项读取和写入
ItemReaders 和 ItemWriters
所有批处理都可以用最简单的形式描述为大量读取
的数据,执行某种类型的计算或转换,并写入结果
外。Spring Batch 提供了三个关键接口来帮助执行批量读取和写入:、 和 。ItemReaderItemProcessorItemWriter
ItemReader
虽然概念简单,但 an 是提供来自许多
不同类型的输入。最常见的示例包括:ItemReader
-
平面文件:平面文件项读取器从平面文件中读取数据行,通常 描述其数据字段由文件中的固定位置定义或分隔的记录 通过一些特殊字符(如逗号)。
-
XML:独立于用于解析的技术的 XML 处理 XML, 映射和验证对象。输入数据允许验证 XML 文件 针对 XSD 架构。
ItemReaders -
Database:访问数据库资源以返回可映射到 对象进行处理。默认的 SQL 实现调用 a 返回对象,如果需要重新启动,则跟踪当前行,存储 basic 统计信息,并提供一些事务增强功能,稍后将对此进行说明。
ItemReaderRowMapper
还有更多可能性,但本章我们将重点介绍基本的可能性。一个
所有可用实现的完整列表可在附录 A 中找到。ItemReader
ItemReader是泛型
input 操作,如以下接口定义所示:
public interface ItemReader<T> {
T read() throws Exception, UnexpectedInputException, ParseException, NonTransientResourceException;
}
该方法定义了 .调用它
返回一个项目,或者没有更多项目。一个项目可能表示
文件、数据库中的一行或 XML 文件中的元素。通常预期
这些对象被映射到可用的域对象(例如 、 或其他),但是
是合同中没有要求这样做的。readItemReadernullTradeFoo
预计接口的实现仅向前。
但是,如果底层资源是事务性的(例如 JMS 队列),则在回滚场景中,调用可能会在后续调用中返回相同的逻辑项。是的
另外值得注意的是,缺少要由 an 处理的项目不会导致
异常。例如,配置了
返回 0 个结果的查询在第一次调用 .ItemReaderreadItemReaderItemReadernullread
ItemWriter
ItemWriter在功能上类似于 an,但具有逆运算。
资源仍然需要定位、打开和关闭,但它们的不同之处在于 write out,而不是读入。对于数据库或队列,
这些操作可以是 INSERTS、UPDATES 或 SENDS。的序列化格式
输出特定于每个批处理作业。ItemReaderItemWriter
与 一样,是一个相当通用的接口,如下面的接口定义所示:ItemReaderItemWriter
public interface ItemWriter<T> {
void write(Chunk<? extends T> items) throws Exception;
}
与 on 一样,提供 的基本协定。它
尝试写出传入的项列表,只要该列表处于打开状态。因为它是
通常期望将项目一起“批处理”到一个块中,然后输出
interface 接受 Item 列表,而不是 Item 本身。写出
list 中,任何可能需要的刷新都可以在从写入返回之前执行
方法。例如,如果写入 Hibernate DAO,则可以多次调用 write,
每个项目一个。然后,编写器可以在
返回。readItemReaderwriteItemWriterflush
ItemStream
两者都很好地服务于各自的目的,但有一个
他们俩都关心需要另一个接口。一般来说,作为
作为批处理作业范围的一部分,读取器和写入器需要打开、关闭,并且
需要一种持久化状态的机制。该接口用于此目的,
如以下示例所示:ItemReadersItemWritersItemStream
public interface ItemStream {
void open(ExecutionContext executionContext) throws ItemStreamException;
void update(ExecutionContext executionContext) throws ItemStreamException;
void close() throws ItemStreamException;
}
在描述每种方法之前,我们应该提到 .同时实现的 的 客户端应在对 进行任何调用之前调用 ,以便打开任何资源(如文件)或获取连接。类似的
限制适用于实现 .如
第 2 章,如果在 中找到了预期的数据,则可以用来启动
或位于其初始状态以外的位置。相反,调用以确保安全释放 open 期间分配的任何资源。 主要是为了确保当前持有的任何状态都加载到
提供的 .此方法在提交之前调用,以确保
当前状态在提交之前保留在数据库中。ExecutionContextItemReaderItemStreamopenreadItemWriterItemStreamExecutionContextItemReaderItemWritercloseupdateExecutionContext
在特殊情况下,an 的客户端是 (来自 Spring
Batch Core),为每个 StepExecution 创建一个,以允许用户
存储特定执行的状态,如果
同样的事情又开始了。对于熟悉 Quartz 的人来说,语义
与 Quartz 非常相似。ItemStreamStepExecutionContextJobInstanceJobDataMap
委托模式和注册步骤
请注意,这是委托模式的一个示例,即
常见于 Spring Batch 中。委托本身可以实现回调接口
如。如果它们这样做,并且它们是否与 Spring 结合使用
Batch Core 作为 a 中的一部分,那么它们几乎肯定需要
手动注册到 .直接
如果 wire 实现 或 接口,则会自动注册。但是,由于 ,
它们需要作为侦听器或流注入(或两者兼而有之,如果合适)。CompositeItemWriterStepListenerStepJobStepStepItemStreamStepListenerStep
下面的示例演示如何在 XML 中将委托作为流注入:
<job id="ioSampleJob">
<step name="step1">
<tasklet>
<chunk reader="fooReader" processor="fooProcessor" writer="compositeItemWriter"
commit-interval="2">
<streams>
<stream ref="barWriter" />
</streams>
</chunk>
</tasklet>
</step>
</job>
<bean id="compositeItemWriter" class="...CustomCompositeItemWriter">
<property name="delegate" ref="barWriter" />
</bean>
<bean id="barWriter" class="...BarWriter" />下面的示例演示如何在 XML 中将委托作为流注入:
@Bean
public Job ioSampleJob(JobRepository jobRepository) {
return new JobBuilder("ioSampleJob", jobRepository)
.start(step1())
.build();
}
@Bean
public Step step1(JobRepository jobRepository, PlatformTransactionManager transactionManager) {
return new StepBuilder("step1", jobRepository)
.<String, String>chunk(2, transactionManager)
.reader(fooReader())
.processor(fooProcessor())
.writer(compositeItemWriter())
.stream(barWriter())
.build();
}
@Bean
public CustomCompositeItemWriter compositeItemWriter() {
CustomCompositeItemWriter writer = new CustomCompositeItemWriter();
writer.setDelegate(barWriter());
return writer;
}
@Bean
public BarWriter barWriter() {
return new BarWriter();
}
平面文件
交换批量数据的最常见机制之一一直是平面 文件。与 XML 不同,XML 有一个公认的标准来定义其结构 (XSD) 中,任何读取平面文件的人都必须提前了解文件的确切情况 结构。通常,所有平面文件都分为两种类型:分隔和固定长度。 分隔文件是指字段由分隔符(如逗号)分隔的文件。 Fixed Length 文件具有具有固定长度的字段。
这FieldSet
在 Spring Batch 中处理平面文件时,无论是用于 Importing 还是
output 中,最重要的类之一是 .许多架构和
库包含用于帮助您从文件中读入的抽象,但它们通常
返回 A 或 Object 数组。这真的只能让你成功一半
那里。A 是 Spring Batch 的抽象,用于启用字段的绑定
文件资源。它允许开发人员以与
他们将使用数据库输入。A 在概念上类似于 JDBC 。A 只需要一个参数:标记数组。
(可选)您还可以配置字段的名称,以便字段可以
按 index 或 name 访问,如 patterned after 所示,如下所示
例:FieldSetStringStringFieldSetFieldSetResultSetFieldSetStringResultSet
String[] tokens = new String[]{"foo", "1", "true"};
FieldSet fs = new DefaultFieldSet(tokens);
String name = fs.readString(0);
int value = fs.readInt(1);
boolean booleanValue = fs.readBoolean(2);
界面上还有更多选项,例如 、 long 和 等。最大的优点是它提供了
平面文件输入的一致解析。而不是每个批处理作业在
可能意想不到的方式,它可以是一致的,无论是在处理由
format 异常,或者在执行简单的数据转换时。FieldSetDateBigDecimalFieldSet
FlatFileItemReader
平面文件是最多包含二维(表格)数据的任何类型的文件。
名为 的类有助于在 Spring Batch 框架中读取平面文件,该类提供了读取和解析平面的基本功能
文件。的两个最重要的必需依赖项是 和 。该界面将在下一篇文章中详细介绍
部分。resource 属性表示 Spring Core 。文档
解释如何创建这种类型的 bean 可以在 Spring 中找到
框架,第 5 章。资源。因此,本指南不详细介绍
创建对象 除了显示以下简单示例之外:FlatFileItemReaderFlatFileItemReaderResourceLineMapperLineMapperResourceResource
Resource resource = new FileSystemResource("resources/trades.csv");
