as shown in the following example:
task create my-transition-conditional-execution-task --definition "foo 'FAILED' -> bar 'UNKNOWN' -> baz && qux && quux"In the preceding example, foo would launch, and, if it had an exit status of FAILED, the bar task would launch.
If foo had an exit status of UNKNOWN, baz would launch.
For any exit status of foo other than FAILED or UNKNOWN, qux would launch and, upon successful completion, quux would launch.
Using the Spring Cloud Data Flow Dashboard to create the same “transition with conditional execution” would resemble the following image:
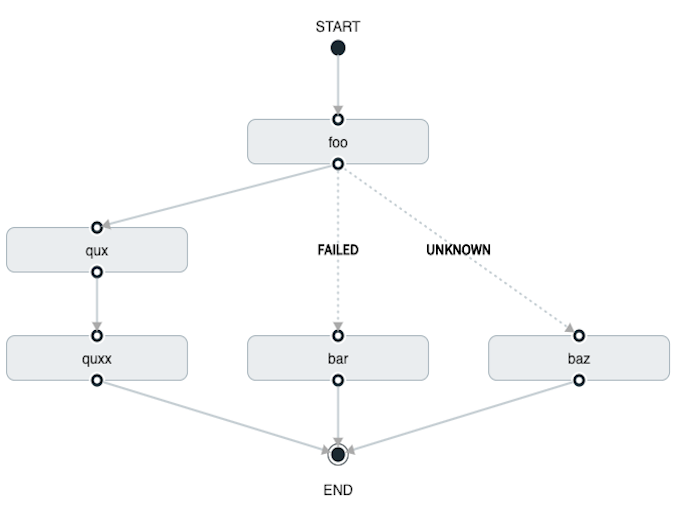
In this diagram, the dashed line (transition) connects the foo application to the target applications, but a solid line connects the conditional executions between foo, qux, and quux.
|
29.3. Split Execution
Splits let multiple tasks within a composed task be run in parallel.
It is denoted by using angle brackets (<>) to group tasks and flows that are to be run in parallel.
These tasks and flows are separated by the double pipe || symbol, as shown in the following example:
task create my-split-task --definition "<foo || bar || baz>"The preceding example launches tasks foo, bar and baz in parallel.
Using the Spring Cloud Data Flow Dashboard to create the same “split execution” would resemble the following image:
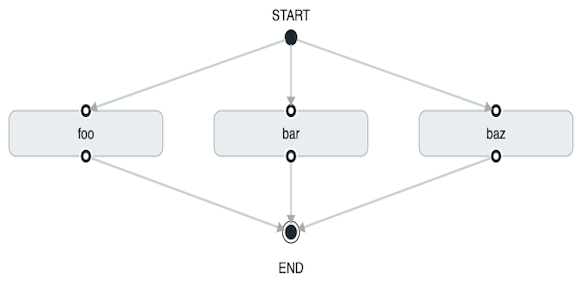
With the task DSL, you can also run multiple split groups in succession, as shown in the following example:
task create my-split-task --definition "<foo || bar || baz> && <qux || quux>"In the preceding example, the foo, bar, and baz tasks are launched in parallel.
Once they all complete, then the qux and quux tasks are launched in parallel.
Once they complete, the composed task ends.
However, if foo, bar, or baz fails, the split containing qux and quux does not launch.
