Appendices
Having trouble with Spring Cloud Data Flow, We’d like to help!
-
Ask a question. We monitor stackoverflow.com for questions tagged with
spring-cloud-dataflow. -
Report bugs with Spring Cloud Data Flow at github.com/spring-cloud/spring-cloud-dataflow/issues.
Appendix A: Data Flow Template
As described in API Guide chapter, Spring Cloud Data Flow’s functionality is completely exposed through REST endpoints. While you can use those endpoints directly, Spring Cloud Data Flow also provides a Java-based API, which makes using those REST endpoints even easier.
The central entry point is the DataFlowTemplate class in the org.springframework.cloud.dataflow.rest.client package.
This class implements the DataFlowOperations interface and delegates to the following sub-templates that provide the specific functionality for each feature-set:
| Interface | Description |
|---|---|
|
REST client for stream operations |
|
REST client for counter operations |
|
REST client for field value counter operations |
|
REST client for aggregate counter operations |
|
REST client for task operations |
|
REST client for job operations |
|
REST client for app registry operations |
|
REST client for completion operations |
|
REST Client for runtime operations |
When the DataFlowTemplate is being initialized, the sub-templates can be discovered through the REST relations, which are provided by HATEOAS (Hypermedia as the Engine of Application State).
| If a resource cannot be resolved, the respective sub-template results in NULL. A common cause is that Spring Cloud Data Flow allows for specific sets of features to be enabled or disabled when launching. For more information, see one of the local, Cloud Foundry, or Kubernetes configuration chapters, depending on where you deploy your application. |
A.1. Using the Data Flow Template
When you use the Data Flow Template, the only needed Data Flow dependency is the Spring Cloud Data Flow Rest Client, as shown in the following Maven snippet:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dataflow-rest-client</artifactId>
<version>2.11.5</version>
</dependency>With that dependency, you get the DataFlowTemplate class as well as all the dependencies needed to make calls to a Spring Cloud Data Flow server.
When instantiating the DataFlowTemplate, you also pass in a RestTemplate.
Note that the needed RestTemplate requires some additional configuration to be valid in the context of the DataFlowTemplate.
When declaring a RestTemplate as a bean, the following configuration suffices:
@Bean
public static RestTemplate restTemplate() {
RestTemplate restTemplate = new RestTemplate();
restTemplate.setErrorHandler(new VndErrorResponseErrorHandler(restTemplate.getMessageConverters()));
for(HttpMessageConverter<?> converter : restTemplate.getMessageConverters()) {
if (converter instanceof MappingJackson2HttpMessageConverter) {
final MappingJackson2HttpMessageConverter jacksonConverter =
(MappingJackson2HttpMessageConverter) converter;
jacksonConverter.getObjectMapper()
.registerModule(new Jackson2HalModule())
.addMixIn(JobExecution.class, JobExecutionJacksonMixIn.class)
.addMixIn(JobParameters.class, JobParametersJacksonMixIn.class)
.addMixIn(JobParameter.class, JobParameterJacksonMixIn.class)
.addMixIn(JobInstance.class, JobInstanceJacksonMixIn.class)
.addMixIn(ExitStatus.class, ExitStatusJacksonMixIn.class)
.addMixIn(StepExecution.class, StepExecutionJacksonMixIn.class)
.addMixIn(ExecutionContext.class, ExecutionContextJacksonMixIn.class)
.addMixIn(StepExecutionHistory.class, StepExecutionHistoryJacksonMixIn.class);
}
}
return restTemplate;
}
You can also get a pre-configured RestTemplate by using
DataFlowTemplate.getDefaultDataflowRestTemplate();
|
Now you can instantiate the DataFlowTemplate with the following code:
DataFlowTemplate dataFlowTemplate = new DataFlowTemplate(
new URI("http://localhost:9393/"), restTemplate); (1)
| 1 | The URI points to the ROOT of your Spring Cloud Data Flow Server. |
Depending on your requirements, you can now make calls to the server. For instance, if you want to get a list of the currently available applications, you can run the following code:
PagedResources<AppRegistrationResource> apps = dataFlowTemplate.appRegistryOperations().list();
System.out.println(String.format("Retrieved %s application(s)",
apps.getContent().size()));
for (AppRegistrationResource app : apps.getContent()) {
System.out.println(String.format("App Name: %s, App Type: %s, App URI: %s",
app.getName(),
app.getType(),
app.getUri()));
}
A.2. Data Flow Template and Security
When using the DataFlowTemplate, you can also provide all the security-related
options as if you were using the Data Flow Shell. In fact, the Data Flow Shell
uses the DataFlowTemplate for all its operations.
To let you get started, we provide a HttpClientConfigurer that uses the builder
pattern to set the various security-related options:
HttpClientConfigurer
.create(targetUri) (1)
.basicAuthCredentials(username, password) (2)
.skipTlsCertificateVerification() (3)
.withProxyCredentials(proxyUri, proxyUsername, proxyPassword) (4)
.addInterceptor(interceptor) (5)
.buildClientHttpRequestFactory() (6)
| 1 | Creates a HttpClientConfigurer with the provided target URI. |
| 2 | Sets the credentials for basic authentication (Using OAuth2 Password Grant) |
| 3 | Skip SSL certificate verification (Use for DEVELOPMENT ONLY!) |
| 4 | Configure any Proxy settings |
| 5 | Add a custom interceptor e.g. to set the OAuth2 Authorization header. This allows you to pass an OAuth2 Access Token instead of username/password credentials. |
| 6 | Builds the ClientHttpRequestFactory that can be set on the RestTemplate. |
Once the HttpClientConfigurer is configured, you can use its buildClientHttpRequestFactory
to build the ClientHttpRequestFactory and then set the corresponding
property on the RestTemplate. You can then instantiate the actual DataFlowTemplate
using that RestTemplate.