在复杂的批处理环境中,目录结构通常由 Enterprise Application Integration (EAI) 管理 基础结构,其中为外部接口建立了放置区以移动文件 从 FTP 位置到批处理位置,反之亦然。文件移动实用程序 超出了 Spring Batch 架构的范围,但对于 Batch 来说并不罕见 Job Streams 将文件移动实用程序作为 Job Stream 中的步骤包含在内。批次 架构只需要知道如何找到要处理的文件。Spring Batch 从此起点开始将数据馈送到管道的过程。但是, Spring 集成提供了许多 这些类型的服务。
中的其他属性允许您进一步指定数据的
解释,如下表所述:FlatFileItemReader
| 财产 | 类型 | 描述 |
|---|---|---|
评论 |
字符串 |
指定指示注释行的行前缀。 |
编码 |
字符串 |
指定要使用的文本编码。默认值为 . |
线映射器 |
|
将 a 转换为表示项的 an。 |
linesToSkip (行到 Skip) |
int |
文件顶部要忽略的行数。 |
recordSeparatorPolicy 的 |
RecordSeparatorPolicy 的 |
用于确定行尾的位置 并执行诸如 continue 之类的操作,以 if 结尾的行位于带引号的字符串内。 |
资源 |
|
要从中读取的资源。 |
skippedLines回调 |
LineCallbackHandler 线回调处理程序 |
将
文件中要跳过的行。如果设置为 2,则此接口为
被叫了两次。 |
严格 |
布尔 |
在严格模式下,读取器会在 if
输入资源不存在。否则,它会记录问题并继续。 |
LineMapper
与 一样,它采用低级结构,例如 and 返回
平面文件处理需要相同的构造来转换一行
转换为 ,如以下接口定义所示:RowMapperResultSetObjectStringObject
public interface LineMapper<T> {
T mapLine(String line, int lineNumber) throws Exception;
}
基本协定是,给定当前行及其行号
associated,则 Mapper 应返回一个结果域对象。这类似于 ,因为每行都与其行号相关联,就像 a 中的每一行都与其行号相关联一样。这允许将行号绑定到
生成的 domain 对象,用于身份比较或提供更多信息的日志记录。然而
与 不同,它给出了一条原始行,如上所述,只有
让你成功一半。该行必须被标记成一个 ,然后可以是
映射到对象,如本文档后面所述。RowMapperResultSetRowMapperLineMapperFieldSet
LineTokenizer
将一行 input 转换为 a 的抽象是必要的,因为
可以是需要转换为 .在
Spring Batch 中,这个接口是:FieldSetFieldSetLineTokenizer
public interface LineTokenizer {
FieldSet tokenize(String line);
}
a 的契约是这样的,给定一行输入(理论上可以包含多行),表示该行的 a 是
返回。然后,可以将此 API 传递给 .Spring Batch 包含
以下实现:LineTokenizerStringFieldSetFieldSetFieldSetMapperLineTokenizer
-
DelimitedLineTokenizer:用于记录中的字段由 定界符。最常见的分隔符是逗号,但通常使用竖线或分号 也。 -
FixedLengthTokenizer:用于记录中的字段均为“固定 宽度”。必须为每种记录类型定义每个字段的宽度。 -
PatternMatchingCompositeLineTokenizer:确定 应该通过检查模式来在特定行上使用分词器。LineTokenizer
FieldSetMapper
该接口定义了一个方法 ,该方法采用一个对象并将其内容映射到一个对象。此对象可以是自定义 DTO、
domain 对象或数组,具体取决于作业的需要。的
与 结合使用 以翻译资源中的一行数据
转换为所需类型的对象,如以下接口定义所示:FieldSetMappermapFieldSetFieldSetFieldSetMapperLineTokenizer
public interface FieldSetMapper<T> {
T mapFieldSet(FieldSet fieldSet) throws BindException;
}
使用的模式与 使用的模式相同。RowMapperJdbcTemplate
DefaultLineMapper
现在,用于读取平面文件的基本接口已经定义,它变为 明确需要三个基本步骤:
-
从文件中读取一行。
-
将该行传递到方法中以检索 .
StringLineTokenizer#tokenize()FieldSet -
将 returned from tokenizing 传递给 a ,返回 方法的结果。
FieldSetFieldSetMapperItemReader#read()
上面描述的两个接口代表两个独立的任务:将 line 转换为 a 并将 a 映射到域对象。因为 a 的输入与 (a line) 的输入匹配,并且 a 的输出与 ,所以默认实现
同时使用 a 和 a。这
如下面的类定义所示,表示大多数用户需要的行为:FieldSetFieldSetLineTokenizerLineMapperFieldSetMapperLineMapperLineTokenizerFieldSetMapperDefaultLineMapper
public class DefaultLineMapper<T> implements LineMapper<>, InitializingBean {
private LineTokenizer tokenizer;
private FieldSetMapper<T> fieldSetMapper;
public T mapLine(String line, int lineNumber) throws Exception {
return fieldSetMapper.mapFieldSet(tokenizer.tokenize(line));
}
public void setLineTokenizer(LineTokenizer tokenizer) {
this.tokenizer = tokenizer;
}
public void setFieldSetMapper(FieldSetMapper<T> fieldSetMapper) {
this.fieldSetMapper = fieldSetMapper;
}
}
上述功能在默认实现中提供,而不是构建 导入到 Reader 本身中(就像在框架的早期版本中所做的那样),以允许用户 在控制解析过程方面具有更大的灵活性,尤其是在访问 RAW 时 线路。
简单分隔文件读取示例
以下示例说明了如何使用实际域方案读取平面文件。 此特定批处理作业从以下文件中读取 football players:
ID,lastName,firstName,position,birthYear,debutYear "AbduKa00,Abdul-Jabbar,Karim,rb,1974,1996", "AbduRa00,Abdullah,Rabih,rb,1975,1999", "AberWa00,Abercrombie,Walter,rb,1959,1982", "AbraDa00,Abramowicz,Danny,wr,1945,1967", "AdamBo00,Adams,Bob,te,1946,1969", "AdamCh00,Adams,Charlie,wr,1979,2003"
此文件的内容将映射到以下域对象:Player
public class Player implements Serializable {
private String ID;
private String lastName;
private String firstName;
private String position;
private int birthYear;
private int debutYear;
public String toString() {
return "PLAYER:ID=" + ID + ",Last Name=" + lastName +
",First Name=" + firstName + ",Position=" + position +
",Birth Year=" + birthYear + ",DebutYear=" +
debutYear;
}
// setters and getters...
}
要将 a 映射到对象中,返回 players 的 a 需要
,如以下示例所示:FieldSetPlayerFieldSetMapper
protected static class PlayerFieldSetMapper implements FieldSetMapper<Player> {
public Player mapFieldSet(FieldSet fieldSet) {
Player player = new Player();
player.setID(fieldSet.readString(0));
player.setLastName(fieldSet.readString(1));
player.setFirstName(fieldSet.readString(2));
player.setPosition(fieldSet.readString(3));
player.setBirthYear(fieldSet.readInt(4));
player.setDebutYear(fieldSet.readInt(5));
return player;
}
}
然后,可以通过正确构造 a 并调用 来读取该文件,如以下示例所示:FlatFileItemReaderread
FlatFileItemReader<Player> itemReader = new FlatFileItemReader<>();
itemReader.setResource(new FileSystemResource("resources/players.csv"));
DefaultLineMapper<Player> lineMapper = new DefaultLineMapper<>();
//DelimitedLineTokenizer defaults to comma as its delimiter
lineMapper.setLineTokenizer(new DelimitedLineTokenizer());
lineMapper.setFieldSetMapper(new PlayerFieldSetMapper());
itemReader.setLineMapper(lineMapper);
itemReader.open(new ExecutionContext());
Player player = itemReader.read();
每次调用 to 都会从文件的每一行返回一个新对象。当文件末尾为
reached,则返回。readPlayernull
按名称映射字段
还有一项额外的功能是 and 都允许的,它在功能上类似于
JDBC 的 .字段的名称可以注入到这些实现中的任何一个中,以提高 mapping 函数的可读性。
首先,将平面文件中所有字段的列名注入到分词器中。
如以下示例所示:DelimitedLineTokenizerFixedLengthTokenizerResultSetLineTokenizer
