任务
本节将更详细地介绍如何在 Spring Cloud Data Flow 上编排 Spring Cloud Task 应用程序。
如果您刚开始使用 Spring Cloud Data Flow,那么在深入研究本节之前,您可能应该阅读“Local”、“Cloud Foundry”或“Kubernetes”的入门指南。
25. 简介
任务应用程序的生存期很短,这意味着它会故意停止运行,可以按需运行或计划在以后运行。 一个用例可能是抓取网页并写入数据库。
Spring Cloud Task 框架基于 Spring Boot,并增加了 Boot 应用程序记录短期应用程序生命周期事件的能力,例如启动时间、结束时间和退出状态。
这TaskExecution文档显示数据库中存储的信息。
Spring Cloud Task 应用程序中代码执行的入口点通常是 Boot 的CommandLineRunner接口,如本例所示。
Spring Batch 项目可能是 Spring 开发人员编写短期应用程序时想到的。
Spring Batch 提供了比 Spring Cloud Task 更丰富的功能集,建议在处理大量数据时使用。
一个用例可能是读取许多 CSV 文件,转换每行数据,并将每个转换后的行写入数据库。
Spring Batch 提供了自己的数据库架构,其中包含有关 Spring Batch 作业执行的更丰富的信息集。
Spring Cloud Task 与 Spring Batch 集成,因此,如果 Spring Cloud 任务应用程序定义了 Spring BatchJob,则会在 Spring Cloud Task 和 Spring Cloud Batch 执行表之间创建一个链接。
在本地计算机上运行 Data Flow 时,任务将在单独的 JVM 中启动。
在 Cloud Foundry 上运行时,使用 Cloud Foundry 的 Task 功能启动任务。在 Kubernetes 上运行时,任务是使用Pod或Job资源。
26. 任务的生命周期
在深入研究创建 Task 的细节之前,您应该了解 Spring Cloud Data Flow 上下文中任务的典型生命周期:
26.1. 创建 Task 应用程序
Spring Cloud Dataflow 提供了几个开箱即用的任务应用程序(timestamp-task 和 timestamp-batch),但大多数任务应用程序都需要自定义开发。
要创建自定义任务应用程序:
-
使用 Spring Initializer 创建一个新项目,确保选择以下Starters:
-
Cloud Task:此依赖项是spring-cloud-starter-task. -
JDBC:此依赖项是spring-jdbc起动机。 -
选择您的数据库依赖项:输入 Data Flow 当前使用的数据库依赖项。例如:
H2.
-
-
在您的新项目中,创建一个新类作为您的主类,如下所示:
@EnableTask @SpringBootApplication public class MyTask { public static void main(String[] args) { SpringApplication.run(MyTask.class, args); } } -
对于此类,您需要一个或多个
CommandLineRunner或ApplicationRunner实现。您可以实现自己的方法,也可以使用 Spring Boot 提供的方法(例如,有一个用于运行批处理作业)。 -
使用 Spring Boot 将应用程序打包到 über jar 中是通过标准 Spring Boot 约定完成的。 可以按如下所述注册和部署打包的应用程序。
26.1.1. 任务数据库配置
| 启动任务应用程序时,请确保 Spring Cloud Data Flow 正在使用的数据库驱动程序也是任务应用程序的依赖项。 例如,如果您的 Spring Cloud Data Flow 设置为使用 Postgresql,请确保任务应用程序也将 Postgresql 作为依赖项。 |
| 当您在外部(即从命令行)运行任务并希望 Spring Cloud Data Flow 在其 UI 中显示TaskExecutions时,请确保在它们之间共享通用数据源设置。 默认情况下,Spring Cloud Task 使用本地 H2 实例,并且执行记录到 Spring Cloud Data Flow 使用的数据库中。 |
26.2. 注册 Task 应用程序
您可以使用 Spring Cloud Data Flow Shell 将 Task 应用程序注册到 App Registryapp register命令。
您必须提供唯一名称和可解析为应用程序构件的 URI。对于类型,请指定task.
下面的清单显示了三个示例:
dataflow:>app register --name task1 --type task --uri maven://com.example:mytask:1.0.2
dataflow:>app register --name task2 --type task --uri file:///Users/example/mytask-1.0.2.jar
dataflow:>app register --name task3 --type task --uri https://example.com/mytask-1.0.2.jar当提供带有maven方案,则格式应符合以下条件:
maven://<groupId>:<artifactId>[:<extension>[:<classifier>]]:<version>如果要一次注册多个应用程序,可以将它们存储在属性文件中,其中键的格式为<type>.<name>值是 URI。
例如,下面的清单将是一个有效的属性文件:
task.cat=file:///tmp/cat-1.2.1.BUILD-SNAPSHOT.jar
task.hat=file:///tmp/hat-1.2.1.BUILD-SNAPSHOT.jar然后,您可以使用app import命令,并使用--uri选项,如下所示:
app import --uri file:///tmp/task-apps.properties例如,如果要在单个作中注册 Data Flow 附带的所有任务应用程序,可以使用以下命令执行此作:
dataflow:>app import --uri https://dataflow.spring.io/task-maven-latest您还可以将--local选项(即TRUE默认情况下),以指示是否应在 shell 进程本身中解析属性文件位置。
如果应从数据流服务器进程解析位置,请指定--local false.
当使用app register或app import(如果任务应用程序已注册
提供的 name 和 version,默认情况下不会覆盖它。如果要覆盖
预先存在的 Task 应用程序具有不同的uri或uri-metadatalocation,包括--force选择。
| 在某些情况下,资源在服务器端解析。 在其他情况下,URI 将传递到运行时容器实例,并在其中进行解析。 有关更多详细信息,请参阅每个 Data Flow Server 的特定文档。 |
26.3. 创建 Task 定义
您可以通过提供定义名称以及
应用于任务执行的属性。您可以通过以下方式创建任务定义
RESTful API 或 shell。要使用 shell 创建任务定义,请使用task create命令创建任务定义,如以下示例所示:
dataflow:>task create mytask --definition "timestamp --format=\"yyyy\""
Created new task 'mytask'您可以通过 RESTful API 或 shell 获取当前任务定义的列表。
要使用 shell 获取任务定义列表,请使用task list命令。
26.4. 启动任务
临时任务可以通过 RESTful API 或 shell 启动。
要通过 shell 启动临时任务,请使用task launch命令,如以下示例所示:
dataflow:>task launch mytask
Launched task 'mytask'启动任务后,您可以设置在启动任务时需要作为命令行参数传递给任务应用程序的任何属性,如下所示:
dataflow:>task launch mytask --arguments "--server.port=8080 --custom=value"| 参数需要作为空格分隔的值传递。 |
您可以传入用于TaskLauncher本身通过使用--properties选择。
此选项的格式是以逗号分隔的属性字符串,前缀为app.<task definition name>.<property>.
Properties 传递给TaskLauncher作为应用程序属性。
由实现选择如何将这些传递到实际的任务应用程序中。
如果属性前缀为deployer而不是app,它会传递给TaskLauncher作为 Deployment 属性,其含义可能是TaskLauncher特定于实现。
dataflow:>task launch mytask --properties "deployer.timestamp.custom1=value1,app.timestamp.custom2=value2"26.4.1. 应用程序属性
每个应用程序都使用属性来自定义其行为。例如,timestamp任务format设置建立不同于默认值的输出格式。
dataflow:> task create --definition "timestamp --format=\"yyyy\"" --name printTimeStamp这timestampproperty 实际上与timestamp.formattimestamp 应用程序指定的属性。
Data Flow 添加了使用速记形式的功能format而不是timestamp.format.
您还可以指定普通版本,如以下示例所示:
dataflow:> task create --definition "timestamp --timestamp.format=\"yyyy\"" --name printTimeStamp这种速记行为将在 Stream Application Properties 一节中详细讨论。
如果已注册应用程序属性元数据,则可以在键入后在 shell 中使用 Tab 键自动补全来获取候选属性名称的列表。--
shell 为应用程序属性提供 Tab 键自动补全。这app info --name <appName> --type <appType>shell 命令提供了所有受支持属性的其他文档。支持的任务<appType>是task.