To configure Basic Authentication, the following setup is required:
RestTemplate restTemplate = DataFlowTemplate.getDefaultDataflowRestTemplate();
HttpClientConfigurer httpClientConfigurer = HttpClientConfigurer.create("http://localhost:9393");
httpClientConfigurer.basicAuthCredentials("my_username", "my_password");
restTemplate.setRequestFactory(httpClientConfigurer.buildClientHttpRequestFactory());
DataFlowTemplate dataFlowTemplate = new DataFlowTemplate("http://localhost:9393", restTemplate);
Appendix B: “How-to” guides
This section provides answers to some common ‘how do I do that…’ questions that often arise when people use Spring Cloud Data Flow.
If you have a specific problem that we do not cover here, you might want to check out stackoverflow.com to see if someone has already provided an answer.
That is also a great place to ask new questions (use the spring-cloud-dataflow tag).
We are also more than happy to extend this section. If you want to add a “how-to”, you can send us a pull request.
B.1. Configure Maven Properties
If applications are resolved by using the Maven repository you may want to configure the underlying resolver.
You can set the Maven properties, such as the local Maven repository location, remote Maven repositories, authentication credentials, and proxy server properties through command-line properties when you start the Data Flow server.
Alternatively, you can set the properties by setting the SPRING_APPLICATION_JSON environment property for the Data Flow server.
For all Data Flow server installations, the following list of remote Maven repositories are configured by default:
-
Maven Central (
repo.maven.apache.org/maven2) -
Spring Snapshots (
repo.spring.io/snapshot) -
Spring Milestones (
repo.spring.io/milestone)
If the default is already explicitly configured (exact match on the repo url) then it will not be included.
If the applications exist on another remote repository, besides the pre-configured ones, that remote repository must be configured explicitly and will be added to the pre-configured default list.
To skip the automatic default repositories behavior altogether, set the maven.include-default-remote-repos property to false.
|
To pass the properties as command-line options, run the server with a command similar to the following:
java -jar <dataflow-server>.jar --maven.localRepoitory=mylocal \
--maven.remote-repositories.repo1.url=https://repo1 \
--maven.remote-repositories.repo1.auth.username=repo1user \
--maven.remote-repositories.repo1.auth.password=repo1pass \
--maven.remote-repositories.repo2.url=https://repo2 \
--maven.proxy.host=proxyhost \
--maven.proxy.port=9018 \
--maven.proxy.auth.username=proxyuser \
--maven.proxy.auth.password=proxypassYou can also use the SPRING_APPLICATION_JSON environment property:
export SPRING_APPLICATION_JSON='{ "maven": { "local-repository": "local","remote-repositories": { "repo1": { "url": "https://repo1", "auth": { "username": "repo1user", "password": "repo1pass" } },
"repo2": { "url": "https://repo2" } }, "proxy": { "host": "proxyhost", "port": 9018, "auth": { "username": "proxyuser", "password": "proxypass" } } } }'Here is the same content in nicely formatted JSON:
SPRING_APPLICATION_JSON='{
"maven": {
"local-repository": "local",
"remote-repositories": {
"repo1": {
"url": "https://repo1",
"auth": {
"username": "repo1user",
"password": "repo1pass"
}
},
"repo2": {
"url": "https://repo2"
}
},
"proxy": {
"host": "proxyhost",
"port": 9018,
"auth": {
"username": "proxyuser",
"password": "proxypass"
}
}
}
}'You can also set the properties as individual environment variables:
export MAVEN_REMOTEREPOSITORIES_REPO1_URL=https://repo1
export MAVEN_REMOTEREPOSITORIES_REPO1_AUTH_USERNAME=repo1user
export MAVEN_REMOTEREPOSITORIES_REPO1_AUTH_PASSWORD=repo1pass
export MAVEN_REMOTEREPOSITORIES_REPO2_URL=https://repo2
export MAVEN_PROXY_HOST=proxyhost
export MAVEN_PROXY_PORT=9018
export MAVEN_PROXY_AUTH_USERNAME=proxyuser
export MAVEN_PROXY_AUTH_PASSWORD=proxypassB.3. Extending application classpath
Users may require the addition of dependencies to the existing Stream applications or specific database drivers to Dataflow and Skipper or any of the other containers provider by the project.
The Spring Cloud Dataflow repository contains scripts to help with this task. The examples below assume you have cloned the spring-cloud-dataflow repository and are executing the scripts from src/add-deps.
|
B.3.1. JAR File
We suggest you publish the updated jar it to a private Maven repository and that the Maven Coordinates of the private registry is then used to register application with SCDF.
Example
This example:
* assumes the jar is downloaded to ${appFolder}/${appName}-${appVersion}.jar
* adds the dependencies and then publishes the jar to Maven local.