tokenizer.setNames(new String[] {"ID", "lastName", "firstName", "position", "birthYear", "debutYear"});
A 可以按如下方式使用此信息:FieldSetMapper
public class PlayerMapper implements FieldSetMapper<Player> {
public Player mapFieldSet(FieldSet fs) {
if (fs == null) {
return null;
}
Player player = new Player();
player.setID(fs.readString("ID"));
player.setLastName(fs.readString("lastName"));
player.setFirstName(fs.readString("firstName"));
player.setPosition(fs.readString("position"));
player.setDebutYear(fs.readInt("debutYear"));
player.setBirthYear(fs.readInt("birthYear"));
return player;
}
}
将 FieldSet 自动映射到 Domain Objects
对于许多人来说,必须编写特定内容与编写一样麻烦
特定于 .Spring Batch 通过提供
a 通过将字段名称与 setter 匹配来自动映射字段
在对象上使用 JavaBean 规范。FieldSetMapperRowMapperJdbcTemplateFieldSetMapper
再次使用 football 示例,配置如下所示
以下代码段采用 XML 格式:BeanWrapperFieldSetMapper
<bean id="fieldSetMapper"
class="org.springframework.batch.item.file.mapping.BeanWrapperFieldSetMapper">
<property name="prototypeBeanName" value="player" />
</bean>
<bean id="player"
class="org.springframework.batch.sample.domain.Player"
scope="prototype" />再次使用 football 示例,配置如下所示
以下 Java 代码段:BeanWrapperFieldSetMapper
@Bean
public FieldSetMapper fieldSetMapper() {
BeanWrapperFieldSetMapper fieldSetMapper = new BeanWrapperFieldSetMapper();
fieldSetMapper.setPrototypeBeanName("player");
return fieldSetMapper;
}
@Bean
@Scope("prototype")
public Player player() {
return new Player();
}
对于 中的每个条目,映射器会在新的
对象的实例(因此,需要原型范围)位于
Spring 容器查找与属性名称匹配的 setter 的方式相同。每个都可用
字段,并返回结果对象,没有
需要代码。FieldSetPlayerFieldSetPlayer
固定长度文件格式
到目前为止,仅对分隔文件进行了详细讨论。然而,它们代表 只有一半的文件读取图片。许多使用平面文件的组织都使用固定的 length 格式。固定长度文件示例如下:
UK21341EAH4121131.11customer1 UK21341EAH4221232.11customer2 UK21341EAH4321333.11customer3 UK21341EAH4421434.11customer4 UK21341EAH4521535.11customer5
虽然这看起来像一个大字段,但它实际上代表了 4 个不同的字段:
-
ISIN: 所订购商品的唯一标识符 - 长度为 12 个字符。
-
数量:所订购商品的数量 - 3 个字符长。
-
价格:商品的价格 - 5 个字符长。
-
客户:订购商品的客户的 ID - 长度为 9 个字符。
配置 时,必须提供这些长度中的每一个
以范围的形式。FixedLengthLineTokenizer
以下示例演示如何定义 in
XML:FixedLengthLineTokenizer
<bean id="fixedLengthLineTokenizer"
class="org.springframework.batch.item.file.transform.FixedLengthTokenizer">
<property name="names" value="ISIN,Quantity,Price,Customer" />
<property name="columns" value="1-12, 13-15, 16-20, 21-29" />
</bean>由于 使用 与
前面讨论过,它返回与使用 Delimiter 相同的结果。这
允许使用相同的方法处理其输出,例如使用 .FixedLengthLineTokenizerLineTokenizerFieldSetBeanWrapperFieldSetMapper
|
支持上述范围语法需要在 .但是,这个 bean
在使用批处理命名空间的位置自动声明。 |
以下示例演示如何定义 in
Java:FixedLengthLineTokenizer
@Bean
public FixedLengthTokenizer fixedLengthTokenizer() {
FixedLengthTokenizer tokenizer = new FixedLengthTokenizer();
tokenizer.setNames("ISIN", "Quantity", "Price", "Customer");
tokenizer.setColumns(new Range(1, 12),
new Range(13, 15),
new Range(16, 20),
new Range(21, 29));
return tokenizer;
}
由于 使用 与
上面讨论过,它返回的值与使用 Delimiter 时相同。这
允许使用相同的方法处理其输出,例如使用 .FixedLengthLineTokenizerLineTokenizerFieldSetBeanWrapperFieldSetMapper
单个文件中的多个记录类型
到目前为止,所有的文件读取示例都对 为简单起见:文件中的所有记录都具有相同的格式。但是,这可能会 并非总是如此。文件可能包含具有不同 格式,这些格式需要以不同的方式进行标记化并映射到不同的对象。这 以下文件摘录说明了这一点:
USER;Smith;Peter;;T;20014539;F LINEA;1044391041ABC037.49G201XX1383.12H LINEB;2134776319DEF422.99M005LI
在这个文件中,我们有三种类型的记录,“USER”、“LINEA”和“LINEB”。“USER” 行
对应于一个对象。“LINEA” 和 “LINEB” 都对应于对象
尽管 “LINEA” 比 “LINEB” 有更多的信息。UserLine
该命令单独读取每一行,但我们必须指定不同的 and 对象,以便接收
正确的项目。通过允许地图
的模式和模式要配置。ItemReaderLineTokenizerFieldSetMapperItemWriterPatternMatchingCompositeLineMapperLineTokenizersFieldSetMappers
以下示例演示如何定义 in
XML:FixedLengthLineTokenizer
<bean id="orderFileLineMapper"
class="org.spr...PatternMatchingCompositeLineMapper">
<property name="tokenizers">
<map>
<entry key="USER*" value-ref="userTokenizer" />
<entry key="LINEA*" value-ref="lineATokenizer" />
<entry key="LINEB*" value-ref="lineBTokenizer" />
</map>
</property>
<property name="fieldSetMappers">
<map>
<entry key="USER*" value-ref="userFieldSetMapper" />
<entry key="LINE*" value-ref="lineFieldSetMapper" />
</map>
</property>
</bean>@Bean
public PatternMatchingCompositeLineMapper orderFileLineMapper() {
PatternMatchingCompositeLineMapper lineMapper =
new PatternMatchingCompositeLineMapper();
Map<String, LineTokenizer> tokenizers = new HashMap<>(3);
tokenizers.put("USER*", userTokenizer());
tokenizers.put("LINEA*", lineATokenizer());
tokenizers.put("LINEB*", lineBTokenizer());
lineMapper.setTokenizers(tokenizers);
Map<String, FieldSetMapper> mappers = new HashMap<>(2);
mappers.put("USER*", userFieldSetMapper());
mappers.put("LINE*", lineFieldSetMapper());
lineMapper.setFieldSetMappers(mappers);
return lineMapper;
}
在此示例中,“LINEA” 和 “LINEB” 具有单独的实例,但它们都使用
一样。LineTokenizerFieldSetMapper
该方法使用
以便为每行选择正确的代表。允许
两个具有特殊含义的通配符:问号 (“?”) 只匹配一个
字符,而星号 (“*”) 匹配零个或多个字符。请注意,在
前面的配置,所有模式都以星号结尾,从而有效地使它们
前缀。始终匹配最具体的模式
可能,无论配置中的顺序如何。因此,如果 “LINE*” 和 “LINEA*” 是
两者都列为模式,“LINEA” 将匹配模式 “LINEA*”,而 “LINEB” 将匹配
模式 “LINE*”。此外,单个星号 (“*”) 可以通过匹配
任何其他模式不匹配的任何行。PatternMatchingCompositeLineMapperPatternMatcher#matchPatternMatcherPatternMatcher
下面的示例演示如何匹配 XML 中任何其他模式都不匹配的行:
<entry key="*" value-ref="defaultLineTokenizer" />下面的示例展示了如何匹配 Java 中任何其他模式都不匹配的行:
...
tokenizers.put("*", defaultLineTokenizer());
...