Using the Spring Cloud Data Flow Dashboard to create the same “split with multiple groups” would resemble the following image:
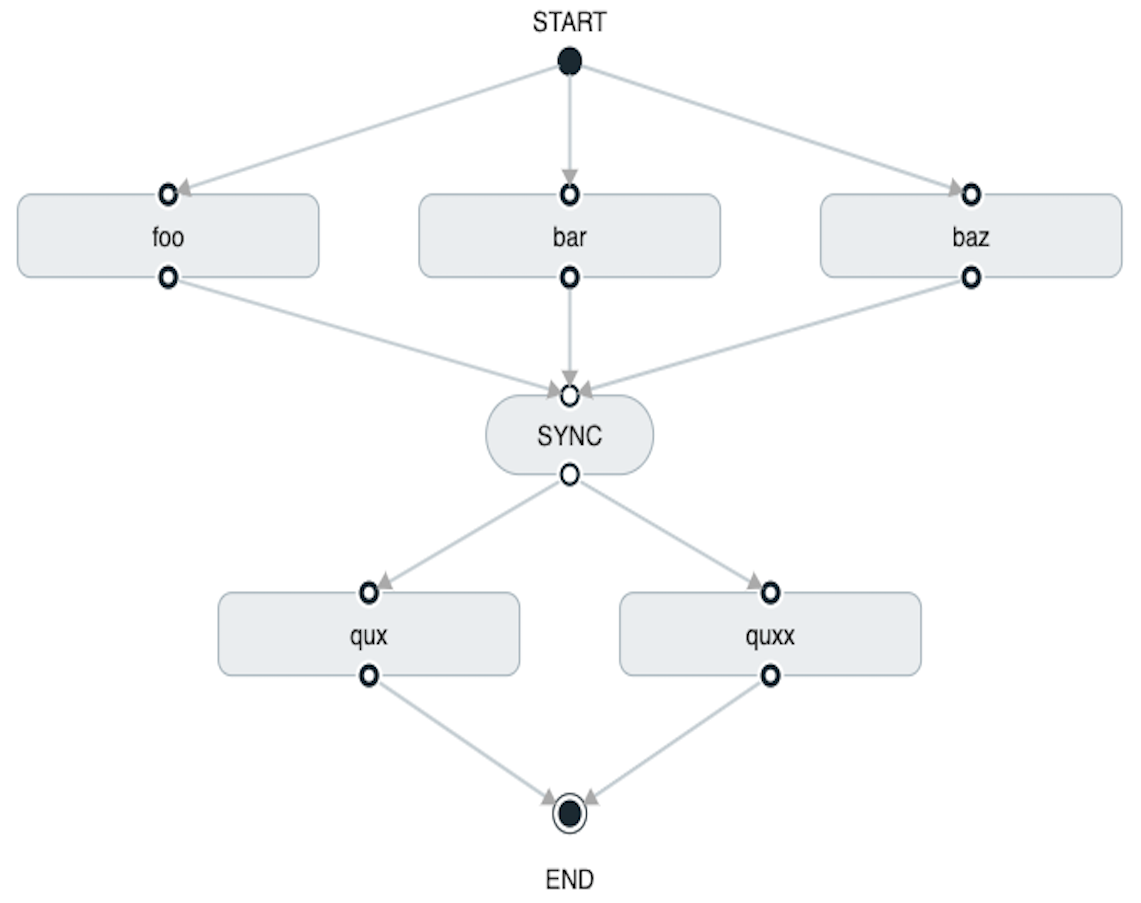
Notice that there is a SYNC control node that is inserted by the designer when
connecting two consecutive splits.
Tasks that are used in a split should not set the their ExitMessage. Setting the ExitMessage is only to be used
with transitions.
|
29.3.1. Split Containing Conditional Execution
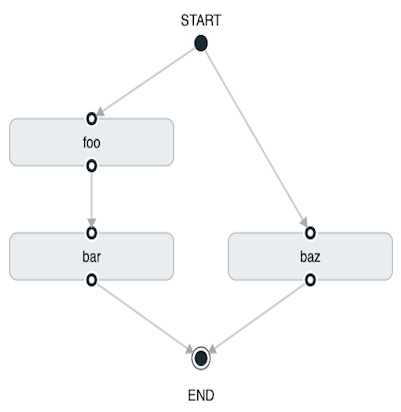
A split can also have a conditional execution within the angle brackets, as shown in the following example:
task create my-split-task --definition "<foo && bar || baz>"In the preceding example, we see that foo and baz are launched in parallel.