./gradlew -i publishToMavenLocal \
-P appFolder="." \
-P appGroup="org.springframework.cloud" \
-P appName="spring-cloud-dataflow-server" \
-P appVersion="2.11.3" \
-P depFolder="./extra-libs"
Use the publishMavenPublicationToMavenRepository task to publish to a remote repository. Update the gradle.properties with the remote repository details. Alternatively move repoUser and repoPassword to ~/.gradle/gradle.properties
|
B.3.2. Containers
In order to create a container we suggest using paketo pack cli to create a container from the jar created in previous step.
REPO=springcloud/spring-cloud-dataflow-server
TAG=2.11.3
JAR=build/spring-cloud-dataflow-server-${TAG}.jar
JAVA_VERSION=8
pack build --builder gcr.io/paketo-buildpacks/builder:base \
--path "$JAR" \
--trust-builder --verbose \
--env BP_JVM_VERSION=${JAVA_VERSION} "$REPO:$TAG-jdk${JAVA_VERSION}-extra"| Publish the container to a private container registry and register the application docker uri with SCDF. |
B.4. Create containers for architectures not supported yet.
In the case of macOS on M1 the performance of amd64/x86_64 is unacceptable.
We provide a set of scripts that can be used to download specific versions of published artifacts.
We also provide a script that will create a container using the downloaded artifact for the host platform.
In the various projects you will find then in src/local or local folders.
| Project | Scripts | Notes |
|---|---|---|
Data Flow |
|
Download or create container for: |
Skipper |
|
Download or create container for: |
Stream Applications |
|
|
B.4.1. Scripts in spring-cloud-dataflow
src/local/download-apps.sh
Downloads all applications needed by create-containers.sh from Maven repository.
If the timestamp of snapshots matches the download will be skipped.
Usage: download-apps.sh [version]
-
versionis the dataflow-server version like2.11.3. Default is2.11.3-SNAPSHOT
src/local/create-containers.sh
Creates all containers and pushes to local docker registry.
This script requires jib-cli
Usage: create-containers.sh [version] [jre-version]
-
versionis the dataflow-server version like2.11.3. Default is2.11.3-SNAPSHOT -
jre-versionshould be one of 11, 17. Default is 11
B.4.2. Scripts in spring-cloud-skipper
local/download-app.sh
Downloads all applications needed by create-containers.sh from Maven repository.
If the timestamp of snapshots matches the download will be skipped.
Usage: download-app.sh [version]
-
versionis the skipper version like2.11.3or default is2.11.3-SNAPSHOT
local/create-container.sh
Creates all containers and pushes to local docker registry. This script requires jib-cli
Usage: create-containers.sh [version] [jre-version]
-
versionis the skipper version like2.11.3or default is2.11.3-SNAPSHOT -
jre-versionshould be one of 11, 17
B.4.3. Scripts in stream-applications
local/download-apps.sh
Downloads all applications needed by create-containers.sh from Maven repository.
If the timestamp of snapshots matches the download will be skipped.
Usage: download-apps.sh [version] [broker] [filter]
-
versionis the stream applications version like3.2.1or default is3.2.2-SNAPSHOT -
brokeris one of rabbitmq, rabbit or kafka -
filteris a name of an application or a partial name that will be matched.
local/create-containers.sh
Creates all containers and pushes to local docker registry.
This script requires jib-cli
Usage: create-containers.sh [version] [broker] [jre-version] [filter]
-
versionis the stream-applications version like3.2.1or default is3.2.2-SNAPSHOT -
brokeris one of rabbitmq, rabbit or kafka -
jre-versionshould be one of 11, 17 -
filteris a name of an application or a partial name that will be matched.
If the file is not present required to create the container the script will skip the one.
local/pack-containers.sh
Creates all containers and pushes to local docker registry.
This script requires packeto pack
Usage: pack-containers.sh [version] [broker] [jre-version] [filter]
-
versionis the stream-applications version like3.2.1or default is3.2.2-SNAPSHOT -
brokeris one of rabbitmq, rabbit or kafka -
jre-versionshould be one of 11, 17 -
filteris a name of an application or a partial name that will be matched.
If the required file is not present to create the container the script will skip that one.
| If any parameter is provided all those to the left of it should be considered required. |
B.5. Configure Kubernetes for local development or testing
B.5.1. Prerequisites
You will need to install kubectl and then kind or minikube for a local cluster.
All the examples assume you have cloned the spring-cloud-dataflow repository and are executing the scripts from deploy/k8s.
On macOS, you may need to install realpath from Macports or brew install realpath
The scripts require a shell like bash or zsh and should work on Linux, WSL 2 or macOS.
|
B.5.2. Steps
-
Choose Kubernetes provider. Kind, Minikube or remote GKE or TMC.
-
Decide the namespace to use for deployment if not
default. -
Configure Kubernetes and loadbalancer.
-
Choose Broker with
export BROKER=kafka|rabbitmq -
Build or Pull container images for Skipper and Data Flow Server.
-
Deploy and Launch Spring Cloud Data Flow.
-
Export Data Flow Server address to env.
Kubernetes Provider
How do I choose between minikube and kind? kind will generally provide quicker setup and teardown time than Minikube. There is little to choose in terms of performance between the 2 apart from being able to configure limits on CPUs and memory when deploying minikube. So in the case where you have memory constraints or need to enforce memory limitations Minikube will be a better option.