还有一个可用于标记化
独自。PatternMatchingCompositeLineTokenizer
平面文件包含每个记录跨越多行的记录也很常见。自
处理这种情况,则需要更复杂的策略。演示
常见模式可以在样本中找到。multiLineRecords
平面文件中的异常处理
在许多情况下,对行进行标记可能会导致引发异常。多
平面文件不完美,并且包含格式不正确的记录。许多用户选择
在记录问题、原始行和行时跳过这些错误的行
数。这些日志稍后可以手动检查,也可以由另一个批处理作业检查。对于这个
原因,Spring Batch 提供了用于处理解析异常的异常层次结构:和 。 是
在尝试读取
文件。 由接口的实现引发,并指示在分词时遇到更具体的错误。FlatFileParseExceptionFlatFileFormatExceptionFlatFileParseExceptionFlatFileItemReaderFlatFileFormatExceptionLineTokenizer
IncorrectTokenCountException
Both 和 都能够指定
可用于创建 .但是,如果列数
names 与标记行时找到的列数不匹配,则无法创建 ,并且会抛出一个,其中包含
遇到的令牌数和预期数量,如以下示例所示:DelimitedLineTokenizerFixedLengthLineTokenizerFieldSetFieldSetIncorrectTokenCountException
tokenizer.setNames(new String[] {"A", "B", "C", "D"});
try {
tokenizer.tokenize("a,b,c");
}
catch (IncorrectTokenCountException e) {
assertEquals(4, e.getExpectedCount());
assertEquals(3, e.getActualCount());
}
因为分词器配置了 4 个列名,但在
文件,一个被抛出。IncorrectTokenCountException
IncorrectLineLengthException
以固定长度格式格式化的文件时,解析时有其他要求 因为,与分隔格式不同,每列都必须严格遵守其预定义的 宽度。如果总行长不等于此列的最大宽度值,则 Exception 的 Exception 引发,如以下示例所示:
tokenizer.setColumns(new Range[] { new Range(1, 5),
new Range(6, 10),
new Range(11, 15) });
try {
tokenizer.tokenize("12345");
fail("Expected IncorrectLineLengthException");
}
catch (IncorrectLineLengthException ex) {
assertEquals(15, ex.getExpectedLength());
assertEquals(5, ex.getActualLength());
}
上述分词器的配置范围为:1-5、6-10 和 11-15。因此
线路的总长度为 15。但是,在前面的示例中,长度为 5 的行
被传入,导致 an 被抛出。抛出一个
exception 而不是仅映射第一列,从而允许处理
行更早失败,并且包含的信息比失败时包含的信息多,而
尝试读取 .但是,在某些情况下,
线路的长度并不总是恒定的。因此,验证行长度可以
通过 'strict' 属性关闭,如以下示例所示:IncorrectLineLengthExceptionFieldSetMapper
tokenizer.setColumns(new Range[] { new Range(1, 5), new Range(6, 10) });
tokenizer.setStrict(false);
FieldSet tokens = tokenizer.tokenize("12345");
assertEquals("12345", tokens.readString(0));
assertEquals("", tokens.readString(1));
前面的示例与前面的示例几乎相同,只是调用了该示例。此设置告诉分词器不强制执行
line length。A 现已正确创建,并且
返回。但是,它仅包含其余值的空令牌。tokenizer.setStrict(false)FieldSet
FlatFileItemWriter
写出到平面文件与从文件读入存在相同的问题 必须克服。步骤必须能够在 交易方式。
LineAggregator
就像接口需要获取一个项目并将其转换为 一样,文件写入必须有一种方法可以将多个字段聚合成一个字符串
用于写入文件。在 Spring Batch 中,这是 ,如
接口定义如下:LineTokenizerStringLineAggregator
public interface LineAggregator<T> {
public String aggregate(T item);
}
这是 的逻辑对立面。 接受 a 并返回 a ,而接受 an 并返回 .LineAggregatorLineTokenizerLineTokenizerStringFieldSetLineAggregatoritemString
PassThroughLineAggregator
接口的最基本实现是 ,它假定对象已经是一个字符串,或者
它的字符串表示形式可以写入,如下面的代码所示:LineAggregatorPassThroughLineAggregator
public class PassThroughLineAggregator<T> implements LineAggregator<T> {
public String aggregate(T item) {
return item.toString();
}
}
如果直接控制创建字符串
必需,但具有 的优点,例如 transaction 和 restart
支持是必要的。FlatFileItemWriter
简化文件编写示例
现在,接口及其最基本的实现 已经定义,基本的编写流程可以是
解释:LineAggregatorPassThroughLineAggregator
-
将要写入的对象传递给 ,以获得 .
LineAggregatorString -
返回的将写入配置的文件中。
String
以下摘录在代码中表达了这一点:FlatFileItemWriter
public void write(T item) throws Exception {
write(lineAggregator.aggregate(item) + LINE_SEPARATOR);
}
在 XML 中,配置的简单示例可能如下所示:
<bean id="itemWriter" class="org.spr...FlatFileItemWriter">
<property name="resource" value="file:target/test-outputs/output.txt" />
<property name="lineAggregator">
<bean class="org.spr...PassThroughLineAggregator"/>
</property>
</bean>在 Java 中,一个简单的配置示例可能如下所示:
@Bean
public FlatFileItemWriter itemWriter() {
return new FlatFileItemWriterBuilder<Foo>()
.name("itemWriter")
.resource(new FileSystemResource("target/test-outputs/output.txt"))
.lineAggregator(new PassThroughLineAggregator<>())
.build();
}
FieldExtractor
前面的示例对于写入文件的最基本用途可能很有用。
但是,大多数用户都有一个需要
写出,因此必须转换为一行。在文件读取中,以下内容为
必填:FlatFileItemWriter
-
从文件中读取一行。
-
将该行传递到方法中,以便检索 .
LineTokenizer#tokenize()FieldSet -
将 returned from tokenizing 传递给 a ,返回 方法的结果。
FieldSetFieldSetMapperItemReader#read()
文件写入具有类似但相反的步骤:
-
将要写入的项传递给写入器。
-
将项上的字段转换为数组。
-
将结果数组聚合为一行。
因为框架无法知道对象的哪些字段需要
被写出,则必须写入 a 才能完成将
item 添加到数组中,如以下接口定义所示:FieldExtractor
public interface FieldExtractor<T> {
Object[] extract(T item);
}
接口的实现应该从字段
中,可以在
元素或作为固定宽度线条的一部分。FieldExtractor
PassThroughFieldExtractor
在许多情况下,集合(例如数组、 、 或 、 )
需要写出来。从这些集合类型之一中“提取”数组非常
简单。为此,请将集合转换为数组。因此,应在此方案中使用 。需要注意的是,如果
传入的对象不是一种 collection 类型,则返回一个仅包含要提取的项目的数组。CollectionFieldSetPassThroughFieldExtractorPassThroughFieldExtractor
BeanWrapperFieldExtractor
与文件读取部分中描述的一样,它是
通常最好配置如何将域对象转换为对象数组,而不是
而不是自己编写转换。的 提供了这个
功能,如以下示例所示:BeanWrapperFieldSetMapperBeanWrapperFieldExtractor
BeanWrapperFieldExtractor<Name> extractor = new BeanWrapperFieldExtractor<>();
extractor.setNames(new String[] { "first", "last", "born" });
String first = "Alan";
String last = "Turing";
int born = 1912;
Name n = new Name(first, last, born);
Object[] values = extractor.extract(n);
assertEquals(first, values[0]);
assertEquals(last, values[1]);
assertEquals(born, values[2]);
此提取器实现只有一个必需的属性:要
地图。就像 needs 字段名称将所提供对象上的 setter 上的字段映射到 setter 一样,需要名称
映射到 getter 以创建对象数组。值得注意的是,
names 确定数组中字段的顺序。BeanWrapperFieldSetMapperFieldSetBeanWrapperFieldExtractor
分隔文件写入示例
最基本的平面文件格式是所有字段都由分隔符分隔的格式。
这可以使用 .以下示例编写
输出一个简单的 domain 对象,该对象表示客户账户的信用:DelimitedLineAggregator
public class CustomerCredit {
private int id;
private String name;
private BigDecimal credit;
//getters and setters removed for clarity
}
由于正在使用域对象,因此必须提供接口的实现以及要使用的分隔符。FieldExtractor
以下示例演示如何在 XML 中将 与分隔符一起使用:FieldExtractor
<bean id="itemWriter" class="org.springframework.batch.item.file.FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator">
<bean class="org.spr...DelimitedLineAggregator">
<property name="delimiter" value=","/>
<property name="fieldExtractor">
<bean class="org.spr...BeanWrapperFieldExtractor">
<property name="names" value="name,credit"/>
</bean>
</property>
</bean>
</property>
</bean>以下示例演示如何在 Java 中将 与分隔符一起使用:FieldExtractor
@Bean
public FlatFileItemWriter<CustomerCredit> itemWriter(Resource outputResource) throws Exception {
BeanWrapperFieldExtractor<CustomerCredit> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[] {"name", "credit"});
fieldExtractor.afterPropertiesSet();
DelimitedLineAggregator<CustomerCredit> lineAggregator = new DelimitedLineAggregator<>();
lineAggregator.setDelimiter(",");
lineAggregator.setFieldExtractor(fieldExtractor);
return new FlatFileItemWriterBuilder<CustomerCredit>()
.name("customerCreditWriter")
.resource(outputResource)
.lineAggregator(lineAggregator)
.build();
}
在前面的示例中,前面描述的
chapter 用于将 name 和 credit 字段转换为 Object
数组,然后在每个字段之间用逗号写出。BeanWrapperFieldExtractorCustomerCredit
也可以使用 to
自动创建 AND,如以下示例所示:FlatFileItemWriterBuilder.DelimitedBuilderBeanWrapperFieldExtractorDelimitedLineAggregator
@Bean
public FlatFileItemWriter<CustomerCredit> itemWriter(Resource outputResource) throws Exception {
return new FlatFileItemWriterBuilder<CustomerCredit>()
.name("customerCreditWriter")
.resource(outputResource)
.delimited()
.delimiter("|")
.names(new String[] {"name", "credit"})
.build();
}
固定宽度文件写入示例
Delimited 不是平面文件格式的唯一类型。许多人喜欢使用 set width for
在字段之间划定的每一列,这通常称为“固定宽度”。
Spring Batch 在使用 .FormatterLineAggregator
使用上述相同的域对象,可以将其配置为
在 XML 中遵循:CustomerCredit
<bean id="itemWriter" class="org.springframework.batch.item.file.FlatFileItemWriter">
<property name="resource" ref="outputResource" />
<property name="lineAggregator">
<bean class="org.spr...FormatterLineAggregator">
<property name="fieldExtractor">
<bean class="org.spr...BeanWrapperFieldExtractor">
<property name="names" value="name,credit" />
</bean>
</property>
<property name="format" value="%-9s%-2.0f" />
</bean>
</property>
</bean>使用上述相同的域对象,可以将其配置为
在 Java 中遵循:CustomerCredit
@Bean
public FlatFileItemWriter<CustomerCredit> itemWriter(Resource outputResource) throws Exception {
BeanWrapperFieldExtractor<CustomerCredit> fieldExtractor = new BeanWrapperFieldExtractor<>();
fieldExtractor.setNames(new String[] {"name", "credit"});
fieldExtractor.afterPropertiesSet();
FormatterLineAggregator<CustomerCredit> lineAggregator = new FormatterLineAggregator<>();
lineAggregator.setFormat("%-9s%-2.0f");
lineAggregator.setFieldExtractor(fieldExtractor);
return new FlatFileItemWriterBuilder<CustomerCredit>()
.name("customerCreditWriter")
.resource(outputResource)
.lineAggregator(lineAggregator)
.build();
}
前面的大多数示例看起来应该很熟悉。但是,格式 property 是 new。
以下示例显示了 XML 中的 format 属性:
<property name="format" value="%-9s%-2.0f" />以下示例显示了 Java 中的 format 属性:
...