However, bar does not launch until foo completes successfully.
Using the Spring Cloud Data Flow Dashboard to create the same " split containing conditional execution " resembles the following image:
29.3.2. Establishing the Proper Thread Count for Splits
Each child task contained in a split requires a thread in order to run. To set this properly, you want to look at your graph and find the split that has the largest number of child tasks. The number of child tasks in that split is the number of threads you need.
To set the thread count, use the split-thread-core-pool-size property (defaults to 1). So, for example, a definition such as <AAA || BBB || CCC> && <DDD || EEE> requires a split-thread-core-pool-size of 3.
This is because the largest split contains three child tasks. A count of two would mean that AAA and BBB would run in parallel but CCC would wait for either AAA or BBB to finish in order to run.
Then DDD and EEE would run in parallel.
30. Launching Tasks from a Stream
You can launch a task from a stream by using the task-launcher-dataflow sink.
The sink connects to a Data Flow server and uses its REST API to launch any defined task.
The sink accepts a JSON payload representing a task launch request, which provides the name of the task to launch and may include command line arguments and deployment properties.
The app-starters-task-launch-request-common component, in conjunction with Spring Cloud Stream functional composition, can transform the output of any source or processor to a task launch request.
Adding a dependency to app-starters-task-launch-request-common auto-configures a java.util.function.Function implementation, registered through Spring Cloud Function as a taskLaunchRequest.
For example, you can start with the time source, add the following dependency, build it, and register it as a custom source. We call it time-tlr in this example:
<dependency>
<groupId>org.springframework.cloud.stream.app</groupId>
<artifactId>app-starters-task-launch-request-common</artifactId>
</dependency>| Spring Cloud Stream Initializr provides a great starting point for creating stream applications. |
Next, register the task-launcher-dataflow sink and create a task (we use the provided timestamp task):
stream create --name task-every-minute --definition "time-tlr --trigger.fixed-delay=60 --spring.cloud.stream.function.definition=taskLaunchRequest --task.launch.request.task-name=timestamp-task | task-launcher-dataflow" --deployThe preceding stream produces a task launch request every minute. The request provides the name of the task to launch: {"name":"timestamp-task"}.
The following stream definition illustrates the use of command line arguments. It produces messages such as {"args":["foo=bar","time=12/03/18 17:44:12"],"deploymentProps":{},"name":"timestamp-task"} to provide command-line arguments to the task:
stream create --name task-every-second --definition "time-tlr --spring.cloud.stream.function.definition=taskLaunchRequest --task.launch.request.task-name=timestamp-task --task.launch.request.args=foo=bar --task.launch.request.arg-expressions=time=payload | task-launcher-dataflow" --deployNote the use of SpEL expressions to map each message payload to the time command-line argument, along with a static argument (foo=bar).
You can then see the list of task executions by using the shell command task execution list, as shown (with its output) in the following example:
dataflow:>task execution list
╔════════════════════╤══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID│ Start Time │ End Time │Exit Code║
╠════════════════════╪══╪════════════════════════════╪════════════════════════════╪═════════╣
║timestamp-task_26176│4 │Tue May 02 12:13:49 EDT 2017│Tue May 02 12:13:49 EDT 2017│0 ║
║timestamp-task_32996│3 │Tue May 02 12:12:49 EDT 2017│Tue May 02 12:12:49 EDT 2017│0 ║
║timestamp-task_58971│2 │Tue May 02 12:11:50 EDT 2017│Tue May 02 12:11:50 EDT 2017│0 ║
║timestamp-task_13467│1 │Tue May 02 12:10:50 EDT 2017│Tue May 02 12:10:50 EDT 2017│0 ║
╚════════════════════╧══╧════════════════════════════╧════════════════════════════╧═════════╝In this example, we have shown how to use the time source to launch a task at a fixed rate.