Kubectl
You will need to install kubectl in order to configure the Kubernetes cluster
Kind
Kind is Kubernetes in docker and ideal for local development.
The LoadBalancer will be installed by the configure-k8s.sh script by will require an update to a yaml file to provide the address range available to the LoadBalancer.
Minikube
Minikube uses one of a selection of drivers to provide a virtualization environment.
Delete existing Minikube installation if you have any. minikube delete
|
B.5.3. Building and loading containers.
For local development you need control of the containers used in the local environment.
In order to ensure to manage the specific versions of data flow and skipper containers you can set SKIPPER_VERSION and DATAFLOW_VERSION environmental variable and then invoke ./images/pull-dataflow.sh and ./images/pull-skipper.sh or if you want to use a locally built application you can invoke ./images/build-skipper-image.sh and ./images/build-dataflow.sh
B.5.4. Configure k8s environment
You can invoke one of the following scripts to choose the type of installation you are targeting:
./k8s/use-kind.sh [<namespace>] [<database>] [<broker>]
./k8s/use-mk-docker.sh [<namespace>] [<database>] [<broker>]
./k8s/use-mk-kvm2.sh [<namespace>] [<database>] [<broker>]
./k8s/use-mk.sh <driver> [<namespace>] [<database>] [<broker>] (1)
./k8s/use-tmc.sh <cluster-name> [<namespace>] [<database>] [<broker>]
./k8s/use-gke.sh <cluster-name> [<namespace>] [<database>] [<broker>]| 1 | <driver> must be one of kvm2, docker, vmware, virtualbox, vmwarefusion or hyperkit. docker is the recommended option for local development. |
<namespace> will be default if not provided. The default <database> is postgresql and the default <broker> is kafka.
|
Since these scripts export environmental variable they need to be executes as in the following example:
source ./k8s/use-mk-docker.sh postgresql rabbitmq --namespace test-nsTMC or GKE Cluster in Cloud
The cluster must exist before use, and you should use the relevant cli to login before executing source ./k8s/use-gke.sh
Create Local Cluster.
The following script will create the local cluster.
# Optionally add to control cpu and memory allocation.
export MK_ARGS="--cpus=8 --memory=12g"
./k8s/configure-k8s.sh-
For kind follow instruction to update
./k8s/yaml/metallb-configmap.yamland then apply usingkubectl apply -f ./k8s/yaml/metallb-configmap.yaml -
For minikube launch a new shell and execute
minikube tunnel
Deploy Spring Cloud Data Flow.
The use-* scripts will configure the values of BROKER and DATABASE.
Configure Database
export DATABASE=<database> (1)| 1 | <database> one of mariadb or postgresql |
Docker credentials need to be configured for Kubernetes to pull the various container images.
For Docker Hub you can create a personal free account and use a personal access token as your password.
Test your docker login using ./k8s/docker-login.sh
export DOCKER_SERVER=https://docker.io
export DOCKER_USER=<docker-userid>
export DOCKER_PASSWORD=<docker-password>
export DOCKER_EMAIL=<email-of-docker-use>Set the version of Spring Cloud Data Flow and Skipper.
This example shows the versions of the current development snapshot.
export DATAFLOW_VERSION=2.11.5-SNAPSHOT
export SKIPPER_VERSION=2.11.5-SNAPSHOTBefore you can install SCDF you will need to pull the following images to ensure they are present for uploading to the k8s cluster.
You can configure the before pull-app-images and install-scdf:
-
STREAM_APPS_RT_VERSIONStream Apps Release Train Version. Default is 2022.0.0. -
STREAM_APPS_VERSIONStream Apps Version. Default is 4.0.0.
Use:
./images/pull-app-images.sh
./images/pull-dataflow.sh
./images/pull-skipper.sh
./images/pull-composed-task-runner.sh./k8s/install-scdf.sh
source ./k8s/export-dataflow-ip.sh
You can now execute scripts from ./shell to deploy some simple streams and tasks. You can also run ./shell/shell.sh to run the Spring Cloud Data Flow Shell.
|
If you want to start fresh you use the following to delete the SCDF deployment and then run ./k8s/install-scdf.sh to install it again.
B.5.5. Utilities
The following list of utilities may prove useful.
| Name | Description |
|---|---|
k9s is a text based monitor to explore the Kubernetes cluster. |
|
Extra and tail the logs of various pods based on various naming criteria. |
B.5.6. Scripts
Some of the scripts apply to local containers as well and can be found in src/local, the Kubernetes specific scripts are in deploy/k8s
| Script | Description |
|---|---|
|
Build all images of Restaurant Sample Stream Apps |
|
Pull all images of Restaurant Sample Stream Apps from Docker Hub |
|
Pull dataflow from DockerHub based on |
|
Pull Dataflow Pro from Tanzu Network based on |
|
Pull Skipper from DockerHub base on the |
|
Build a docker image from the local repo of Dataflow |
|
Build a docker image from the local repo of Dataflow Pro. Set |
|
Build a docker image from the local repo of Skipper. |
|
Configure the Kubernetes environment based on your configuration of K8S_DRIVER. |
|
Delete all Kubernetes resources create by the deployment. |
|
Delete cluster, kind or minikube. |
|
Export the url of the data flow server to |
|
Export the url of the http source of a specific flow by name to |
|
Configure and deploy all the containers for Spring Cloud Dataflow |
|
Load all container images required by tests into kind or minikube to ensure you have control over what is used. |
|
Load a specific container image into local kind or minikube. |
|
Execute acceptance tests against cluster where |
|
Register the Task and Stream apps used by the unit tests. |
| Please report any errors with the scripts along with detail information about the relevant environment. |
B.6. Frequently Asked Questions
In this section, we review the frequently asked questions for Spring Cloud Data Flow. See the Frequently Asked Questions section of the microsite for more information.