FormatterLineAggregator<CustomerCredit> lineAggregator = new FormatterLineAggregator<>();
lineAggregator.setFormat("%-9s%-2.0f");
...
底层实现是使用 Java 5 中添加的相同功能构建的。Java 基于 C 编程的功能
语言。有关如何配置格式化程序的最详细信息,请参见
Formatter 的 Javadoc。FormatterFormatterprintf
也可以使用 to
自动创建 and,如以下示例所示:FlatFileItemWriterBuilder.FormattedBuilderBeanWrapperFieldExtractorFormatterLineAggregator
@Bean
public FlatFileItemWriter<CustomerCredit> itemWriter(Resource outputResource) throws Exception {
return new FlatFileItemWriterBuilder<CustomerCredit>()
.name("customerCreditWriter")
.resource(outputResource)
.formatted()
.format("%-9s%-2.0f")
.names(new String[] {"name", "credit"})
.build();
}
处理文件创建
FlatFileItemReader与文件资源的关系非常简单。当读者
初始化后,它会打开文件(如果存在),如果不存在,则引发异常。
文件写入并不是那么简单。乍一看,它似乎很相似
简单的合约应该存在 :如果文件已经
exists,抛出一个异常,如果没有,则创建它并开始编写。然而
可能重新启动 可能会导致问题。在正常的重启场景中,
contract is reversed:如果文件存在,则从最后一个已知 good 开始写入该文件
position 的 Position,如果没有,则引发异常。但是,如果文件名
因为这个工作总是一样的吗?在这种情况下,如果文件
存在,除非是重新启动。由于这种可能性,it 包含属性 .将此属性设置为 true 会导致
打开 Writer 时要删除的同名现有文件。FlatFileItemWriterJobFlatFileItemWritershouldDeleteIfExists
XML 项读取器和写入器
Spring Batch 为读取 XML 记录和 将它们映射到 Java 对象以及将 Java 对象写入 XML 记录。
|
对流式处理 XML 的约束
StAX API 用于 I/O,因为其他标准 XML 解析 API 不适合批处理 处理要求(DOM 一次将整个输入加载到内存中,并且 SAX 控制 解析过程,允许用户仅提供回调)。 |
我们需要考虑 XML 输入和输出在 Spring Batch 中是如何工作的。首先,有一个
一些与文件读取和写入不同但在 Spring Batch 中通用的概念
XML 处理。使用 XML 处理,而不是需要的记录行(实例)
要进行标记化,则假定 XML 资源是“片段”的集合
对应于单个记录,如下图所示:FieldSet
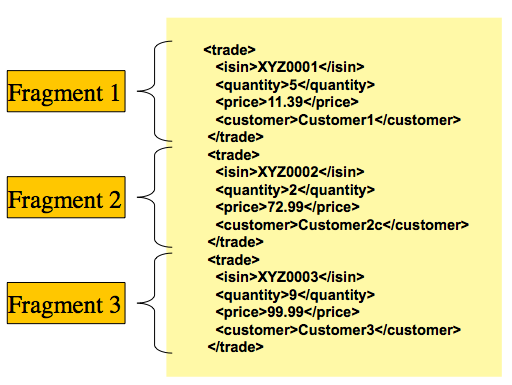
在上述场景中,'trade' 标签被定义为 'root element'。万事 在 '<trade>' 和 '</trade>' 之间被视为一个 “片段”。Spring Batch 使用 Object/XML Mapping (OXM) 将片段绑定到对象。但是,Spring Batch 不是 与任何特定的 XML 绑定技术相关联。典型的用途是委托给 Spring OXM,它 为最流行的 OXM 技术提供统一的抽象。对 Spring OXM 是可选的,您可以选择实现特定于 Spring Batch 的接口 如果需要。与 OXM 支持的技术的关系显示在 下图:
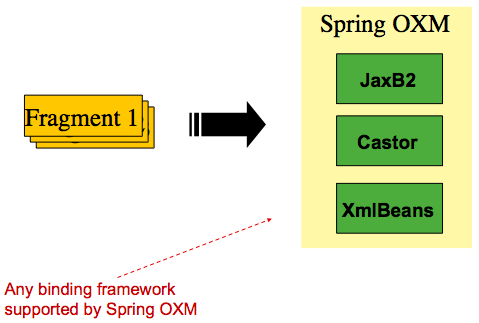
通过介绍 OXM 以及如何使用 XML 片段来表示记录,我们 现在可以更仔细地检查读者和作者。
StaxEventItemReader
该配置为处理
记录。首先,考虑以下一组 XML 记录,这些记录
该 CAN 流程:StaxEventItemReaderStaxEventItemReader
<?xml version="1.0" encoding="UTF-8"?>
<records>
<trade xmlns="https://springframework.org/batch/sample/io/oxm/domain">
<isin>XYZ0001</isin>
<quantity>5</quantity>
<price>11.39</price>
<customer>Customer1</customer>
</trade>
<trade xmlns="https://springframework.org/batch/sample/io/oxm/domain">
<isin>XYZ0002</isin>
<quantity>2</quantity>
<price>72.99</price>
<customer>Customer2c</customer>
</trade>
<trade xmlns="https://springframework.org/batch/sample/io/oxm/domain">
<isin>XYZ0003</isin>
<quantity>9</quantity>
<price>99.99</price>
<customer>Customer3</customer>
</trade>
</records>为了能够处理 XML 记录,需要满足以下条件:
-
根元素名称:构成 对象。示例配置通过 trade 的值演示了这一点。
-
Resource:表示要读取的文件的 Spring Resource。
-
Unmarshaller:Spring OXM 提供的解组工具,用于映射 XML fragment 复制到对象。
以下示例演示如何定义与根一起使用的
元素 、 的资源 和 解组器
在 XML 中调用:StaxEventItemReadertradedata/iosample/input/input.xmltradeMarshaller
<bean id="itemReader" class="org.springframework.batch.item.xml.StaxEventItemReader">
<property name="fragmentRootElementName" value="trade" />
<property name="resource" value="org/springframework/batch/item/xml/domain/trades.xml" />
<property name="unmarshaller" ref="tradeMarshaller" />
</bean>以下示例演示如何定义与根一起使用的
元素 、 的资源 和 解组器
在 Java 中调用:StaxEventItemReadertradedata/iosample/input/input.xmltradeMarshaller
@Bean
public StaxEventItemReader itemReader() {
return new StaxEventItemReaderBuilder<Trade>()
.name("itemReader")
.resource(new FileSystemResource("org/springframework/batch/item/xml/domain/trades.xml"))
.addFragmentRootElements("trade")
.unmarshaller(tradeMarshaller())
.build();
}
请注意,在此示例中,我们选择使用 ,它接受
作为 Map 传入的别名,第一个键和值是 fragment 的名称
(即根元素)和要绑定的对象类型。然后,类似于 a ,
映射到 Object Type 中字段的其他元素的名称描述为
map 中的键/值对。在配置文件中,我们可以使用 Spring 配置
实用程序来描述所需的别名。XStreamMarshallerFieldSet
以下示例演示如何在 XML 中描述别名:
<bean id="tradeMarshaller"
class="org.springframework.oxm.xstream.XStreamMarshaller">
<property name="aliases">
<util:map id="aliases">
<entry key="trade"
value="org.springframework.batch.sample.domain.trade.Trade" />
<entry key="price" value="java.math.BigDecimal" />
<entry key="isin" value="java.lang.String" />
<entry key="customer" value="java.lang.String" />
<entry key="quantity" value="java.lang.Long" />
</util:map>
</property>
</bean>以下示例演示如何在 Java 中描述别名:
@Bean
public XStreamMarshaller tradeMarshaller() {
Map<String, Class> aliases = new HashMap<>();
aliases.put("trade", Trade.class);
aliases.put("price", BigDecimal.class);
aliases.put("isin", String.class);
aliases.put("customer", String.class);
aliases.put("quantity", Long.class);
XStreamMarshaller marshaller = new XStreamMarshaller();
marshaller.setAliases(aliases);
return marshaller;
}
在输入时,读取器会读取 XML 资源,直到它识别出一个新的片段是
即将开始。默认情况下,读取器会匹配元素名称,以识别新的
fragment 即将启动。Reader 从
片段并将文档传递给反序列化器(通常是 Spring 周围的包装器
OXM ) 将 XML 映射到 Java 对象。Unmarshaller
总之,此过程类似于以下 Java 代码,它使用 injection 提供的 Spring 配置:
StaxEventItemReader<Trade> xmlStaxEventItemReader = new StaxEventItemReader<>();
Resource resource = new ByteArrayResource(xmlResource.getBytes());
Map aliases = new HashMap();
aliases.put("trade","org.springframework.batch.sample.domain.trade.Trade");
aliases.put("price","java.math.BigDecimal");
aliases.put("customer","java.lang.String");
aliases.put("isin","java.lang.String");
aliases.put("quantity","java.lang.Long");
XStreamMarshaller unmarshaller = new XStreamMarshaller();
unmarshaller.setAliases(aliases);
