高级元数据用法
到目前为止,JobLauncher和JobRepositoryinterfaces 已被
讨论。它们共同代表了 Job 和 Basic 的简单启动
批处理域对象的 CRUD作:
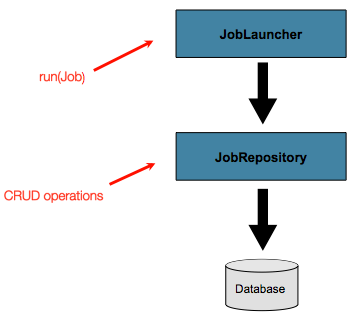
一个JobLauncher使用JobRepository新建JobExecution对象并运行它们。Job和Step实现
later use same (稍后使用相同的JobRepository对于基本更新
在Job.
基本作足以满足简单的场景。但是,在大批量
具有数百个批处理作业和复杂调度的环境
要求,则需要对元数据进行更高级的访问:
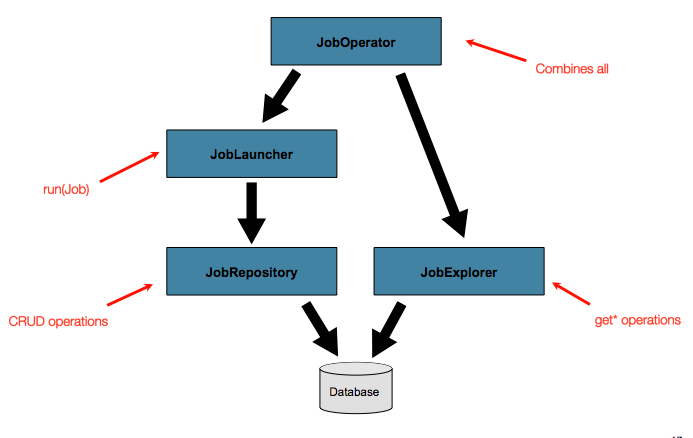
这JobExplorer和JobOperator接口,将对此进行讨论
在接下来的部分中,添加用于查询和控制元数据的其他功能。
查询存储库
在任何高级功能之前,最基本的需求是能够
查询存储库中的现有执行。此功能是
由JobExplorer接口:
public interface JobExplorer {
List<JobInstance> getJobInstances(String jobName, int start, int count);
JobExecution getJobExecution(Long executionId);
StepExecution getStepExecution(Long jobExecutionId, Long stepExecutionId);
JobInstance getJobInstance(Long instanceId);
List<JobExecution> getJobExecutions(JobInstance jobInstance);
Set<JobExecution> findRunningJobExecutions(String jobName);
}从其方法签名中可以明显看出,JobExplorer是 的只读版本
这JobRepository和JobRepository,它可以通过使用
工厂 Bean 的 Bean 中。
-
Java
-
XML
以下示例显示如何配置JobExplorer在 Java 中:
...
// This would reside in your DefaultBatchConfiguration extension
@Bean
public JobExplorer jobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
return factoryBean.getObject();
}
...以下示例显示如何配置JobExplorer在 XML 中:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:dataSource-ref="dataSource" />在本章的前面部分,我们注意到您可以修改表前缀
的JobRepository以允许不同的版本或架构。因为
这JobExplorer适用于相同的表,它还需要能够设置前缀。
-
Java
-
XML
以下示例显示如何为JobExplorer在 Java 中:
...
// This would reside in your DefaultBatchConfiguration extension
@Bean
public JobExplorer jobExplorer() throws Exception {
JobExplorerFactoryBean factoryBean = new JobExplorerFactoryBean();
factoryBean.setDataSource(this.dataSource);
factoryBean.setTablePrefix("SYSTEM.");
return factoryBean.getObject();
}
...以下示例显示如何为JobExplorer在 XML 中:
<bean id="jobExplorer" class="org.spr...JobExplorerFactoryBean"
p:tablePrefix="SYSTEM."/>JobRegistry (作业注册表)
一个JobRegistry(及其父接口JobLocator) 不是必需的,但可以是
如果要跟踪上下文中可用的作业,则很有用。它也是
在创建作业时,用于在应用程序上下文中集中收集作业
其他位置(例如,在子上下文中)。您也可以使用自定义JobRegistry实现
作已注册作业的名称和其他属性。
框架只提供了一个实现,它基于一个简单的
从 Job Name 映射到 Job Instance。
-
Java
-
XML
使用@EnableBatchProcessing一个JobRegistry为您提供。
以下示例显示如何配置您自己的JobRegistry:
...