This pattern may be applied to any source to launch a task in response to any event.
30.1. Launching a Composed Task From a Stream
A composed task can be launched with the task-launcher-dataflow sink, as discussed here.
Since we use the ComposedTaskRunner directly, we need to set up the task definitions for the composed task runner itself, along with the composed tasks, prior to the creation of the composed task launching stream.
Suppose we wanted to create the following composed task definition: AAA && BBB.
The first step would be to create the task definitions, as shown in the following example:
task create composed-task-runner --definition "composed-task-runner"
task create AAA --definition "timestamp"
task create BBB --definition "timestamp"
Releases of ComposedTaskRunner can be found
here.
|
Now that the task definitions we need for composed task definition are ready, we need to create a stream that launches ComposedTaskRunner.
So, in this case, we create a stream with:
-
The
timesource customized to emit task launch requests, as shown earlier. -
The
task-launcher-dataflowsink that launches theComposedTaskRunner
The stream should resemble the following:
stream create ctr-stream --definition "time --fixed-delay=30 --task.launch.request.task-name=composed-task-launcher --task.launch.request.args=--graph=AAA&&BBB,--increment-instance-enabled=true | task-launcher-dataflow"For now, we focus on the configuration that is required to launch the ComposedTaskRunner:
-
graph: This is the graph that is to be executed by theComposedTaskRunner. In this case it isAAA&&BBB. -
increment-instance-enabled: This lets each execution ofComposedTaskRunnerbe unique.ComposedTaskRunneris built by using Spring Batch. Thus, we want a new Job Instance for each launch of theComposedTaskRunner. To do this, we setincrement-instance-enabledto betrue.
31. Sharing Spring Cloud Data Flow’s Datastore with Tasks
As discussed in the Tasks documentation, Spring Cloud Data Flow lets you view Spring Cloud Task application executions. So, in this section, we discuss what is required for a task application and Spring Cloud Data Flow to share the task execution information.
31.1. A Common DataStore Dependency
Spring Cloud Data Flow supports many databases out-of-the-box,
so all you typically need to do is declare the spring_datasource_* environment variables
to establish what data store Spring Cloud Data Flow needs.
Regardless of which database you decide to use for Spring Cloud Data Flow, make sure that your task also
includes that database dependency in its pom.xml or gradle.build file. If the database dependency
that is used by Spring Cloud Data Flow is not present in the Task Application, the task fails
and the task execution is not recorded.
31.2. A Common Data Store
Spring Cloud Data Flow and your task application must access the same datastore instance. This is so that the task executions recorded by the task application can be read by Spring Cloud Data Flow to list them in the Shell and Dashboard views. Also, the task application must have read and write privileges to the task data tables that are used by Spring Cloud Data Flow.
Given this understanding of the datasource dependency between Task applications and Spring Cloud Data Flow, you can now review how to apply them in various Task orchestration scenarios.
31.2.1. Simple Task Launch
When launching a task from Spring Cloud Data Flow, Data Flow adds its datasource
properties (spring.datasource.url, spring.datasource.driverClassName, spring.datasource.username, spring.datasource.password)
to the application properties of the task being launched. Thus, a task application
records its task execution information to the Spring Cloud Data Flow repository.
31.2.2. Composed Task Runner
Spring Cloud Data Flow lets you create a directed graph where each node
of the graph is a task application. This is done through the
composed task runner.
In this case, the rules that applied to a simple task launch
or task launcher sink apply to the composed task runner as well.
All child applications must also have access to the datastore that is being used by the composed task runner.
Also, all child applications must have the same database dependency as the composed task runner enumerated in their pom.xml or gradle.build file.
31.2.3. Launching a Task Externally from Spring Cloud Data Flow
You can launch Spring Cloud Task applications by using another method (scheduler, for example) but still track the task execution in Spring Cloud Data Flow. You can do so, provided the task applications observe the rules specified here and here.