xmlStaxEventItemReader.setUnmarshaller(unmarshaller);
xmlStaxEventItemReader.setResource(resource);
xmlStaxEventItemReader.setFragmentRootElementName("trade");
xmlStaxEventItemReader.open(new ExecutionContext());
boolean hasNext = true;
Trade trade = null;
while (hasNext) {
trade = xmlStaxEventItemReader.read();
if (trade == null) {
hasNext = false;
}
else {
System.out.println(trade);
}
}
StaxEventItemWriter
Output 与 input 对称工作。需要一个 、 一个
marshaller 和 .将 Java 对象传递给编组处理程序(通常为
标准 Spring OXM Marshaller),它使用自定义事件写入
编写器,用于过滤为每个
fragment 的 fragment 中。StaxEventItemWriterResourcerootTagNameResourceStartDocumentEndDocument
下面的 XML 示例使用 :MarshallingEventWriterSerializer
<bean id="itemWriter" class="org.springframework.batch.item.xml.StaxEventItemWriter">
<property name="resource" ref="outputResource" />
<property name="marshaller" ref="tradeMarshaller" />
<property name="rootTagName" value="trade" />
<property name="overwriteOutput" value="true" />
</bean>下面的 Java 示例使用 :MarshallingEventWriterSerializer
@Bean
public StaxEventItemWriter itemWriter(Resource outputResource) {
return new StaxEventItemWriterBuilder<Trade>()
.name("tradesWriter")
.marshaller(tradeMarshaller())
.resource(outputResource)
.rootTagName("trade")
.overwriteOutput(true)
.build();
}
前面的配置设置了三个必需的属性并设置了可选的 attrbute,本章前面提到了,用于指定
可以覆盖现有文件。overwriteOutput=true
下面的 XML 示例使用与读取示例中使用的相同的封送处理程序 在本章前面显示:
<bean id="customerCreditMarshaller"
class="org.springframework.oxm.xstream.XStreamMarshaller">
<property name="aliases">
<util:map id="aliases">
<entry key="customer"
value="org.springframework.batch.sample.domain.trade.Trade" />
<entry key="price" value="java.math.BigDecimal" />
<entry key="isin" value="java.lang.String" />
<entry key="customer" value="java.lang.String" />
<entry key="quantity" value="java.lang.Long" />
</util:map>
</property>
</bean>下面的 Java 示例使用与读取示例中使用的相同的编组处理程序 在本章前面显示:
@Bean
public XStreamMarshaller customerCreditMarshaller() {
XStreamMarshaller marshaller = new XStreamMarshaller();
Map<String, Class> aliases = new HashMap<>();
aliases.put("trade", Trade.class);
aliases.put("price", BigDecimal.class);
aliases.put("isin", String.class);
aliases.put("customer", String.class);
aliases.put("quantity", Long.class);
marshaller.setAliases(aliases);
return marshaller;
}
为了用 Java 示例进行总结,下面的代码说明了所有要点 讨论,演示了所需属性的编程设置:
FileSystemResource resource = new FileSystemResource("data/outputFile.xml")
Map aliases = new HashMap();
aliases.put("trade","org.springframework.batch.sample.domain.trade.Trade");
aliases.put("price","java.math.BigDecimal");
aliases.put("customer","java.lang.String");
aliases.put("isin","java.lang.String");
aliases.put("quantity","java.lang.Long");
Marshaller marshaller = new XStreamMarshaller();
marshaller.setAliases(aliases);
StaxEventItemWriter staxItemWriter =
new StaxEventItemWriterBuilder<Trade>()
.name("tradesWriter")
.marshaller(marshaller)
.resource(resource)
.rootTagName("trade")
.overwriteOutput(true)
.build();
staxItemWriter.afterPropertiesSet();
ExecutionContext executionContext = new ExecutionContext();
staxItemWriter.open(executionContext);
Trade trade = new Trade();
trade.setPrice(11.39);
trade.setIsin("XYZ0001");
trade.setQuantity(5L);
trade.setCustomer("Customer1");
staxItemWriter.write(trade);
JSON 项读取器和写入器
Spring Batch 支持读取和写入以下格式的 JSON 资源:
[
{
"isin": "123",
"quantity": 1,
"price": 1.2,
"customer": "foo"
},
{
"isin": "456",
"quantity": 2,
"price": 1.4,
"customer": "bar"
}
]假设 JSON 资源是对应于 单个项目。Spring Batch 不绑定到任何特定的 JSON 库。
JsonItemReader
将 JSON 解析和绑定委托给接口的实现。此接口
旨在通过使用流式处理 API 读取 JSON 对象来实现
成块。目前提供了两种实现:JsonItemReaderorg.springframework.batch.item.json.JsonObjectReader
为了能够处理 JSON 记录,需要满足以下条件:
-
Resource:一个 Spring Resource,表示要读取的 JSON 文件。 -
JsonObjectReader:一个 JSON 对象读取器,用于解析 JSON 对象并将其绑定到项目
以下示例显示了如何定义与
以前的 JSON 资源和基于 Jackson 的 JSON 资源:JsonItemReaderorg/springframework/batch/item/json/trades.jsonJsonObjectReader
@Bean
public JsonItemReader<Trade> jsonItemReader() {
return new JsonItemReaderBuilder<Trade>()
.jsonObjectReader(new JacksonJsonObjectReader<>(Trade.class))
.resource(new ClassPathResource("trades.json"))
.name("tradeJsonItemReader")
.build();
}
JsonFileItemWriter
将项的封送委托给接口。合同
的接口是获取一个对象并将其封送到 JSON 。
目前提供了两种实现:JsonFileItemWriterorg.springframework.batch.item.json.JsonObjectMarshallerString
为了能够写入 JSON 记录,需要满足以下条件:
-
Resource:一个 Spring,表示要写入的 JSON 文件Resource -
JsonObjectMarshaller:将对象编组器编组为 JSON 格式
以下示例演示如何定义 :JsonFileItemWriter
@Bean
public JsonFileItemWriter<Trade> jsonFileItemWriter() {
return new JsonFileItemWriterBuilder<Trade>()
.jsonObjectMarshaller(new JacksonJsonObjectMarshaller<>())
.resource(new ClassPathResource("trades.json"))
.name("tradeJsonFileItemWriter")
.build();
}
多文件输入
在单个 .假设
文件都具有相同的格式,因此支持这种类型的
input 进行 XML 和平面文件处理。请考虑目录中的以下文件:StepMultiResourceItemReader
file-1.txt file-2.txt ignored.txt
file-1.txt 和 file-2.txt 的格式相同,出于业务原因,应为
一起处理。可以通过以下方式读取两个文件
使用通配符。MultiResourceItemReader
以下示例演示如何读取 XML 中带有通配符的文件:
<bean id="multiResourceReader" class="org.spr...MultiResourceItemReader">
<property name="resources" value="classpath:data/input/file-*.txt" />
<property name="delegate" ref="flatFileItemReader" />
</bean>以下示例演示如何在 Java 中读取带有通配符的文件:
@Bean
public MultiResourceItemReader multiResourceReader() {
return new MultiResourceItemReaderBuilder<Foo>()