Appendix C: Identity Providers
This appendix contains information how specific providers can be set up to work with Data Flow security.
At this writing, Azure is the only identity provider.
C.1. Azure
Azure AD (Active Directory) is a fully fledged identity provider that provide a wide range of features around authentication and authorization. As with any other provider, it has its own nuances, meaning care must be taken to set it up.
In this section, we go through how OAuth2 setup is done for AD and Spring Cloud Data Flow.
| You need full organization access rights to set up everything correctly. |
C.1.1. Creating a new AD Environment
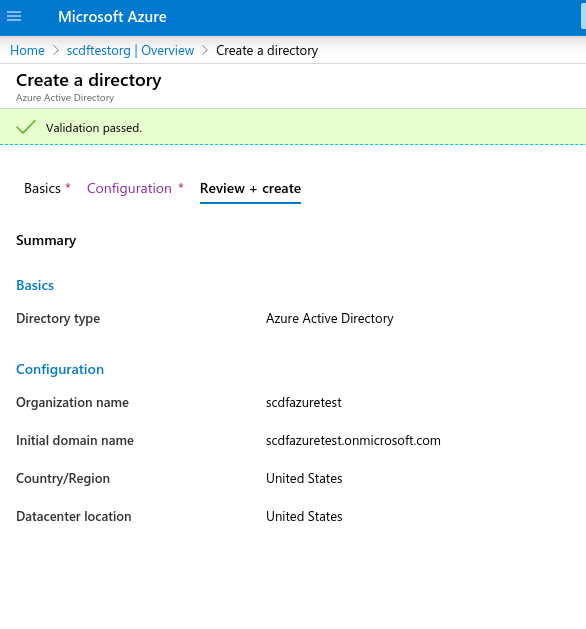
To get started, create a new Active Directory environment. Choose a type as Azure Active Directory (not the b2c type) and then pick your organization name and initial domain. The following image shows the settings:
C.1.2. Creating a New App Registration
App registration is where OAuth clients are created to get used by OAuth applications. At minimum, you need to create two clients, one for the Data Flow and Skipper servers and one for the Data Flow shell, as these two have slightly different configurations. Server applications can be considered to be trusted applications while shell is not trusted (because users can see its full configuration).
NOTE: We recommend using the same OAuth client for both the Data Flow and the Skipper servers. While you can use different clients, it currently would not provide any value, as the configurations needs to be the same.
The following image shows the settings for creating a a new app registration:
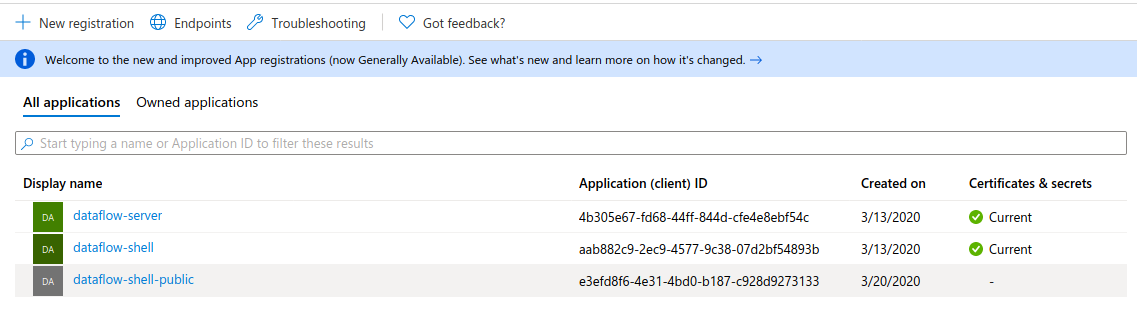
A client secret, when needed, is created under Certificates & secrets in AD.