// This is already provided via the @EnableBatchProcessing but can be customized via
// overriding the bean in the DefaultBatchConfiguration
@Override
@Bean
public JobRegistry jobRegistry() throws Exception {
return new MapJobRegistry();
}
...以下示例显示了如何包含JobRegistry对于在 XML 中定义的作业:
<bean id="jobRegistry" class="org.springframework.batch.core.configuration.support.MapJobRegistry" />您可以填充JobRegistry通过以下方式之一:通过使用
bean 后处理器,或者通过使用智能初始化单例或使用
注册商生命周期组件。接下来的各节将介绍这些机制。
JobRegistryBeanPostProcessor
这是一个 bean 后处理器,可以在创建所有作业时注册它们。
-
Java
-
XML
以下示例显示了如何包含JobRegistryBeanPostProcessor对于作业
在 Java 中定义:
@Bean
public JobRegistryBeanPostProcessor jobRegistryBeanPostProcessor(JobRegistry jobRegistry) {
JobRegistryBeanPostProcessor postProcessor = new JobRegistryBeanPostProcessor();
postProcessor.setJobRegistry(jobRegistry);
return postProcessor;
}以下示例显示了如何包含JobRegistryBeanPostProcessor对于作业
在 XML 中定义:
<bean id="jobRegistryBeanPostProcessor" class="org.spr...JobRegistryBeanPostProcessor">
<property name="jobRegistry" ref="jobRegistry"/>
</bean>尽管并非绝对必要,但
example 已经给出了一个id,以便它可以包含在 Child 中
contexts(例如,作为父 Bean 定义)并导致创建所有作业
那里也会自动注册。
|
折旧
从版本 5.2 开始, |
JobRegistrySmartInitializingSingleton
这是一个SmartInitializingSingleton这将在 Job Registry 中注册所有 Singleton Job。
-
Java
-
XML
以下示例演示如何定义JobRegistrySmartInitializingSingleton在 Java 中:
@Bean
public JobRegistrySmartInitializingSingleton jobRegistrySmartInitializingSingleton(JobRegistry jobRegistry) {
return new JobRegistrySmartInitializingSingleton(jobRegistry);
}以下示例演示如何定义JobRegistrySmartInitializingSingleton在 XML 中:
<bean class="org.springframework.batch.core.configuration.support.JobRegistrySmartInitializingSingleton">
<property name="jobRegistry" ref="jobRegistry" />
</bean>自动作业注册器
这是一个生命周期组件,用于创建子上下文并从中注册作业
上下文。这样做的一个好处是,虽然
子上下文在 Registry 中仍然必须是全局唯一的,它们的依赖项
可以有 “natural” 名称。因此,例如,您可以创建一组 XML 配置文件
每个 Job 只有一个 Job 但都有不同的ItemReader使用
相同的 bean 名称,例如reader.如果所有这些文件都导入到同一上下文中,则
Reader 定义会相互冲突并覆盖,但是,使用 Automatic
registrar 的 intent 和未加密的 intent 的 x这使得集成
应用程序的单独模块。
-
Java
-
XML
以下示例显示了如何包含AutomaticJobRegistrar对于定义的作业
在 Java 中:
@Bean
public AutomaticJobRegistrar registrar() {
AutomaticJobRegistrar registrar = new AutomaticJobRegistrar();
registrar.setJobLoader(jobLoader());
registrar.setApplicationContextFactories(applicationContextFactories());
registrar.afterPropertiesSet();
return registrar;
}以下示例显示了如何包含AutomaticJobRegistrar对于定义的作业
在 XML 中:
<bean class="org.spr...AutomaticJobRegistrar">
<property name="applicationContextFactories">
<bean class="org.spr...ClasspathXmlApplicationContextsFactoryBean">
<property name="resources" value="classpath*:/config/job*.xml" />
</bean>
</property>
<property name="jobLoader">
<bean class="org.spr...DefaultJobLoader">
<property name="jobRegistry" ref="jobRegistry" />
</bean>
</property>
</bean>registrar 具有两个必需属性:一个ApplicationContextFactory(从
方便的工厂 Bean)和JobLoader.这JobLoader负责管理子上下文的生命周期,并且
在JobRegistry.