.delegate(flatFileItemReader())
.resources(resources())
.build();
}
引用的委托是一个简单的 .上面的配置是
来自两个文件的 input,处理回滚和重启场景。应该注意的是,
与任何 一样,添加额外的输入(在本例中为文件)可能会导致
重新启动时出现问题。建议批处理作业与自己的个人作业一起使用
目录,直到成功完成。FlatFileItemReaderItemReader
输入资源排序 by using 以确保在重启场景中的作业运行之间保留资源排序。MultiResourceItemReader#setComparator(Comparator) |
数据库
与大多数企业应用程序样式一样,数据库是 批。但是,由于 系统必须使用的数据集。如果 SQL 语句返回 100 万行,则 结果集可能会将所有返回的结果保存在内存中,直到读取完所有行。 Spring Batch 为此问题提供了两种类型的解决方案:
基于游标的实现ItemReader
使用数据库游标通常是大多数批处理开发人员的默认方法。
因为它是数据库对 “流” 关系数据问题的解决方案。这
Java 类本质上是一种面向对象的机制,用于操作
光标。A 维护当前数据行的游标。调用 a 会将此光标移动到下一行。Spring Batch 基于游标的实现在初始化时打开一个游标,并将游标向前移动一行
每次调用 ,都会返回一个可用于处理的映射对象。然后调用该方法以确保释放所有资源。Spring 核心通过使用回调模式来完全映射
中的所有行 a 和 close 在将控制权返回给方法调用方之前。
但是,在 Batch 中,这必须等到步骤完成。下图显示了
基于游标的工作原理的通用图。请注意,虽然示例
使用 SQL(因为 SQL 是如此广为人知),任何技术都可以实现基本的
方法。ResultSetResultSetnextResultSetItemReaderreadcloseJdbcTemplateResultSetItemReader
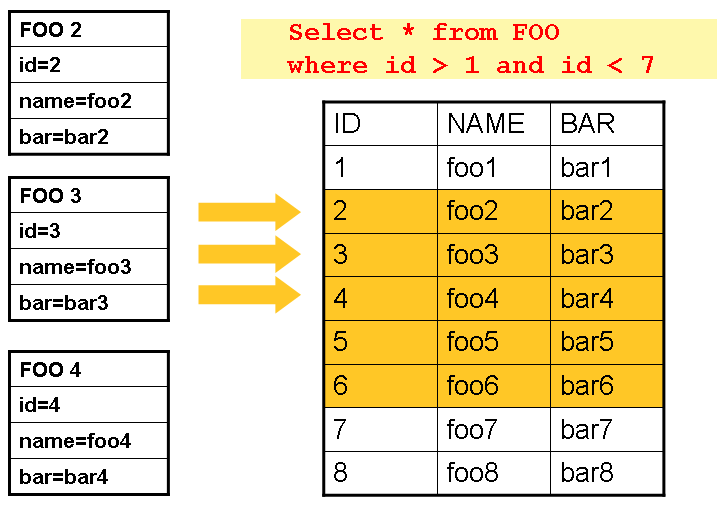
此示例说明了基本模式。给定一个 'FOO' 表,它有三列: , , 和 ,选择 ID 大于 1 但小于 7 的所有行。这
将光标的开头(第 1 行)放在 ID 2 上。此行的结果应为
完全映射的对象。再次调用会将光标移动到下一行
,即 ID 为 3 的 。这些读取的结果在每个 之后写出,允许对对象进行垃圾回收(假设没有实例变量
维护对它们的引用)。IDNAMEBARFooread()Fooread
JdbcCursorItemReader
JdbcCursorItemReader是基于游标的技术的 JDBC 实现。它有效
直接与 a 一起使用,并且需要针对连接运行 SQL 语句
从 .以下数据库架构用作示例:ResultSetDataSource
CREATE TABLE CUSTOMER (
ID BIGINT IDENTITY PRIMARY KEY,
NAME VARCHAR(45),
CREDIT FLOAT
);许多人喜欢对每一行使用域对象,因此以下示例使用
映射对象的接口的实现:RowMapperCustomerCredit
public class CustomerCreditRowMapper implements RowMapper<CustomerCredit> {
public static final String ID_COLUMN = "id";
public static final String NAME_COLUMN = "name";
public static final String CREDIT_COLUMN = "credit";
public CustomerCredit mapRow(ResultSet rs, int rowNum) throws SQLException {
CustomerCredit customerCredit = new CustomerCredit();
customerCredit.setId(rs.getInt(ID_COLUMN));
customerCredit.setName(rs.getString(NAME_COLUMN));
customerCredit.setCredit(rs.getBigDecimal(CREDIT_COLUMN));
return customerCredit;
}
}
由于 共享 关键接口 ,因此 对于
请参阅如何使用 读取此数据以对其进行对比的示例
使用 .对于此示例,假设 中有 1,000 行
数据库。第一个示例使用 :JdbcCursorItemReaderJdbcTemplateJdbcTemplateItemReaderCUSTOMERJdbcTemplate
//For simplicity sake, assume a dataSource has already been obtained
JdbcTemplate jdbcTemplate = new JdbcTemplate(dataSource);
List customerCredits = jdbcTemplate.query("SELECT ID, NAME, CREDIT from CUSTOMER",
new CustomerCreditRowMapper());
运行上述代码片段后,该列表包含 1000 个对象。在查询方法中,从 获取连接,对它运行提供的 SQL,并调用
.将此方法与以下示例中所示的 , 的方法进行对比:customerCreditsCustomerCreditDataSourcemapRowResultSetJdbcCursorItemReader
JdbcCursorItemReader itemReader = new JdbcCursorItemReader();
itemReader.setDataSource(dataSource);
itemReader.setSql("SELECT ID, NAME, CREDIT from CUSTOMER");
itemReader.setRowMapper(new CustomerCreditRowMapper());
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close();
运行上述代码片段后,计数器等于 1,000。如果上面的代码有
将 return 放入列表中,结果将恰好是
与示例相同。但是,它的最大优点是它允许 “流” 项。该方法可以调用一次,项
可以由 写出 ,然后可以使用 获得下一项。这允许以 'chunks' 的形式完成项目读取和写入并提交
定期,这是高性能批处理的本质。此外,它
很容易配置为注入 Spring Batch 。customerCreditJdbcTemplateItemReaderreadItemWriterreadStep
下面的示例演示如何将 an 注入到 XML 中:ItemReaderStep
<bean id="itemReader" class="org.spr...JdbcCursorItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="sql" value="select ID, NAME, CREDIT from CUSTOMER"/>
<property name="rowMapper">
<bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/>
</property>
</bean>下面的示例展示了如何在 Java 中将 an 注入到 a 中:ItemReaderStep
@Bean
public JdbcCursorItemReader<CustomerCredit> itemReader() {
return new JdbcCursorItemReaderBuilder<CustomerCredit>()
.dataSource(this.dataSource)
.name("creditReader")
.sql("select ID, NAME, CREDIT from CUSTOMER")
.rowMapper(new CustomerCreditRowMapper())
.build();
}
其他属性
因为在 Java 中打开游标有很多不同的选项,所以有很多
属性,如下所述
桌子:JdbcCursorItemReader
忽略警告 |
确定是记录 SQLWarnings 还是导致异常。
默认值为 (意味着记录警告)。 |
fetchSize (获取大小) |
为 JDBC 驱动程序提供有关应获取的行数的提示
当 .默认情况下,不会给出任何提示。 |
最大行数 |
设置基础可以的最大行数限制
hold 在任何时候。 |
查询超时 |
将驱动程序等待对象的秒数设置为
跑。如果超出限制,则抛出 a。(请咨询您的Drivers
vendor 文档了解详情)。 |
verifyCursorPosition |
因为 持有的相同内容被传递给
的 ,用户可以称呼自己,这
可能会导致读取器的内部计数出现问题。将此值设置为 causes
如果调用后光标位置与之前不同,则引发异常。 |
saveState |
指示是否应将读取器的状态保存在 提供的 中。默认值为 . |
driverSupportsAbsolute |
指示 JDBC 驱动程序是否支持
在 .对于支持 的 JDBC 驱动程序,建议将其设置为 ,因为它可以提高性能。
尤其是在处理大型数据集时某个步骤失败时。默认为 。 |
setUseSharedExtendedConnection |
指示连接
used for cursor 应该被所有其他处理使用,从而共享相同的
交易。如果此项设置为 ,则游标将以其自己的连接打开
并且不参与为其余步骤处理启动的任何事务。
如果将此标志设置为 then 则必须将 DataSource 包装在 an 中以防止连接关闭,并且
在每次提交后释放。当您将此选项设置为 时,语句用于
Open the Cursor 是使用 'READ_ONLY' 和 'HOLD_CURSORS_OVER_COMMIT' 选项创建的。
这允许在事务启动和在
步骤处理。要使用此功能,您需要一个支持此功能的数据库和一个 JDBC
支持 JDBC 3.0 或更高版本的驱动程序。默认为 。 |
HibernateCursorItemReader
就像普通的 Spring 用户会做出是否使用 ORM 的重要决定一样
解决方案,这会影响他们是使用 a 还是 a ,Spring Batch 用户具有相同的选项。 是游标技术的 Hibernate 实现。
Hibernate 的批量使用一直存在相当大的争议。这主要是因为
Hibernate 最初是为了支持在线应用程序样式而开发的。然而,那
并不意味着它不能用于批处理。最简单的解决方法
此问题是使用 A 而不是 Standard 会话。这将删除
Hibernate 采用的所有缓存和脏检查,这可能会导致
Batch 方案。有关 stateless 和 normal 之间区别的更多信息
Hibernate 会话,请参阅特定 Hibernate 版本的文档。它允许你声明一个 HQL 语句并传入一个 ,它将在每次调用中传回一个项目以读取相同的基本
时尚作为 .以下示例配置使用相同的
'customer credit' 示例作为 JDBC 读取器:JdbcTemplateHibernateTemplateHibernateCursorItemReaderStatelessSessionHibernateCursorItemReaderSessionFactoryJdbcCursorItemReader
HibernateCursorItemReader itemReader = new HibernateCursorItemReader();
itemReader.setQueryString("from CustomerCredit");
//For simplicity sake, assume sessionFactory already obtained.