在 Kubernetes 上重新启动 Spring Batch 作业时,必须使用shell或boot. |
26.4.2. 通用应用程序属性
除了通过 DSL 进行配置之外,Spring Cloud Data Flow 还提供了一种机制,用于设置其启动的所有任务应用程序通用的属性。
您可以通过添加前缀为spring.cloud.dataflow.applicationProperties.task启动服务器时。
然后,服务器将所有属性(不带前缀)传递给它启动的实例。
例如,您可以将所有启动的应用程序配置为使用prop1和prop2属性,方法是使用以下选项启动 Data Flow 服务器:
--spring.cloud.dataflow.applicationProperties.task.prop1=value1
--spring.cloud.dataflow.applicationProperties.task.prop2=value2这会导致prop1=value1和prop2=value2属性传递给所有启动的应用程序。
使用此机制配置的属性的优先级低于任务部署属性。
如果在任务启动时指定了具有相同键的属性(例如,app.trigger.prop2覆盖 common 属性)。 |
26.4.3. 使用特定应用程序版本启动任务
启动任务时,您可以指定应用程序的特定版本。
如果未指定版本,Spring Cloud Data Flow 将使用应用程序的默认版本。
要指定要在启动时使用的应用程序版本,请使用 deployer 属性version.<app-name>.
例如:
task launch my-task --properties 'version.timestamp=3.0.0'同样,在安排任务时,您将使用相同的version.<app-name>.例如:
task schedule create --name my-schedule --definitionName my-task --expression '*/1 * * * *' --properties 'version.timestamp=3.0.0'26.5. 限制并发任务启动次数
Spring Cloud Data Flow 允许用户限制每个已配置平台的最大并发运行任务数,以防止 IaaS 或硬件资源饱和。
默认情况下,限制设置为20适用于所有支持的平台。如果平台实例上并发运行的任务数大于或等于限制,则下一个任务启动请求将失败,并通过 RESTful API、Shell 或 UI 返回错误消息。
您可以通过设置相应的 deployer 属性spring.cloud.dataflow.task.platform.<platform-type>.accounts[<account-name>].maximumConcurrentTasks哪里<account-name>是已配置的平台账户的名称 (default如果未明确配置帐户)。
这<platform-type>引用当前支持的 Deployer 之一:local或kubernetes.为cloudfoundry,则该属性为spring.cloud.dataflow.task.platform.<platform-type>.accounts[<account-name>].deployment.maximumConcurrentTasks.(区别在于deployment已添加到路径中)。
这TaskLauncherimplementation 通过查询底层平台的运行时状态(如果可能)来确定当前正在运行的任务的数量。用于识别task因平台而异。
例如,在本地主机上启动任务会使用LocalTaskLauncher.LocalTaskLauncher为每个启动请求运行一个进程,并在内存中跟踪这些进程。在这种情况下,我们不会查询底层作系统,因为以这种方式识别任务是不切实际的。
对于 Cloud Foundry,任务是其部署模型支持的核心概念。所有任务的状态)可直接通过 API 获得。
这意味着账户的组织和空间中的每个正在运行的任务容器都包含在正在运行的执行计数中,无论它是通过使用 Spring Cloud Data Flow 还是通过调用CloudFoundryTaskLauncher径直。
对于 Kubernetes,通过KubernetesTaskLauncher,如果成功,则会导致 Pod 运行,我们预计该 Pod 最终会完成或失败。
在这种环境中,通常没有简单的方法来识别与任务对应的 Pod。
因此,我们只计算由KubernetesTaskLauncher.
由于任务Starters提供了task-name标签,我们会根据是否存在此标签来筛选所有正在运行的 Pod。
26.6. 查看任务执行
启动任务后,任务的状态将存储在关系数据库中。状态 包括:
-
任务名称
-
开始时间
-
结束时间
-
退出代码
-
退出消息
-
上次更新时间
-
参数
您可以通过 RESTful API 或 shell 检查任务执行的状态。
要通过 shell 显示最新的任务执行,请使用task execution list命令。
要仅获取一个任务定义的任务执行列表,请添加--name和
任务定义名称 — 例如task execution list --name foo.检索完整
details 中,请使用task execution statuscommand 替换为任务执行的 ID,
例如task execution status --id 549.
26.7. 销毁任务定义
销毁任务定义会从定义存储库中删除该定义。
这可以通过 RESTful API 或 shell 来完成。
要通过 shell 销毁任务,请使用task destroy命令,如以下示例所示:
dataflow:>task destroy mytask
Destroyed task 'mytask'这task destroy命令还有一个选项cleanup被销毁的任务的任务执行,如以下示例所示:
dataflow:>task destroy mytask --cleanup
Destroyed task 'mytask'默认情况下,cleanupoption 设置为false(也就是说,默认情况下,销毁任务时不会清理任务执行)。
要通过 shell 销毁所有任务,请使用task all destroy命令,如以下示例所示:
dataflow:>task all destroy
Really destroy all tasks? [y, n]: y
All tasks destroyed如果需要,您可以使用 force 开关:
dataflow:>task all destroy --force
All tasks destroyed之前为定义启动的任务的任务执行信息将保留在任务存储库中。
| 这不会停止此定义的任何当前正在运行的任务。相反,它会从数据库中删除任务定义。 |
|
+
.使用 |
26.8. 验证任务
有时,任务定义中包含的应用程序在其注册中具有无效的 URI。
这可能是由于在应用程序注册时输入了无效的 URI,或者从要从中提取应用程序的存储库中删除了应用程序。
要验证任务中包含的所有应用程序都是可解析的,请使用validate命令,如下所示:
dataflow:>task validate time-stamp
╔══════════╤═══════════════╗
║Task Name │Task Definition║
╠══════════╪═══════════════╣
║time-stamp│timestamp ║
╚══════════╧═══════════════╝
time-stamp is a valid task.
╔═══════════════╤═════════════════╗
║ App Name │Validation Status║
╠═══════════════╪═════════════════╣
║task:timestamp │valid ║
╚═══════════════╧═════════════════╝在前面的示例中,用户验证了他们的时间戳任务。这task:timestamp申请有效。
现在,我们可以看到,如果 Stream 定义包含具有无效 URI 的已注册应用程序,会发生什么情况:
dataflow:>task validate bad-timestamp
╔═════════════╤═══════════════╗
║ Task Name │Task Definition║
╠═════════════╪═══════════════╣
║bad-timestamp│badtimestamp ║
╚═════════════╧═══════════════╝
bad-timestamp is an invalid task.
╔══════════════════╤═════════════════╗
║ App Name │Validation Status║
╠══════════════════╪═════════════════╣
║task:badtimestamp │invalid ║
╚══════════════════╧═════════════════╝在这种情况下,Spring Cloud Data Flow 声明该任务无效,因为task:badtimestamp具有无效的 URI。
26.9. 停止任务执行
在某些情况下,由于平台或应用程序业务逻辑本身的问题,在平台上运行的任务可能不会停止。
对于此类情况, Spring Cloud Data Flow 提供了向平台发送请求以结束任务的功能。
为此,请提交一个task execution stop对于一组给定的任务执行,如下所示:
task execution stop --ids 5
Request to stop the task execution with id(s): 5 has been submitted使用上述命令,用于停止执行id=5提交到底层 Deployer 实现。因此,该作将停止该任务。当我们查看任务执行的结果时,我们看到任务执行已完成,退出代码为 0:
dataflow:>task execution list
╔══════════╤══╤════════════════════════════╤════════════════════════════╤═════════╗
║Task Name │ID│ Start Time │ End Time │Exit Code║
╠══════════╪══╪════════════════════════════╪════════════════════════════╪═════════╣
║batch-demo│5 │Mon Jul 15 13:58:41 EDT 2019│Mon Jul 15 13:58:55 EDT 2019│0 ║
║timestamp │1 │Mon Jul 15 09:26:41 EDT 2019│Mon Jul 15 09:26:41 EDT 2019│0 ║
╚══════════╧══╧════════════════════════════╧════════════════════════════╧═════════╝如果您为具有与其关联的子任务执行的任务执行(如组合任务)提交停止,则会为每个子任务执行发送一个停止请求。
当停止具有正在运行的 Spring Batch 作业的任务执行时,该作业的批处理状态为STARTED.