这ApplicationContextFactory是
负责创建子上下文。最常见的用法
是(如前面的示例所示)来使用ClassPathXmlApplicationContextFactory.其中之一
这个工厂的特点是,默认情况下,它会复制一些
configuration down 从 parent context 到 child。因此,对于
实例中,您无需重新定义PropertyPlaceholderConfigurer或 AOP
配置,前提是它应与
父母。
您可以使用AutomaticJobRegistrar在
与JobRegistryBeanPostProcessor(只要您同时使用DefaultJobLoader).
例如,如果有工作,这可能是可取的
在主父上下文和子上下文中定义
地点。
JobOperator (作业作员)
如前所述,JobRepository提供对元数据的 CRUD作,并且JobExplorer在
元数据。但是,这些作在一起使用时最有用
执行常见监控任务,例如停止、重新启动或
总结 Job,这通常是由 Batch Operator 完成的。Spring Batch
在JobOperator接口:
public interface JobOperator {
List<Long> getExecutions(long instanceId) throws NoSuchJobInstanceException;
List<Long> getJobInstances(String jobName, int start, int count)
throws NoSuchJobException;
Set<Long> getRunningExecutions(String jobName) throws NoSuchJobException;
String getParameters(long executionId) throws NoSuchJobExecutionException;
Long start(String jobName, String parameters)
throws NoSuchJobException, JobInstanceAlreadyExistsException;
Long restart(long executionId)
throws JobInstanceAlreadyCompleteException, NoSuchJobExecutionException,
NoSuchJobException, JobRestartException;
Long startNextInstance(String jobName)
throws NoSuchJobException, JobParametersNotFoundException, JobRestartException,
JobExecutionAlreadyRunningException, JobInstanceAlreadyCompleteException;
boolean stop(long executionId)
throws NoSuchJobExecutionException, JobExecutionNotRunningException;
String getSummary(long executionId) throws NoSuchJobExecutionException;
Map<Long, String> getStepExecutionSummaries(long executionId)
throws NoSuchJobExecutionException;
Set<String> getJobNames();
}上述作表示来自许多不同接口的方法,例如JobLauncher,JobRepository,JobExplorer和JobRegistry.因此,
提供了JobOperator (SimpleJobOperator) 具有许多依赖项。
-
Java
-
XML
以下示例显示了SimpleJobOperator在 Java 中:
/**
* All injected dependencies for this bean are provided by the @EnableBatchProcessing
* infrastructure out of the box.