If you want to use Spring Cloud Data Flow to view your
Spring Batch jobs, make sure that
your batch application uses the @EnableTask annotation and follow the rules enumerated here and here.
More information is available here.
|
32. Scheduling Tasks
Spring Cloud Data Flow lets you schedule the execution of tasks with a cron expression.
You can create a schedule through the RESTful API or the Spring Cloud Data Flow UI.
32.1. The Scheduler
Spring Cloud Data Flow schedules the execution of its tasks through a scheduling agent that is available on the cloud platform. When using the Cloud Foundry platform, Spring Cloud Data Flow uses the PCF Scheduler. When using Kubernetes, a CronJob will be used.
| Scheduled tasks do not implement the continuous deployment feature. Any changes to application version or properties for a task definition in Spring Cloud Data Flow will not affect scheduled tasks. |

32.2. Enabling Scheduling
By default, Spring Cloud Data Flow leaves the scheduling feature disabled. To enable the scheduling feature, set the following feature properties to true:
-
spring.cloud.dataflow.features.schedules-enabled -
spring.cloud.dataflow.features.tasks-enabled
32.3. The Lifecycle of a Schedule
The lifecycle of a schedule has three parts:
32.3.1. Scheduling a Task Execution
You can schedule a task execution via the:
-
Spring Cloud Data Flow Shell
-
Spring Cloud Data Flow Dashboard
-
Spring Cloud Data Flow RESTful API
32.3.2. Scheduling a Task
To schedule a task using the shell, use the task schedule create command to create the schedule, as shown in the following example:
dataflow:>task schedule create --definitionName mytask --name mytaskschedule --expression '*/1 * * * *'
Created schedule 'mytaskschedule'In the earlier example, we created a schedule called mytaskschedule for the task definition called mytask. This schedule launches mytask once a minute.
If using Cloud Foundry, the cron expression above would be: */1 * ? * *. This is because Cloud Foundry uses the Quartz cron expression format.
|
Maximum Length for a Schedule Name
The maximum character length of a schedule name is dependent on the platform.
| Kubernetes | Cloud Foundry | Local |
|---|---|---|
52 |
63 |
N/A |
32.3.3. Deleting a Schedule
You can delete a schedule by using the:
-
Spring Cloud Data Flow Shell
-
Spring Cloud Data Flow Dashboard
-
Spring Cloud Data Flow RESTful API
To delete a task schedule by using the shell, use the task schedule destroy command, as shown in the following example:
dataflow:>task schedule destroy --name mytaskschedule
Deleted task schedule 'mytaskschedule'32.3.4. Listing Schedules
You can view the available schedules by using the:
-
Spring Cloud Data Flow Shell
-
Spring Cloud Data Flow Dashboard
-
Spring Cloud Data Flow RESTful API
To view your schedules from the shell, use the task schedule list command, as shown in the following example:
dataflow:>task schedule list
╔══════════════════════════╤════════════════════╤════════════════════════════════════════════════════╗
║ Schedule Name │Task Definition Name│ Properties ║
╠══════════════════════════╪════════════════════╪════════════════════════════════════════════════════╣
║mytaskschedule │mytask │spring.cloud.scheduler.cron.expression = */1 * * * *║
╚══════════════════════════╧════════════════════╧════════════════════════════════════════════════════╝| Instructions to create, delete, and list schedules by using the Spring Cloud Data Flow UI can be found here. |
33. Continuous Deployment
As task applications evolve, you want to get your updates to production. This section walks through the capabilities that Spring Cloud Data Flow provides around being able to update task applications.