|
C.1.3. Expose Dataflow APIs
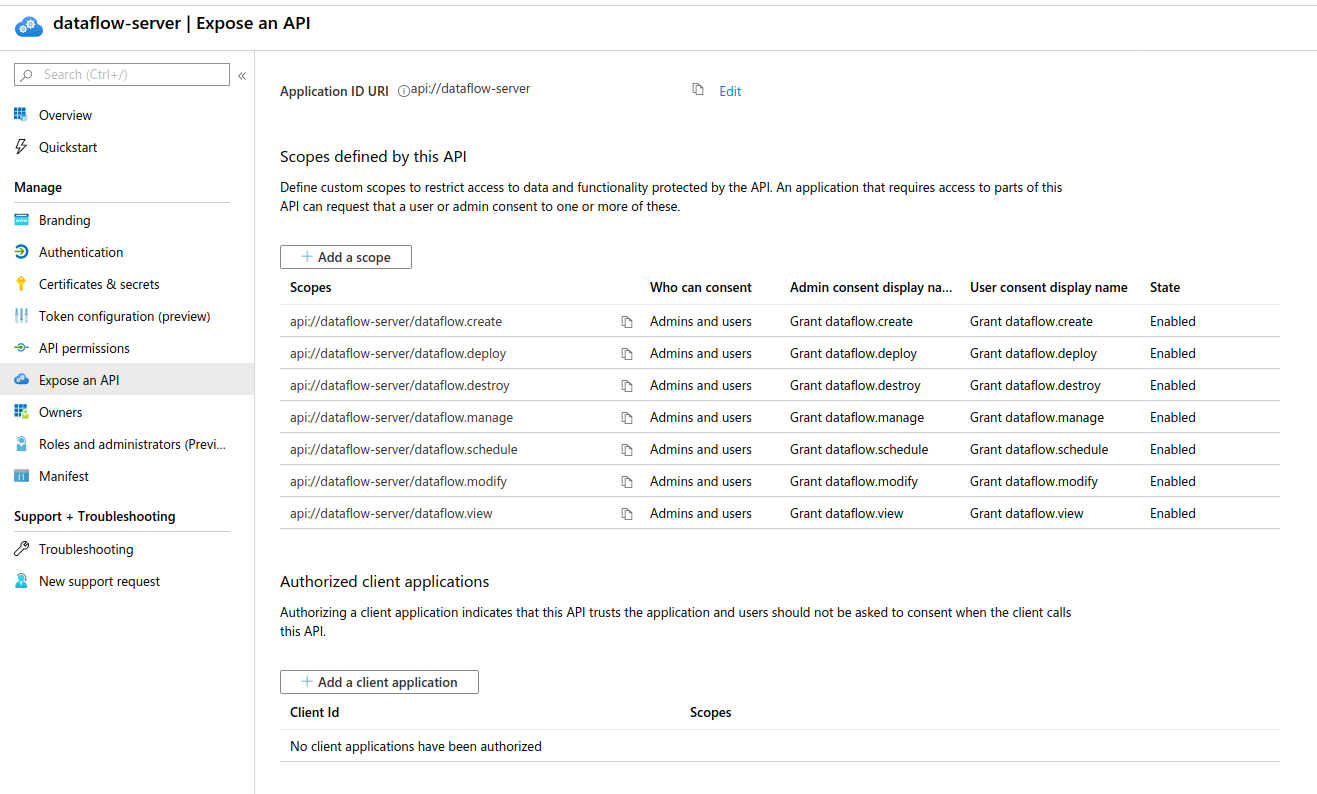
To prepare OAuth scopes, create one for each Data Flow security role. In this example, those would be
-
api://dataflow-server/dataflow.create -
api://dataflow-server/dataflow.deploy -
api://dataflow-server/dataflow.destroy -
api://dataflow-server/dataflow.manage -
api://dataflow-server/dataflow.schedule -
api://dataflow-server/dataflow.modify -
api://dataflow-server/dataflow.view
The following image shows the APIs to expose:
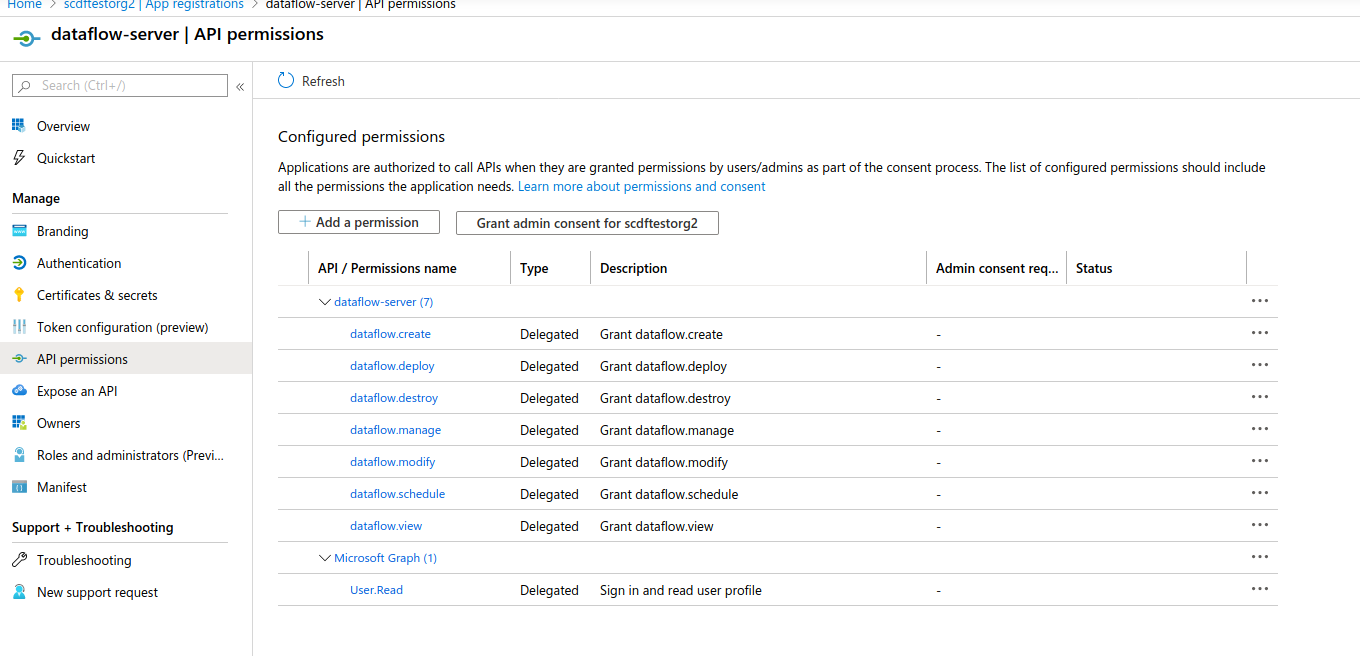
Previously created scopes needs to be added as API Permissions, as the following image shows:
C.1.4. Creating a Privileged Client
For the OAuth client, which is about to use password grants, the same API permissions need to be created for the OAuth client as were used for the server (described in the previous section).