*/
@Bean
public SimpleJobOperator jobOperator(JobExplorer jobExplorer,
JobRepository jobRepository,
JobRegistry jobRegistry,
JobLauncher jobLauncher) {
SimpleJobOperator jobOperator = new SimpleJobOperator();
jobOperator.setJobExplorer(jobExplorer);
jobOperator.setJobRepository(jobRepository);
jobOperator.setJobRegistry(jobRegistry);
jobOperator.setJobLauncher(jobLauncher);
return jobOperator;
}以下示例显示了SimpleJobOperator在 XML 中:
<bean id="jobOperator" class="org.spr...SimpleJobOperator">
<property name="jobExplorer">
<bean class="org.spr...JobExplorerFactoryBean">
<property name="dataSource" ref="dataSource" />
</bean>
</property>
<property name="jobRepository" ref="jobRepository" />
<property name="jobRegistry" ref="jobRegistry" />
<property name="jobLauncher" ref="jobLauncher" />
</bean>从版本 5.0 开始,@EnableBatchProcessing注解自动注册作业作员 Bean
在应用程序上下文中。
| 如果您在作业存储库上设置了表前缀,请不要忘记在作业资源管理器中也设置它。 |
JobParametersIncrementer (作业参数增量器)
大多数JobOperator是
一目了然,您可以在界面的 Javadoc 中找到更详细的解释。但是,startNextInstance方法值得注意。这
方法始终会启动Job.
如果JobExecution和Job需要从头开始。与JobLauncher(这需要一个新的JobParameters对象触发新的JobInstance),如果参数与
任何先前的参数集,则startNextInstance方法使用JobParametersIncrementer绑定到Job以强制Job更改为
新建实例:
public interface JobParametersIncrementer {
JobParameters getNext(JobParameters parameters);
}的合同JobParametersIncrementer是
给定一个 JobParameters 对象,它返回 “next”JobParametersobject 来增加它可能包含的任何必要值。这
策略很有用,因为框架无法知道
对JobParameters使其成为 “Next”
实例。例如,如果JobParameters是日期,下一个实例
应该创建,该值应增加 1 天或 1
周(例如,如果工作是每周)?任何
有助于识别Job,
如下例所示:
public class SampleIncrementer implements JobParametersIncrementer {
public JobParameters getNext(JobParameters parameters) {
if (parameters==null || parameters.isEmpty()) {
return new JobParametersBuilder().addLong("run.id", 1L).toJobParameters();
}
long id = parameters.getLong("run.id",1L) + 1;
return new JobParametersBuilder().addLong("run.id", id).toJobParameters();
}
}在此示例中,键为run.id用于
区分JobInstances.如果JobParameters传入为 null,则可以是
假设Job以前从未运行
因此,可以返回其初始状态。但是,如果不是,则旧的
value 被获取,递增 1 并返回。
-
Java
-
XML
对于在 Java 中定义的作业,您可以将增量程序与Job通过incrementer方法,如下所示:
@Bean
public Job footballJob(JobRepository jobRepository) {
return new JobBuilder("footballJob", jobRepository)
.incrementer(sampleIncrementer())
...
.build();
}对于在 XML 中定义的作业,您可以将增量程序与Job通过incrementer属性,如下所示:
<job id="footballJob" incrementer="sampleIncrementer">
...
</job>停止作业
最常见的用例之一JobOperator会正常停止
工作:
Set<Long> executions = jobOperator.getRunningExecutions("sampleJob");
jobOperator.stop(executions.iterator().next());关闭不是立即的,因为没有办法强制
立即关闭,尤其是在执行当前处于
开发人员代码,例如
商业服务。但是,一旦控制权返回到
框架中,它会设置当前StepExecution自BatchStatus.STOPPED,保存它,并执行相同的作
对于JobExecution在完成之前。
中止作业
任务执行FAILED可以是
restarted(如果Job是可重新启动的)。状态为ABANDONED无法由框架重新启动。
这ABANDONEDstatus 也用于 STEP 中
executions 在重新启动的任务执行中将其标记为可跳过。如果
作业正在运行,并遇到已标记的步骤ABANDONED在上一个失败的任务执行中,它
继续执行下一步(由 Job Flow 定义确定
和步骤执行退出状态)。
如果进程宕机 (kill -9或 server
failure),则作业当然不会运行,但JobRepository具有
无法知道,因为在过程结束之前没有人告诉它。你
必须手动告诉它您知道执行失败
或应被视为已中止(将其状态更改为FAILED或ABANDONED).这是
一个商业决策,没有办法自动化它。更改
status 设置为FAILED仅当它是可重新启动的并且您知道重新启动数据有效时。