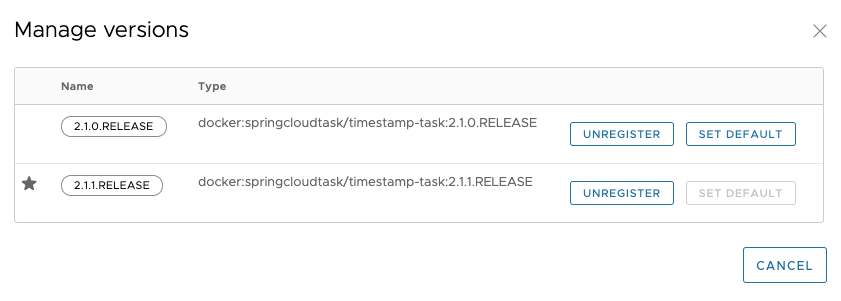
When a task application is registered (see Registering a Task Application), a version is associated with it. A task application can have multiple versions associated with it, with one selected as the default. The following image illustrates an application with multiple versions associated with it (see the timestamp entry).
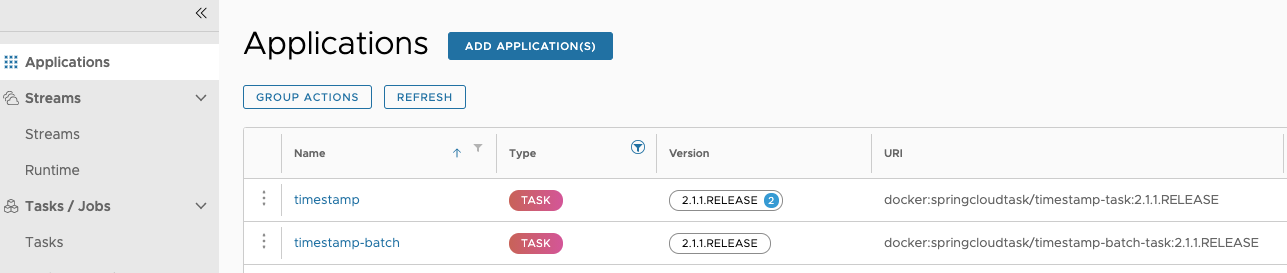
Versions of an application are managed by registering multiple applications with the same name and coordinates, except the version. For example, if you were to register an application with the following values, you would get one application registered with two versions (2.1.0.RELEASE and 2.1.1.RELEASE):
-
Application 1
-
Name:
timestamp -
Type:
task -
URI:
maven://org.springframework.cloud.task.app:timestamp-task:2.1.0.RELEASE
-
-
Application 2
-
Name:
timestamp -
Type:
task -
URI:
maven://org.springframework.cloud.task.app:timestamp-task:2.1.1.RELEASE
-
Besides having multiple versions, Spring Cloud Data Flow needs to know which version to run on the next launch. This is indicated by setting a version to be the default version. Whatever version of a task application is configured as the default version is the one to be run on the next launch request. You can see which version is the default in the UI, as this image shows:
33.1. Task Launch Lifecycle
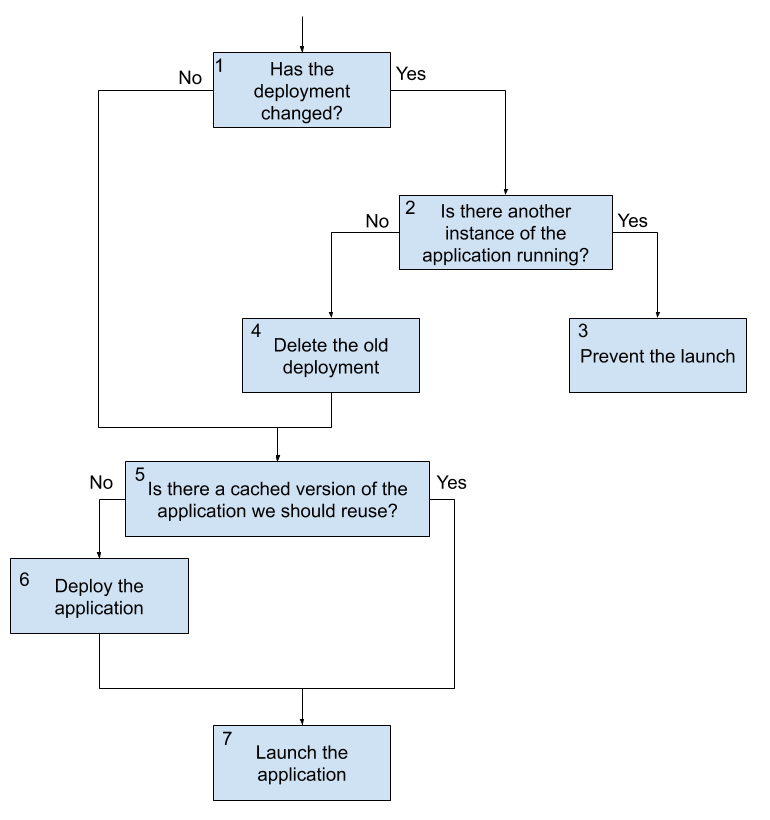
In previous versions of Spring Cloud Data Flow, when the request to launch a task was received, Spring Cloud Data Flow would deploy the application (if needed) and run it. If the application was being run on a platform that did not need to have the application deployed every time (CloudFoundry, for example), the previously deployed application was used. This flow has changed in 2.3. The following image shows what happens when a task launch request comes in now:
There are three main flows to consider in the preceding diagram. Launching the first time or launching with no changes is one. The other two are launching when there are changes but the appliction is not currently and launching when there are changes and the application is running. We look at the flow with no changes first.
33.1.1. Launching a Task With No Changes
-
A launch request comes into Data Flow. Data Flow determines that an upgrade is not required, since nothing has changed (no properties, deployment properties, or versions have changed since the last execution).
-
On platforms that cache a deployed artifact (CloudFoundry, at this writing), Data Flow checks whether the application was previously deployed.
-
If the application needs to be deployed, Data Flow deploys the task application.