| All these permissions need to be granted with admin privileges. |
The following image shows the privileged settings:
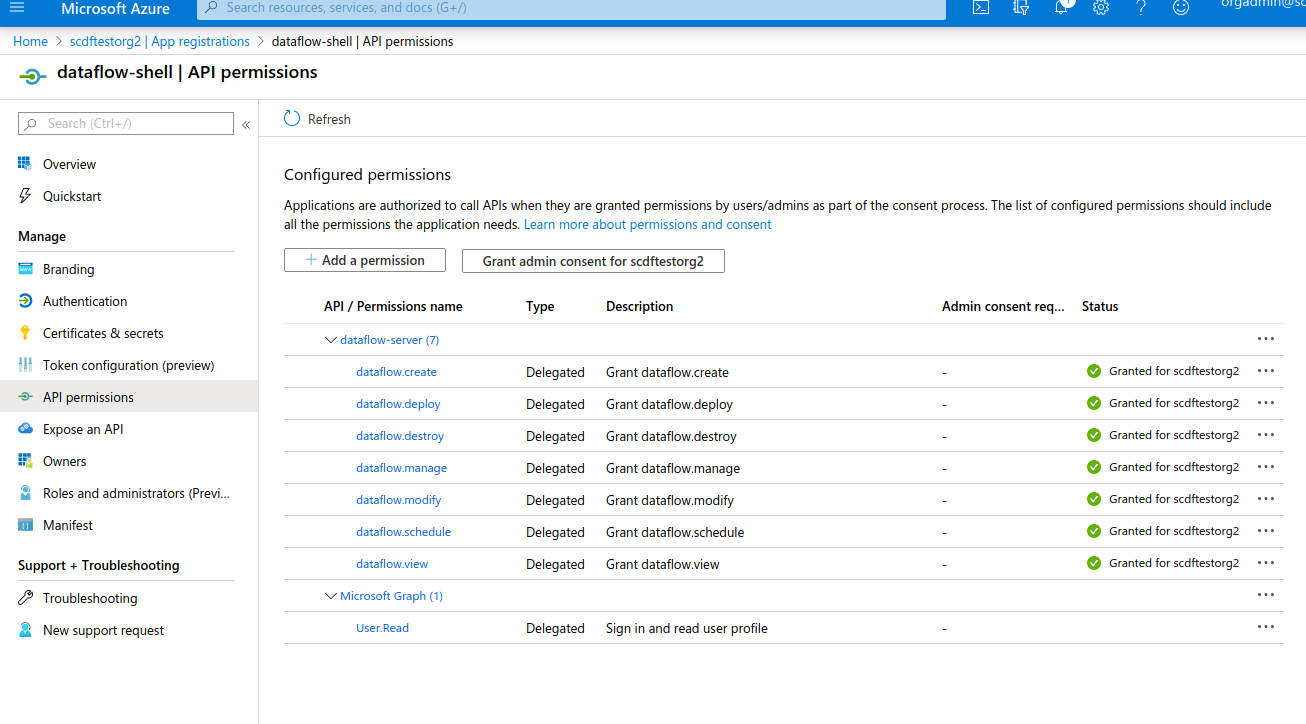
| Privileged client needs a client secret, which needs to be exposed to a client configuration when used in a shell. If you do not want to expose that secret, use the Creating a Public Client public client. |
C.1.5. Creating a Public Client
A public client is basically a client without a client secret and with its type set to public.