请求停止时,每个受支持的平台都会向任务应用程序发送一个 SIG-INT。这允许 Spring Cloud Task 捕获应用程序的状态。但是, Spring Batch 不处理 SIG-INT,因此,作业会停止,但仍处于 STARTED 状态。 |
| 在启动远程分区 Spring Batch 任务应用程序时, Spring Cloud Data Flow 支持直接停止 Cloud Foundry 和 Kubernetes 平台的工作程序分区任务。本地平台不支持停止 worker partition 任务。 |
26.9.1. 停止在 Spring Cloud Data Flow 之外启动的任务执行
您可能希望停止已在 Spring Cloud Data Flow 之外启动的任务。这方面的一个例子是由远程批量分区应用程序启动的工作程序应用程序。
在这种情况下,远程批量分区应用程序将external-execution-id对于每个 worker 应用程序。但是,不会存储任何平台信息。
因此,当 Spring Cloud Data Flow 必须停止远程批量分区应用程序及其工作程序应用程序时,您需要指定平台名称,如下所示:
dataflow:>task execution stop --ids 1 --platform myplatform
Request to stop the task execution with id(s): 1 for platform myplatform has been submitted27. 订阅 Task 和 Batch 事件
您还可以在启动任务时利用各种任务和批处理事件。
如果启用了任务以生成任务或批处理事件(具有spring-cloud-task-stream并且,在 Kafka 作为 Binder 的情况下,spring-cloud-stream-binder-kafka),这些事件将在任务生命周期内发布。
默认情况下,代理上那些已发布事件的目标名称(Rabbit、Kafka 等)是事件名称本身(例如:task-events,job-execution-events等)。
dataflow:>task create myTask --definition "myBatchJob"
dataflow:>stream create task-event-subscriber1 --definition ":task-events > log" --deploy
dataflow:>task launch myTask您可以通过在启动任务时指定显式名称来控制这些事件的目标名称,如下所示:
dataflow:>stream create task-event-subscriber2 --definition ":myTaskEvents > log" --deploy
dataflow:>task launch myTask --properties "app.myBatchJob.spring.cloud.stream.bindings.task-events.destination=myTaskEvents"下表列出了 Broker 上的默认任务和批处理事件以及目标名称:
事件 |
目的地 |
任务事件 |
|
任务执行事件 |
|
步骤执行事件 |
|
Item Read 事件 |
|
Item Process 事件 |
|
Item Write 事件 |
|
跳过事件 |
|
28. 组合任务
Spring Cloud Data Flow 允许您创建有向图,其中图的每个节点都是一个任务应用程序。 这是通过使用 DSL 来完成组合任务的。 您可以通过 RESTful API、Spring Cloud Data Flow Shell 或 Spring Cloud Data Flow UI 创建组合任务。
28.1. 组合任务运行程序
组合任务通过称为 Composed Task Runner 的任务应用程序运行。Spring Cloud Data Flow 服务器在启动组合任务时自动部署组合任务运行程序。
28.1.1. 配置组合任务运行程序
组合任务运行程序应用程序具有dataflow-server-uri用于验证和启动子任务的属性。
默认为localhost:9393.如果运行分布式 Spring Cloud Data Flow 服务器,就像在 Cloud Foundry 或 Kubernetes 上部署服务器一样,则需要提供可用于访问服务器的 URI。
您可以通过设置dataflow-server-uri属性,或者通过设置spring.cloud.dataflow.server.uriSpring Cloud Data Flow 服务器启动时的属性。
对于后一种情况,dataflow-server-uri组合任务运行程序应用程序属性在启动组合任务时自动设置。
配置选项
这ComposedTaskRunnertask 具有以下选项:
-
composed-task-arguments用于每个任务的命令行参数。(字符串,默认值:<none>)。 -
increment-instance-enabled允许单个ComposedTaskRunner实例重新运行,无需更改参数,通过添加递增的 number 作业参数run.id从上一个执行开始。(布尔值,默认值:true). ComposedTaskRunner 是使用 Spring Batch 构建的。因此,成功执行后,批处理作业被视为已完成。 要启动相同的ComposedTaskRunnerdefinition 时,您必须设置increment-instance-enabled或uuid-instance-enabledproperty 设置为true或更改每次启动的定义参数。 使用此选项时,必须将其应用于所需应用程序的所有任务启动,包括首次启动。 -
uuid-instance-enabled允许单个ComposedTaskRunner实例,无需更改参数,只需在ctr.idjob 参数。(布尔值,默认值:false). ComposedTaskRunner 是使用 Spring Batch 构建的。因此,成功执行后,批处理作业被视为已完成。 要启动相同的ComposedTaskRunnerdefinition 时,您必须设置increment-instance-enabled或uuid-instance-enabledproperty 设置为true或更改每次启动的定义参数。 使用此选项时,必须将其应用于所需应用程序的所有任务启动,包括首次启动。此选项设置为 true 时将覆盖increment-instance-id. 将此选项设置为true同时运行同一组合任务定义的多个实例时。 -
interval-time-between-checks该ComposedTaskRunner在数据库检查之间等待,以查看任务是否已完成。(Integer,默认值:10000).ComposedTaskRunner使用 DataStore 来确定每个子任务的状态。此区间指示ComposedTaskRunner它应该多久检查一次其子任务的状态。 -
transaction-isolation-level建立组合任务运行程序的事务隔离级别。 可以在此处找到可用事务隔离级别的列表。 默认值为ISOLATION_REPEATABLE_READ. -
max-start-wait-time组合任务运行程序将等待start_time的 A 步taskExecution在 Composed 任务执行失败之前设置(Integer,默认值:0)。 确定允许每个子任务启动应用程序的最长时间。默认的0表示无超时。 -
max-wait-time在执行组合任务失败之前,单个步骤可以运行的最长时间(以毫秒为单位)(整数,默认值:0)。 确定在 CTR 以失败结束之前允许每个子任务运行的最长时间。默认的0表示无超时。 -
split-thread-allow-core-thread-timeout指定是否允许拆分核心线程超时。(布尔值,默认值:false) 设置策略,该策略控制在保持活动时间内没有任务到达时,核心线程是否可以超时和终止,并在新任务到达时根据需要进行替换。 -
split-thread-core-pool-sizeSplit 的核心池大小。(Integer,默认值:1) 拆分中包含的每个子任务都需要一个线程才能执行。因此,例如,诸如<AAA || BBB || CCC> && <DDD || EEE>将需要一个split-thread-core-pool-size之3. 这是因为最大的拆分包含三个子任务。计数2的意思是AAA和BBB将并行运行,但 CCC 将等待,直到AAA或BBBfinish 才能运行。 然后DDD和EEE将并行运行。 -
split-thread-keep-alive-secondsSplit 的线程保持活动秒。(Integer,默认值:60) 如果池当前具有超过corePoolSizethreads,如果多余的线程空闲时间超过keepAliveTime. -
split-thread-max-pool-sizeSplit 的最大池大小。(Integer,默认值:Integer.MAX_VALUE). 确定线程池允许的最大线程数。 -
拆分线程队列容量斯普利特的容量
BlockingQueue.(Integer,默认值:Integer.MAX_VALUE)-
如果少于
corePoolSize线程正在运行,则Executor总是喜欢添加新线程而不是排队。 -
如果
corePoolSize或更多线程正在运行,则Executor总是喜欢对请求进行排队,而不是添加新线程。 -
如果请求无法排队,则会创建一个新线程,除非此线程会超过
maximumPoolSize.在这种情况下,任务将被拒绝。
-
-
split-thread-wait-for-tasks-to-complete-on-shutdown是否等待计划任务在关闭时完成,而不是中断正在运行的任务并运行队列中的所有任务。(布尔值,默认值:false) -
dataflow-server-uri接收任务启动请求的数据流服务器的 URI。(字符串,默认值:localhost:9393) -
dataflow-server-username接收任务启动请求的数据流服务器的可选用户名。 用于使用基本身份验证访问数据流服务器。在以下情况下不使用dataflow-server-access-token已设置。 -
dataflow-server-password接收任务启动请求的数据流服务器的可选密码。 用于使用基本身份验证访问数据流服务器。在以下情况下不使用dataflow-server-access-token已设置。 -
dataflow-server-access-token此属性设置可选的 OAuth2 访问令牌。 通常,该值是使用当前登录用户的令牌(如果可用)自动设置的。 但是,对于特殊用例,也可以显式设置此值。
一个特殊的布尔属性dataflow-server-use-user-access-token,当您想要使用当前登录用户的访问令牌并将其传播到组合任务运行程序时,存在。此属性用于
由 Spring Cloud Data Flow 创建,如果设置为true,则会自动填充dataflow-server-access-token财产。使用dataflow-server-use-user-access-token,则必须为每个任务执行传递它。
在某些情况下,用户的dataflow-server-access-token默认情况下,必须为每个组合任务启动传递。
在这种情况下,请设置 Spring Cloud Data Flowspring.cloud.dataflow.task.useUserAccessTokenproperty 设置为true.