-
Data Flow launches the application.
This flow is the default behavior and, if nothing has changed, occurs every time a request comes in. Note that this is the same flow that Data Flow has always use for launching tasks.
33.1.2. Launching a Task With Changes That Is Not Currently Running
The second flow to consider when launching a task is when a task is not running but there is a change in any of the task application version, application properties, or deployment properties. In this case, the following flow is executed:
-
A launch request comes into Data Flow. Data Flow determines that an upgrade is required, since there was a change in the task application version, the application properties, or the deployment properties.
-
Data Flow checks to see whether another instance of the task definition is currently running.
-
If there is no other instance of the task definition currently running, the old deployment is deleted.
-
On platforms that cache a deployed artifact (CloudFoundry, at this writing), Data Flow checks whether the application was previously deployed (this check evaluates to
falsein this flow, since the old deployment was deleted). -
Data Flow does the deployment of the task application with the updated values (new application version, new merged properties, and new merged deployment properties).
-
Data Flow launches the application.
This flow is what fundamentally enables continuous deployment for Spring Cloud Data Flow.
33.1.3. Launch a Task With Changes While Another Instance Is Running
The last main flow is when a launch request comes to Spring Cloud Data Flow to do an upgrade but the task definition is currently running. In this case, the launch is blocked due to the requirement to delete the current application. On some platforms (CloudFoundry, at this writing), deleting the application causes all currently running applications to be shut down. This feature prevents that from happening. The following process describes what happens when a task changes while another instance is running:
-
A launch request comes into Data Flow. Data Flow determines that an upgrade is required, since there was a change in the task application version, the application properties, or the deployment properties.
-
Data Flow checks to see whether another instance of the task definition is currently running.
-
Data Flow prevents the launch from happening, because other instances of the task definition are running.
| Any launch that requires an upgrade of a task definition that is running at the time of the request is blocked from running due to the need to delete any currently running tasks. |