The following image shows the configuration of a public client:
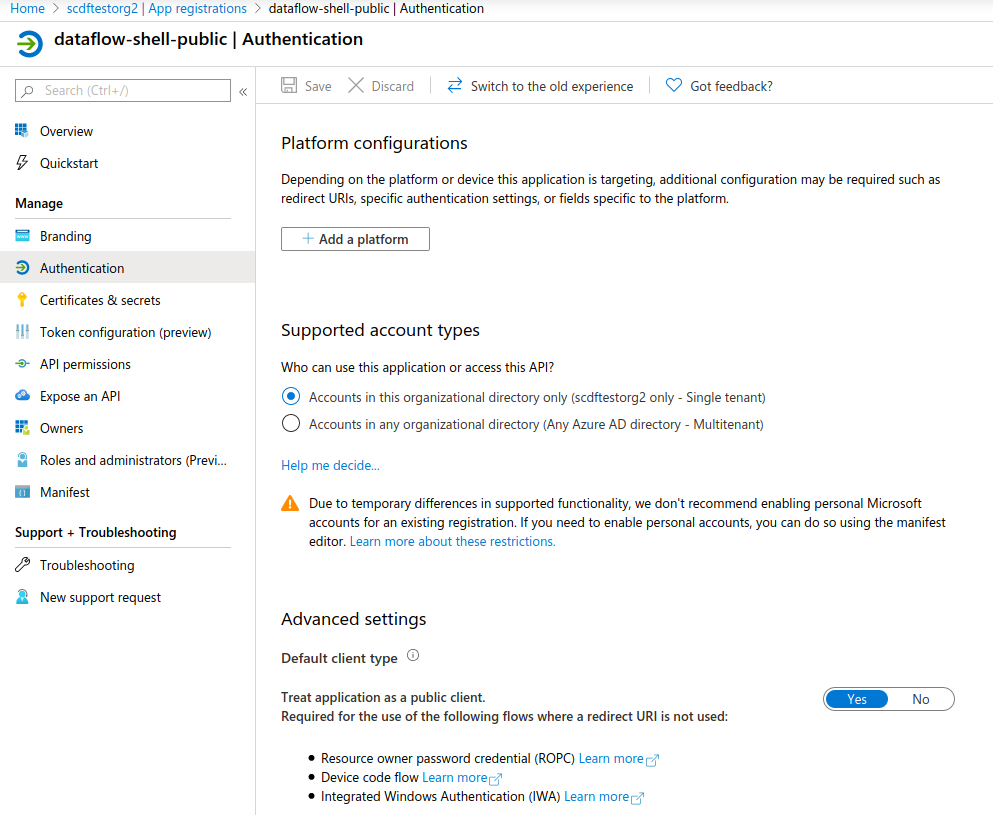
C.1.6. Configuration Examples
This section contains configuration examples for the Data Flow and Skipper servers and the shell.
To starting a Data Flow server:
$ java -jar spring-cloud-dataflow-server.jar \
--spring.config.additional-location=dataflow-azure.ymlspring:
cloud:
dataflow:
security:
authorization:
provider-role-mappings:
dataflow-server:
map-oauth-scopes: true
role-mappings:
ROLE_VIEW: dataflow.view
ROLE_CREATE: dataflow.create
ROLE_MANAGE: dataflow.manage
ROLE_DEPLOY: dataflow.deploy
ROLE_DESTROY: dataflow.destroy
ROLE_MODIFY: dataflow.modify
ROLE_SCHEDULE: dataflow.schedule
security:
oauth2:
client:
registration:
dataflow-server:
provider: azure
redirect-uri: '{baseUrl}/login/oauth2/code/{registrationId}'
client-id: <client id>
client-secret: <client secret>
scope:
- openid
- profile
- email
- offline_access
- api://dataflow-server/dataflow.view
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.create
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0
user-name-attribute: name
resourceserver:
jwt:
jwk-set-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/discovery/v2.0/keysTo start a Skipper server:
$ java -jar spring-cloud-skipper-server.jar \
--spring.config.additional-location=skipper-azure.ymlspring:
cloud:
skipper:
security:
authorization:
provider-role-mappings:
skipper-server:
map-oauth-scopes: true
role-mappings:
ROLE_VIEW: dataflow.view
ROLE_CREATE: dataflow.create
ROLE_MANAGE: dataflow.manage
ROLE_DEPLOY: dataflow.deploy
ROLE_DESTROY: dataflow.destroy
ROLE_MODIFY: dataflow.modify
ROLE_SCHEDULE: dataflow.schedule
security:
oauth2:
client:
registration:
skipper-server:
provider: azure
redirect-uri: '{baseUrl}/login/oauth2/code/{registrationId}'
client-id: <client id>
client-secret: <client secret>
scope:
- openid
- profile
- email
- offline_access
- api://dataflow-server/dataflow.view
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.create
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0
user-name-attribute: name
resourceserver:
jwt:
jwk-set-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/discovery/v2.0/keysTo start a shell and (optionally) pass credentials as options:
$ java -jar spring-cloud-dataflow-shell.jar \
--spring.config.additional-location=dataflow-azure-shell.yml \
--dataflow.username=<USERNAME> \
--dataflow.password=<PASSWORD> security:
oauth2:
client:
registration:
dataflow-shell:
provider: azure
client-id: <client id>
client-secret: <client secret>
authorization-grant-type: password
scope:
- offline_access
- api://dataflow-server/dataflow.create
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.view
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0
A Public Client requires App Roles with the value set the same as the internal permissions [dataflow.create, dataflow.deploy, dataflow.destroy, dataflow.manage, dataflow.modify, dataflow.schedule, dataflow.view] to ensure they are added to the access token.
|
Starting a public shell and (optionally) pass credentials as options:
$ java -jar spring-cloud-dataflow-shell.jar \
--spring.config.additional-location=dataflow-azure-shell-public.yml \
--dataflow.username=<USERNAME> \
--dataflow.password=<PASSWORD>spring:
security:
oauth2:
client:
registration:
dataflow-shell:
provider: azure
client-id: <client id>
authorization-grant-type: password
client-authentication-method: post
scope:
- offline_access
- api://dataflow-server/dataflow.create
- api://dataflow-server/dataflow.deploy
- api://dataflow-server/dataflow.destroy
- api://dataflow-server/dataflow.manage
- api://dataflow-server/dataflow.modify
- api://dataflow-server/dataflow.schedule
- api://dataflow-server/dataflow.view
provider:
azure:
issuer-uri: https://login.microsoftonline.com/799dcfde-b9e3-4dfc-ac25-659b326e0bcd/v2.0