要为 Composed Task Runner 设置属性,您需要在属性前加上app.composed-task-runner..
例如,要将dataflow-server-uriproperty 的app.composed-task-runner.dataflow-server-uri.
28.2. 组合任务的生命周期
组合任务的生命周期分为三个部分:
28.2.1. 创建组合任务
通过 task create 命令创建任务定义时,将使用组合任务的 DSL,如以下示例所示:
dataflow:> app register --name timestamp --type task --uri maven://org.springframework.cloud.task.app:timestamp-task:
dataflow:> app register --name mytaskapp --type task --uri file:///home/tasks/mytask.jar
dataflow:> task create my-composed-task --definition "mytaskapp && timestamp"
dataflow:> task launch my-composed-task 在前面的示例中,我们假设我们组合的任务要使用的应用程序尚未注册。
因此,在前两个步骤中,我们注册了两个任务应用程序。
然后,我们使用task create命令。
前面示例中的组合任务 DSL 在启动时运行mytaskapp然后运行时间戳应用程序。
但在我们启动my-composed-task定义,我们可以查看 Spring Cloud Data Flow 为我们生成了什么。
这可以通过使用 task list 命令来完成,如以下示例中所示(包括其输出):
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│unknown ║
║my-composed-task-mytaskapp│mytaskapp │unknown ║
║my-composed-task-timestamp│timestamp │unknown ║
╚══════════════════════════╧══════════════════════╧═══════════╝在该示例中,Spring Cloud Data Flow 创建了三个任务定义,每个定义对应于构成我们组合任务 (my-composed-task-mytaskapp和my-composed-task-timestamp) 以及组合的任务 (my-composed-task) 定义。
我们还看到,为子任务生成的每个名称都由组合任务的名称和应用程序的名称组成,由连字符分隔(如 my-composed-task mytaskapp)。--
28.2.2. 启动组合任务
启动组合任务的方式与启动独立任务的方式相同,如下所示:
task launch my-composed-task启动任务后,假设所有任务都成功完成,您可以在运行task execution list,如以下示例所示:
dataflow:>task execution list
╔══════════════════════════╤═══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID │ Start Time │ End Time │Exit Code║
╠══════════════════════════╪═══╪════════════════════════════╪════════════════════════════╪═════════╣
║my-composed-task-timestamp│713│Wed Apr 12 16:43:07 EDT 2017│Wed Apr 12 16:43:07 EDT 2017│0 ║
║my-composed-task-mytaskapp│712│Wed Apr 12 16:42:57 EDT 2017│Wed Apr 12 16:42:57 EDT 2017│0 ║
║my-composed-task │711│Wed Apr 12 16:42:55 EDT 2017│Wed Apr 12 16:43:15 EDT 2017│0 ║
╚══════════════════════════╧═══╧════════════════════════════╧════════════════════════════╧═════════╝在前面的示例中,我们看到my-compose-task启动,其他任务也按顺序启动。
他们每个人都成功地运行了Exit Code如0.
将属性传递给子任务
要在任务启动时设置组合任务图中子任务的属性,
使用以下格式:app.<child task app name>.<property>.
以下清单显示了一个组合任务定义作为示例:
dataflow:> task create my-composed-task --definition "mytaskapp && mytimestamp"要有mytaskapp显示 'HELLO' 并设置mytimestamptimestamp 格式设置为YYYY对于组合任务定义,请使用以下任务启动格式:
task launch my-composed-task --properties "app.mytaskapp.displayMessage=HELLO,app.mytimestamp.timestamp.format=YYYY"与应用程序属性类似,您还可以设置deployer使用以下格式为子任务设置属性:deployer.<child task app name>.<deployer-property>:
task launch my-composed-task --properties "deployer.mytaskapp.memory=2048m,app.mytimestamp.timestamp.format=HH:mm:ss"
Launched task 'a1'将参数传递给组合任务运行程序
您可以使用--arguments选择:
dataflow:>task create my-composed-task --definition "<aaa: timestamp || bbb: timestamp>"
Created new task 'my-composed-task'
dataflow:>task launch my-composed-task --arguments "--increment-instance-enabled=true --max-wait-time=50000 --split-thread-core-pool-size=4" --properties "app.bbb.timestamp.format=dd/MM/yyyy HH:mm:ss"
Launched task 'my-composed-task'28.2.3. 销毁组合任务
用于销毁独立任务的命令与用于销毁组合任务的命令相同。
唯一的区别是,销毁组合任务也会销毁与其关联的子任务。
以下示例显示了使用destroy命令:
dataflow:>task list
╔══════════════════════════╤══════════════════════╤═══════════╗
║ Task Name │ Task Definition │Task Status║
╠══════════════════════════╪══════════════════════╪═══════════╣
║my-composed-task │mytaskapp && timestamp│COMPLETED ║
║my-composed-task-mytaskapp│mytaskapp │COMPLETED ║
║my-composed-task-timestamp│timestamp │COMPLETED ║
╚══════════════════════════╧══════════════════════╧═══════════╝
...
dataflow:>task destroy my-composed-task
dataflow:>task list
╔═════════╤═══════════════╤═══════════╗
║Task Name│Task Definition│Task Status║
╚═════════╧═══════════════╧═══════════╝28.2.4. 停止组合任务
如果需要停止组合任务执行,您可以通过以下方式执行此作:
-
RESTful API
-
Spring Cloud 数据流仪表板
要通过控制面板停止组合任务,请选择 Jobs 选项卡,然后单击要停止的任务执行旁边的 *Stop() 按钮。
当当前正在运行的子任务完成时,组合任务运行将停止。
与在组合任务停止时正在运行的子任务关联的步骤将标记为STOPPED以及组合任务作业执行。
28.2.5. 重启组合任务
组合任务在执行过程中失败,且组合任务的状态为FAILED,则可以重新启动该任务。
您可以通过以下方式执行此作:
-
RESTful API
-
shell
-
Spring Cloud 数据流仪表板
要通过 shell 重新启动组合任务,请使用相同的参数启动任务。 要通过控制面板重新启动组合任务,请选择 Jobs 选项卡,然后单击要重新启动的任务执行旁边的 Restart 按钮。
重新启动已停止的组合任务作业(通过 Spring Cloud Data Flow Dashboard 或 RESTful API)会重新启动STOPPED子任务,然后按指定顺序启动其余 (未启动的) 子任务。 |
29. 组合任务 DSL
组合任务可以通过三种方式运行:
29.1. 条件执行
条件执行使用双 & 符号 () 表示。
这允许序列中的每个任务仅在前一个任务
成功完成,如以下示例所示:&&
task create my-composed-task --definition "task1 && task2"当组合任务调用my-composed-task启动后,它会启动名为task1并且,如果task1成功完成,则名为task2启动。
如果task1失败task2未启动。
您还可以使用 Spring Cloud Data Flow Dashboard 创建条件执行,方法是使用设计器拖放所需的应用程序并将它们连接在一起以创建有向图,如下图所示:
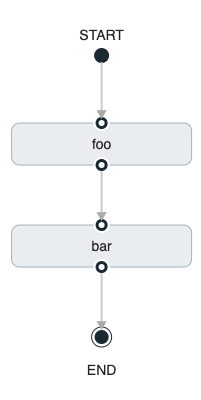
上图是使用 Spring Cloud Data Flow Dashboard 创建的定向图的屏幕截图。 您可以看到,图中的四个组件组成了一个条件执行:
-
Start icon:所有有向图形都从此元件开始。只有一个。
-
任务图标:表示有向图中的每个任务。
-
End icon(结束图标):表示有向图的结束。
-
实线箭头:表示以下之间的流程条件执行流程:
-
两个应用程序。
-
启动控制节点和应用程序。
-
应用程序和末端控制节点。
-
-
End icon(结束图标):所有有向图形都在此符号处结束。
| 您可以通过单击 Definitions (定义) 选项卡上组合任务定义旁边的 Detail (详细信息) 按钮来查看定向图的图表。 |
29.2. 过渡执行
DSL 支持对在执行有向图期间进行的转换进行精细控制。
通过提供基于上一个任务的退出状态的相等条件来指定过渡。
任务转换由以下符号表示 。->
29.2.1. 基本过渡
基本过渡如下所示:
task create my-transition-composed-task --definition "foo 'FAILED' -> bar 'COMPLETED' -> baz"在前面的示例中,foo将启动,并且,如果其退出状态为FAILED这bar任务将启动。
如果foo是COMPLETED,baz将启动。
返回的所有其他状态cat没有效果,任务会正常结束。
使用 Spring Cloud Data Flow Dashboard 创建相同的“基本过渡”,如下图所示:
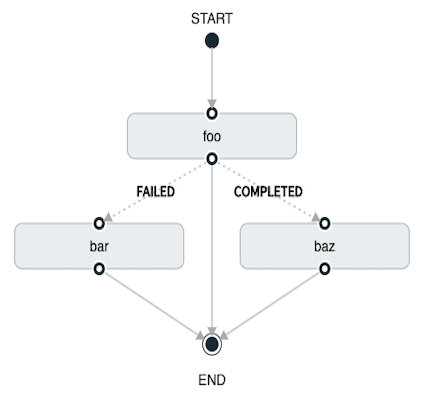
上图是在 Spring Cloud Data Flow Dashboard 中创建的有向图的屏幕截图。 请注意,有两种不同类型的连接器:
-
虚线:表示从应用程序到可能的目标应用程序之一的转换。
-
实线:以条件执行或应用程序与控制节点之间的连接(开始或结束)连接应用程序。
要创建过渡连接器:
-
创建过渡时,使用连接器将应用程序链接到每个可能的目标。
-
完成后,转到每个连接并通过单击选择它。
-
此时将显示一个 bolt 图标。
-
单击该图标。
-
输入该连接器所需的退出状态。
-
该连接器的实线将变为虚线。
29.2.2. 使用通配符过渡
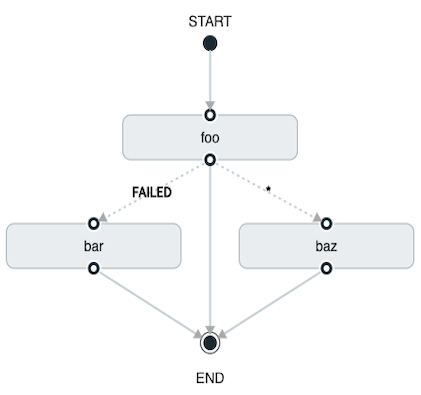
DSL 支持通配符进行转换,如以下示例所示:
task create my-transition-composed-task --definition "foo 'FAILED' -> bar '*' -> baz"在前面的示例中,foo将启动,并且,如果其退出状态为FAILED,bar任务将启动。
对于任何cat以外FAILED,baz将启动。
使用 Spring Cloud Data Flow Dashboard 创建相同的“带通配符的过渡”将类似于下图:
29.2.3. 使用以下条件执行进行过渡
转换后可以执行条件执行,只要通配符 ,如以下示例所示:
task create my-transition-conditional-execution-task --definition "foo 'FAILED' -> bar 'UNKNOWN' -> baz && qux && quux"在前面的示例中,foo将启动,并且,如果其退出状态为FAILED这bar任务将启动。
如果foo的退出状态为UNKNOWN,baz将启动。
对于任何foo以外FAILED或UNKNOWN,qux将启动,成功完成后,quux将启动。
使用 Spring Cloud Data Flow Dashboard 创建相同的“带条件执行的过渡”将类似于下图:
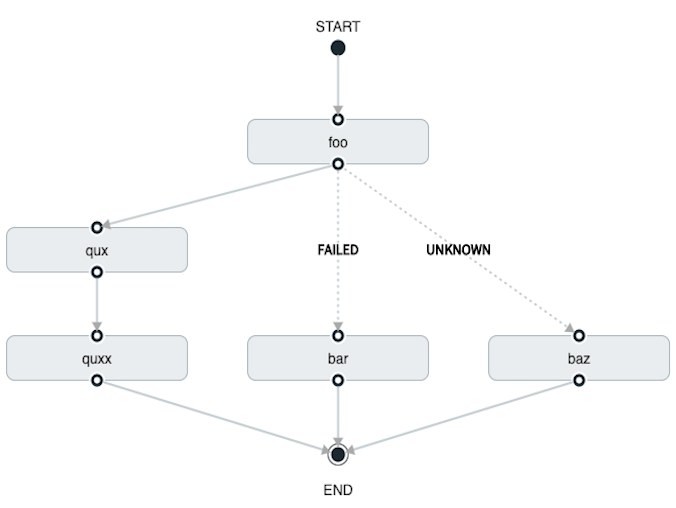
在此图中,虚线(过渡)连接fooapplication 连接到目标应用程序,但一条实线连接foo,qux和quux. |
29.2.4. 忽略退出消息
如果拆分中的任何子任务返回ExitMessage以外COMPLETED分裂
将具有ExitStatus之FAILED.要忽略ExitMessage子任务中,
添加ignoreExitMessage=true对于每个将返回ExitMessage在 split 中。使用此标志时,ExitStatus的任务将为COMPLETED如果ExitCode的子任务为零。拆分将具有ExitStatus之FAILED如果ExitCode`s is non zero. There are 2 ways to
set the `ignoreExitMessage旗:
-
为每个需要具有 exitMessage 的应用程序设置属性 ignored 的 Split 中。例如,像
<AAA || BBB>哪里BBB将返回一个exitMessage,则可以将ignoreExitMessage属性(如app.BBB.ignoreExitMessage=true -
您还可以使用 composed-task-arguments 属性为所有应用程序设置它。 例如:
--composed-task-arguments=--ignoreExitMessage=true.
29.3. 拆分执行
拆分允许组合任务中的多个任务并行运行。
它通过使用尖括号 () 对要并行运行的任务和流进行分组来表示。
这些任务和流由双管道分隔<>||symbol 中,如以下示例所示:
task create my-split-task --definition "<foo || bar || baz>"前面的示例启动任务foo,bar和baz并行。
使用 Spring Cloud Data Flow Dashboard 创建相同的“拆分执行”将类似于下图:
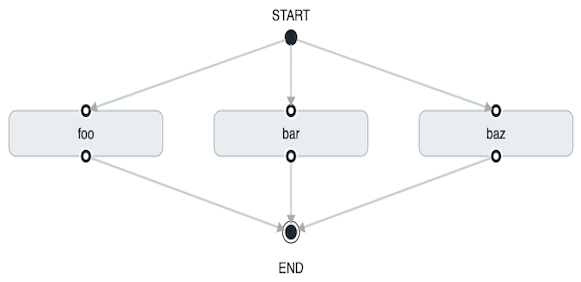
使用任务 DSL,您还可以连续运行多个拆分组,如以下示例所示:
task create my-split-task --definition "<foo || bar || baz> && <qux || quux>"在前面的示例中,foo,bar和baz任务是并行启动的。
一旦它们全部完成,那么qux和quux任务是并行启动的。
完成后,组合的任务将结束。
但是,如果foo,bar或bazfails 时,包含qux和quux未启动。
使用 Spring Cloud Data Flow Dashboard 创建相同的“split with multiple groups”将类似于下图:
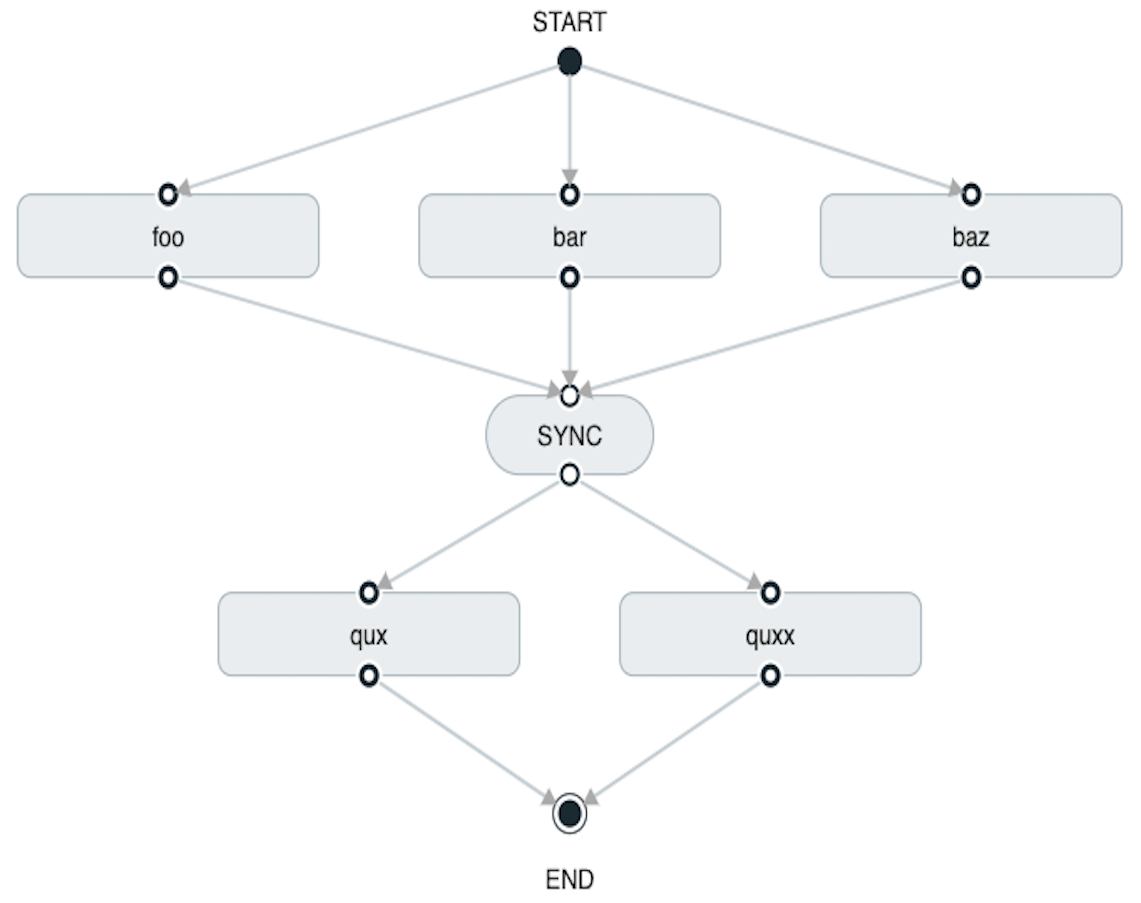
请注意,有一个SYNC设计器在
连接两个连续的分片。
拆分中使用的任务不应设置其ExitMessage.设置ExitMessage仅用于使用
with transitions. |
29.3.1. 包含条件执行的 split
split 还可以在尖括号内具有条件执行,如以下示例所示:
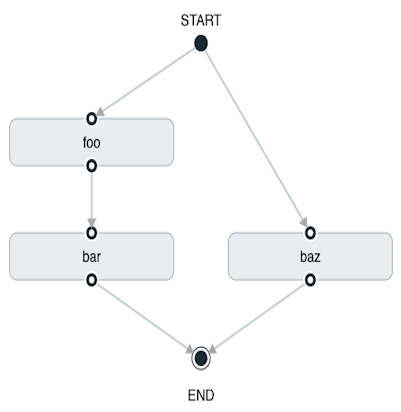
task create my-split-task --definition "<foo && bar || baz>"在前面的示例中,我们看到foo和baz并行启动。
然而bar在foo成功完成。
使用 Spring Cloud Data Flow Dashboard 创建相同的”split containing conditional execution“ 类似于下图:
29.3.2. 为 split 建立正确的线程数
拆分中包含的每个子任务都需要一个线程才能运行。要正确设置此设置,您需要查看图表并找到子任务数量最多的拆分。该拆分中的子任务数是您需要的线程数。
要设置线程计数,请使用split-thread-core-pool-size property(默认为1).因此,例如,诸如<AAA || BBB || CCC> && <DDD || EEE>需要split-thread-core-pool-size之3.
这是因为最大的拆分包含三个子任务。计数 2 意味着AAA和BBB将并行运行,但 CCC 将等待AAA或BBB完成才能运行。
然后DDD和EEE将并行运行。
30. 从 Stream 启动任务
您可以使用task-launcher-dataflowsink 中,它是作为 Spring Cloud Data Flow 项目的一部分提供的。
接收器连接到数据流服务器,并使用其 REST API 启动任何定义的任务。
接收器接受表示task launch request,它提供要启动的任务的名称,并且可能包括命令行参数和部署属性。
这task-launch-request-function组件与 Spring Cloud Stream 功能组合相结合,可以将任何源或处理器的输出转换为任务启动请求。
添加依赖项task-launch-request-function自动配置java.util.function.Function实现,通过 Spring Cloud Function 注册为taskLaunchRequest.
例如,您可以从时间源开始,添加以下依赖项,构建它,然后将其注册为自定义源。
<dependency>
<groupId>org.springframework.cloud.stream.app</groupId>
<artifactId>app-starters-task-launch-request-common</artifactId>
</dependency>要构建应用程序,请按照此处的说明进行作。
这将创建一个apps目录,其中包含time-source-rabbit和time-source-kafka目录中的<stream app project>/applications/source/time-source目录。在每一个 API 中,您将看到一个目标目录,其中包含一个time-source-<binder>-<version>.jar.现在注册time-sourcejar(使用适当的 Binder jar),并将 SCDF 作为名为timestamp-tlr.
接下来,注册task-launcher-dataflowsink 并创建任务定义timestamp-task.完成此作后,创建流定义,如下所示:
stream create --name task-every-minute --definition 'timestamp-tlr --fixed-delay=60000 --task.launch.request.task-name=timestamp-task --spring.cloud.function.definition=\"timeSupplier|taskLaunchRequestFunction\"| tasklauncher-sink' --deploy前面的流每分钟生成一个任务启动请求。该请求提供要启动的任务的名称:{"name":"timestamp-task"}.
以定义说明了命令行参数的用法。它生成如下消息{"args":["foo=bar","time=12/03/18 17:44:12"],"deploymentProps":{},"name":"timestamp-task"}要为任务提供命令行参数,请执行以下作:
stream create --name task-every-second --definition 'timestamp-tlr --task.launch.request.task-name=timestamp-task --spring.cloud.function.definition=\"timeSupplier|taskLaunchRequestFunction\" --task.launch.request.args=foo=bar --task.launch.request.arg-expressions=time=payload | tasklauncher-sink' --deploy请注意,使用 SPEL 表达式将每个消息有效负载映射到time命令行参数以及静态参数 (foo=bar).
然后,您可以使用 shell 命令查看任务执行列表task execution list,如以下示例中所示(及其输出):
dataflow:>task execution list
╔══════════════╤═══╤════════════════════════════╤════════════════════════════╤═════════╗
║ Task Name │ID │ Start Time │ End Time │Exit Code║
╠══════════════╪═══╪════════════════════════════╪════════════════════════════╪═════════╣
║timestamp-task│581│Thu Sep 08 11:38:33 EDT 2022│Thu Sep 08 11:38:33 EDT 2022│0 ║
║timestamp-task│580│Thu Sep 08 11:38:31 EDT 2022│Thu Sep 08 11:38:31 EDT 2022│0 ║
║timestamp-task│579│Thu Sep 08 11:38:29 EDT 2022│Thu Sep 08 11:38:29 EDT 2022│0 ║
║timestamp-task│578│Thu Sep 08 11:38:26 EDT 2022│Thu Sep 08 11:38:26 EDT 2022│0 ║
╚══════════════╧═══╧════════════════════════════╧════════════════════════════╧═════════╝在此示例中,我们展示了如何使用timesource 以固定速率启动任务。
此模式可应用于任何源,以启动任务以响应任何事件。
30.1. 从 Stream 启动组合任务
组合任务可以使用task-launcher-dataflowsink 的 intent 中,如此处所述。
由于我们使用ComposedTaskRunner直接,我们需要在创建组合任务启动流之前,为组合任务运行程序本身以及组合任务设置任务定义。
假设我们想要创建以下组合任务定义:AAA && BBB.
第一步是创建任务定义,如以下示例所示:
task create --name composed-task-sample --definition "AAA: timestamp && BBB: timestamp"现在,组合任务定义所需的任务定义已准备就绪,我们需要创建一个可启动的流composed-task-sample.
我们使用以下内容创建流:
-
这
timestamp-tlrsource 自定义以发出任务启动请求,如前所述。 -
这
task-launchersink 启动composed-task-sample
流应类似于以下内容:
stream create --name ctr-stream --definition "timestamp-tlr --fixed-delay=30000 --spring.cloud.function.definition=\"timeSupplier|taskLaunchRequestFunction\" --task.launch.request.task-name=composed-task-sample | tasklauncher-sink" --deploy31. 与任务共享 Spring Cloud Data Flow 的数据存储
如 Tasks 文档中所述,Spring Cloud Data Flow 允许您查看 Spring Cloud Task 应用程序执行情况。所以,在 本节将讨论任务应用程序和 Spring 所需的内容 Cloud Data Flow 共享任务执行信息。
31.1. 通用 DataStore 依赖项
Spring Cloud Data Flow 支持许多开箱即用的数据库、
因此,您通常需要做的就是声明spring_datasource_*环境变量
确定 Spring Cloud Data Flow 需要的数据存储。
无论您决定将哪个数据库用于 Spring Cloud Data Flow,请确保您的任务还
将该数据库依赖项包含在其pom.xml或gradle.build文件。如果数据库依赖项
,则任务应用程序
并且不会记录任务执行情况。
31.2. 通用数据存储
Spring Cloud Data Flow 和您的任务应用程序必须访问相同的数据存储实例。 这样,Spring Cloud Data Flow 就可以读取任务应用程序记录的任务执行,以便在 Shell 和 Dashboard 视图中列出它们。 此外,任务应用程序必须对 Spring Cloud Data Flow 使用的任务数据表具有读取和写入权限。
了解了 Task 应用程序和 Spring Cloud Data Flow 之间的数据源依赖关系后,您现在可以回顾如何在各种 Task 编排场景中应用它们。
31.2.1. 简单任务启动
从 Spring Cloud Data Flow 启动任务时,Data Flow 会添加其数据源
属性 (spring.datasource.url,spring.datasource.driverClassName,spring.datasource.username,spring.datasource.password)
添加到正在启动的任务的应用程序属性中。因此,任务应用程序
将其任务执行信息记录到 Spring Cloud Data Flow 仓库中。
32. 调度任务
Spring Cloud Data Flow 允许您使用cron表达。
您可以通过 RESTful API 或 Spring Cloud Data Flow UI 创建计划。
32.1. 调度器
Spring Cloud Data Flow 通过云平台上提供的调度代理来调度其任务的执行。 使用 Cloud Foundry 平台时, Spring Cloud Data Flow 使用 PCF Scheduler。 使用 Kubernetes 时,将使用 CronJob。
| 定时任务不实现持续部署功能。对 Spring Cloud Data Flow 中任务定义的应用程序版本或属性的任何更改都不会影响计划任务。 |

32.2. 启用 Scheduling
默认情况下,Spring Cloud Data Flow 会禁用调度功能。要启用计划功能,请将以下功能属性设置为true:
-
spring.cloud.dataflow.features.schedules-enabled -
spring.cloud.dataflow.features.tasks-enabled
32.3. Schedule 的生命周期
计划的生命周期分为三个部分:
32.3.1. 调度任务执行
您可以通过以下方式安排任务执行:
-
Spring Cloud 数据流 Shell
-
Spring Cloud 数据流仪表板
-
Spring Cloud Data Flow RESTful API
32.3.2. 调度任务
要使用 shell 调度任务,请使用task schedule create命令创建计划,如以下示例所示:
dataflow:>task schedule create --definitionName mytask --name mytaskschedule --expression '*/1 * * * *'
Created schedule 'mytaskschedule'在前面的示例中,我们创建了一个名为mytaskschedule对于名为mytask.此计划启动mytask每分钟一次。
如果使用 Cloud Foundry,则cron表达式为:*/1 * ? * *.这是因为 Cloud Foundry 使用 Quartzcron表达式格式。 |
32.3.3. 删除调度
您可以使用以下方法删除计划:
-
Spring Cloud 数据流 Shell
-
Spring Cloud 数据流仪表板
-
Spring Cloud Data Flow RESTful API
要使用 shell 删除任务计划,请使用task schedule destroy命令,如以下示例所示:
dataflow:>task schedule destroy --name mytaskschedule
Deleted task schedule 'mytaskschedule'32.3.4. 上架时间表
您可以使用以下方法查看可用的计划:
-
Spring Cloud 数据流 Shell
-
Spring Cloud 数据流仪表板
-
Spring Cloud Data Flow RESTful API
要从 shell 查看调度,请使用task schedule list命令,如以下示例所示:
dataflow:>task schedule list
╔══════════════════════════╤════════════════════╤════════════════════════════════════════════════════╗
║ Schedule Name │Task Definition Name│ Properties ║
╠══════════════════════════╪════════════════════╪════════════════════════════════════════════════════╣
║mytaskschedule │mytask │spring.cloud.scheduler.cron.expression = */1 * * * *║
╚══════════════════════════╧════════════════════╧════════════════════════════════════════════════════╝| 有关使用 Spring Cloud Data Flow UI 创建、删除和列出计划的说明,请参阅此处。 |
33. 持续部署
随着任务应用程序的发展,您希望将更新用于生产。本节介绍 Spring Cloud Data Flow 提供的有关能够更新任务应用程序的功能。
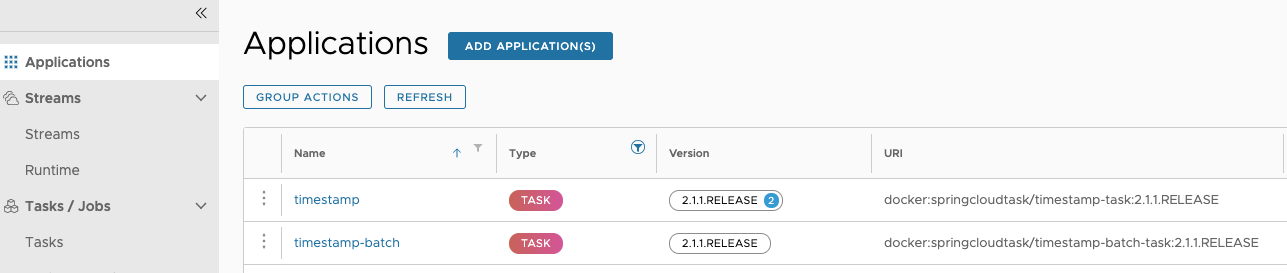
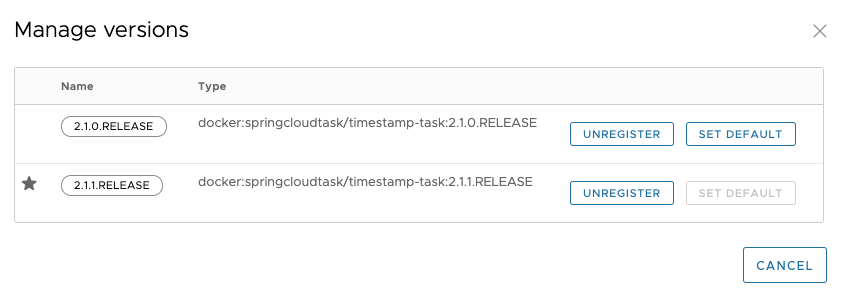
注册任务应用程序时(请参阅注册任务应用程序),将有一个版本与之关联。任务应用程序可以有多个与之关联的版本,其中一个版本被选为默认版本。下图说明了具有多个关联版本的应用程序(请参阅时间戳条目)。
通过注册多个具有相同名称和坐标 (版本) 的应用程序来管理应用程序的版本。例如,如果要使用以下值注册应用程序,则会使用两个版本(2.1.0.RELEASE 和 2.1.1.RELEASE)注册一个应用程序:
-
应用 1
-
名字:
timestamp -
类型:
task -
URI 中:
maven://org.springframework.cloud.task.app:timestamp-task:2.1.0.RELEASE
-
-
应用 2
-
名字:
timestamp -
类型:
task -
URI 中:
maven://org.springframework.cloud.task.app:timestamp-task:2.1.1.RELEASE
-
除了具有多个版本之外, Spring Cloud Data Flow 还需要知道下次启动时要运行哪个版本。通过将版本设置为默认版本来表示这一点。无论将任务应用程序配置为默认版本,都将在下一个启动请求上运行的版本。您可以在 UI 中看到哪个版本是默认版本,如下图所示:
33.1. 任务启动生命周期
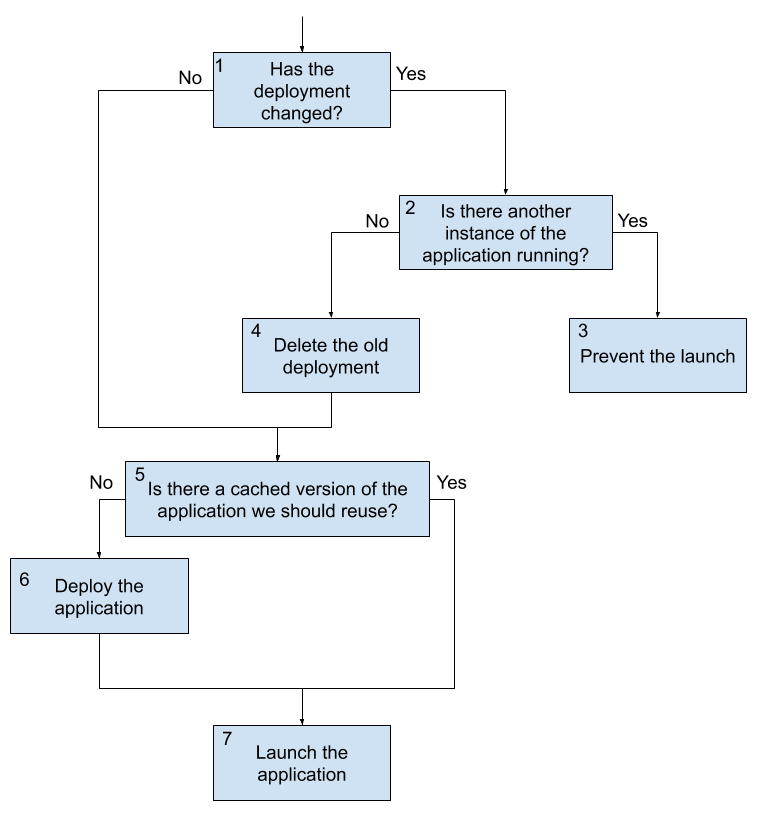
在早期版本的 Spring Cloud Data Flow 中,当收到启动任务的请求时, Spring Cloud Data Flow 将部署应用程序(如果需要)并运行它。如果应用程序在不需要每次都部署应用程序的平台上运行(例如 CloudFoundry),则使用以前部署的应用程序。此流程在 2.3 中已更改。下图显示了现在收到任务启动请求时会发生什么情况:
在上图中,有三个主要流程需要考虑。首次启动或不进行任何更改启动就是其中之一。另外两个是在有更改但应用程序当前没有时启动,以及在有更改且应用程序正在运行时启动。我们首先查看没有变化的流程。
33.1.1. 启动不做任何更改的任务
-
Launch 请求进入 Data Flow。Data Flow 确定不需要升级,因为未更改任何内容(自上次执行以来未更改任何属性、部署属性或版本)。
-
在缓存已部署构件的平台(在撰写本文时为 CloudFoundry)上,Data Flow 会检查应用程序之前是否已部署。
-
如果需要部署应用程序,Data Flow 将部署任务应用程序。
-
Data Flow 将启动应用程序。
此流是默认行为,如果未更改任何内容,则每次收到请求时都会发生。请注意,这是 Data Flow 始终用于启动任务的相同流。
33.1.2. 启动当前未运行的包含更改的任务
启动任务时要考虑的第二个流程是当任务未运行但任何任务应用程序版本、应用程序属性或部署属性发生更改时。在这种情况下,将执行以程:
-
Launch 请求进入 Data Flow。Data Flow 确定需要升级,因为任务应用程序版本、应用程序属性或部署属性发生了更改。
-
Data Flow 检查以查看任务定义的另一个实例当前是否正在运行。
-
如果当前没有正在运行的任务定义的其他实例,则会删除旧部署。
-
在缓存已部署构件的平台上(在撰写本文时为 CloudFoundry),Data Flow 检查应用程序之前是否已部署(此检查的计算结果为
false在此流程中,由于旧部署已被删除)。 -
Data Flow 使用更新的值(新的应用程序版本、新的合并属性和新的合并部署属性)来部署任务应用程序。
-
Data Flow 将启动应用程序。
此流程从根本上支持 Spring Cloud Data Flow 的持续部署。
33.1.3. 在另一个实例运行时启动包含更改的任务
最后一个主流是当启动请求到达 Spring Cloud Data Flow 进行升级,但任务定义当前正在运行时。在这种情况下,由于需要删除当前应用程序,启动将被阻止。在某些平台(在撰写本文时为 CloudFoundry)上,删除应用程序会导致所有当前正在运行的应用程序关闭。此功能可以防止这种情况发生。以下过程描述了当任务发生更改而另一个实例正在运行时会发生什么情况:
-
Launch 请求进入 Data Flow。Data Flow 确定需要升级,因为任务应用程序版本、应用程序属性或部署属性发生了更改。
-
Data Flow 检查以查看任务定义的另一个实例当前是否正在运行。
-
Data Flow 会阻止启动,因为任务定义的其他实例正在运行。
| 由于需要删除任何当前正在运行的任务,因此需要升级在请求时正在运行的任务定义的任何启动都将被阻止运行。 |