itemReader.setSessionFactory(sessionFactory);
itemReader.setUseStatelessSession(true);
int counter = 0;
ExecutionContext executionContext = new ExecutionContext();
itemReader.open(executionContext);
Object customerCredit = new Object();
while(customerCredit != null){
customerCredit = itemReader.read();
counter++;
}
itemReader.close();
此配置以完全相同的方式返回对象
如 中所述,假设 Hibernate 映射文件已
为表正确创建。'useStatelessSession' 属性默认
设置为 true,但在此处添加是为了引起人们对打开或关闭它的能力的注意。
还值得注意的是,底层游标的 fetch size 可以通过 property 来设置。与 一样,配置为
简单。ItemReaderCustomerCreditJdbcCursorItemReaderCustomersetFetchSizeJdbcCursorItemReader
下面的示例展示了如何在 XML 中注入 Hibernate:ItemReader
<bean id="itemReader"
class="org.springframework.batch.item.database.HibernateCursorItemReader">
<property name="sessionFactory" ref="sessionFactory" />
<property name="queryString" value="from CustomerCredit" />
</bean>以下示例展示了如何在 Java 中注入 Hibernate:ItemReader
@Bean
public HibernateCursorItemReader itemReader(SessionFactory sessionFactory) {
return new HibernateCursorItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.sessionFactory(sessionFactory)
.queryString("from CustomerCredit")
.build();
}
StoredProcedureItemReader
有时需要使用存储过程来获取游标数据。其工作原理类似于 ,不同之处在于,它
运行查询以获取游标时,它会运行返回游标的存储过程。
存储过程可以通过三种不同的方式返回游标:StoredProcedureItemReaderJdbcCursorItemReader
-
作为返回值(由 SQL Server、Sybase、DB2、Derby 和 MySQL 使用)。
ResultSet -
作为作为 out 参数返回的 ref 游标(由 Oracle 和 PostgreSQL 使用)。
-
作为存储函数调用的返回值。
以下 XML 示例配置使用与前面相同的 'customer credit' 示例 例子:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="rowMapper">
<bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/>
</property>
</bean>以下 Java 示例配置使用与 前面的例子:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
return reader;
}前面的示例依赖于存储过程以
返回结果(前面的选项 1)。ResultSet
如果存储过程返回 (选项 2),那么我们需要提供
返回的 out 参数的位置。ref-cursorref-cursor
以下示例显示了如何使用第一个参数作为 XML:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper">
<bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/>
</property>
</bean>以下示例显示了如何使用第一个参数作为 Java:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
reader.setRefCursorPosition(1);
return reader;
}
如果游标是从存储函数返回的(选项 3),我们需要将
property “function” 设置为 .它默认为 .truefalse
以下示例显示了 XML 中的属性 to:true
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="sp_customer_credit"/>
<property name="function" value="true"/>
<property name="rowMapper">
<bean class="org.springframework.batch.sample.domain.CustomerCreditRowMapper"/>
</property>
</bean>以下示例显示了 Java 中的 property to:true
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("sp_customer_credit");
reader.setRowMapper(new CustomerCreditRowMapper());
reader.setFunction(true);
return reader;
}
在所有这些情况下,我们都需要定义 a 以及 a 和
实际过程名称。RowMapperDataSource
如果存储过程或函数接受参数,则必须声明它们并
set (设置)。以下示例(对于 Oracle)声明了三个
参数。第一个是返回 ref-cursor 的参数,而
第二个和第三个是采用 type 为 的值的 in parameters 。parametersoutINTEGER
以下示例演示如何在 XML 中使用参数:
<bean id="reader" class="o.s.batch.item.database.StoredProcedureItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="procedureName" value="spring.cursor_func"/>
<property name="parameters">
<list>
<bean class="org.springframework.jdbc.core.SqlOutParameter">
<constructor-arg index="0" value="newid"/>
<constructor-arg index="1">
<util:constant static-field="oracle.jdbc.OracleTypes.CURSOR"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="amount"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
<bean class="org.springframework.jdbc.core.SqlParameter">
<constructor-arg index="0" value="custid"/>
<constructor-arg index="1">
<util:constant static-field="java.sql.Types.INTEGER"/>
</constructor-arg>
</bean>
</list>
</property>
<property name="refCursorPosition" value="1"/>
<property name="rowMapper" ref="rowMapper"/>
<property name="preparedStatementSetter" ref="parameterSetter"/>
</bean>以下示例演示如何在 Java 中使用参数:
@Bean
public StoredProcedureItemReader reader(DataSource dataSource) {
List<SqlParameter> parameters = new ArrayList<>();
parameters.add(new SqlOutParameter("newId", OracleTypes.CURSOR));
parameters.add(new SqlParameter("amount", Types.INTEGER);
parameters.add(new SqlParameter("custId", Types.INTEGER);
StoredProcedureItemReader reader = new StoredProcedureItemReader();
reader.setDataSource(dataSource);
reader.setProcedureName("spring.cursor_func");
reader.setParameters(parameters);
reader.setRefCursorPosition(1);
reader.setRowMapper(rowMapper());
reader.setPreparedStatementSetter(parameterSetter());
return reader;
}
除了参数声明之外,我们还需要指定一个 implementation 来设置调用的参数值。这与
以上。Additional Properties 中列出的所有其他属性也适用于 。PreparedStatementSetterJdbcCursorItemReaderStoredProcedureItemReader
分页实现ItemReader
使用数据库游标的另一种方法是运行多个查询,其中每个查询 获取结果的一部分。我们将此部分称为页面。每个查询必须 指定 起始行号 和我们希望在页面中返回的行数。
JdbcPagingItemReader
分页的一种实现是 .需要 a 负责提供 SQL
用于检索构成页面的行的查询。由于每个数据库都有自己的
策略来提供分页支持,我们需要对每个支持的数据库类型使用不同的数据库类型。还有一种是自动检测正在使用的数据库并确定适当的实现。这简化了配置,并且是
推荐的最佳实践。ItemReaderJdbcPagingItemReaderJdbcPagingItemReaderPagingQueryProviderPagingQueryProviderSqlPagingQueryProviderFactoryBeanPagingQueryProvider
这需要您指定一个子句和一个子句。您还可以提供可选子句。这些条款和
required 用于构建 SQL 语句。SqlPagingQueryProviderFactoryBeanselectfromwheresortKey
在 上有一个唯一的 key constraint 是很重要的,以保证
执行之间不会丢失任何数据。sortKey |
打开读取器后,它会将每次调用传回一个项目
基本时尚 .分页发生在幕后,当
需要额外的行。readItemReader
以下 XML 示例配置使用与
cursor-based 如前所述:ItemReaders
<bean id="itemReader" class="org.spr...JdbcPagingItemReader">
<property name="dataSource" ref="dataSource"/>
<property name="queryProvider">
<bean class="org.spr...SqlPagingQueryProviderFactoryBean">
<property name="selectClause" value="select id, name, credit"/>
<property name="fromClause" value="from customer"/>
<property name="whereClause" value="where status=:status"/>
<property name="sortKey" value="id"/>
</bean>
</property>
<property name="parameterValues">
<map>
<entry key="status" value="NEW"/>
</map>
</property>
<property name="pageSize" value="1000"/>
<property name="rowMapper" ref="customerMapper"/>
</bean>以下 Java 示例配置使用与
cursor-based 如前所述:ItemReaders
@Bean
public JdbcPagingItemReader itemReader(DataSource dataSource, PagingQueryProvider queryProvider) {
Map<String, Object> parameterValues = new HashMap<>();
parameterValues.put("status", "NEW");
return new JdbcPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.dataSource(dataSource)
.queryProvider(queryProvider)
.parameterValues(parameterValues)
.rowMapper(customerCreditMapper())
.pageSize(1000)
.build();
}
@Bean
public SqlPagingQueryProviderFactoryBean queryProvider() {
SqlPagingQueryProviderFactoryBean provider = new SqlPagingQueryProviderFactoryBean();
provider.setSelectClause("select id, name, credit");
provider.setFromClause("from customer");
provider.setWhereClause("where status=:status");
provider.setSortKey("id");
return provider;
}
此配置使用 、
必须指定。'pageSize' 属性确定读取的实体数量
从数据库进行每个查询运行。ItemReaderCustomerCreditRowMapper
'parameterValues' 属性可用于为
查询。如果在子句中使用命名参数,则每个条目的键应
匹配命名参数的名称。如果您使用传统的 '?' 占位符,则
key 应该是占位符的编号,从 1 开始。Mapwhere
JpaPagingItemReader
分页的另一种实现是 .JPA 执行
没有类似于 Hibernate 的概念,所以我们不得不使用其他
功能。由于 JPA 支持分页,因此这是很自然的
在使用 JPA 进行批处理时的选择。读取每个页面后,
实体将分离,并且持久化上下文将被清除,以允许实体
在页面处理完毕后进行垃圾回收。ItemReaderJpaPagingItemReaderStatelessSession
允许您声明 JPQL 语句并传入 .然后,它每次调用传回一个项目以读取相同的基本
时尚和其他任何 .分页发生在幕后,当额外的
entities 是必需的。JpaPagingItemReaderEntityManagerFactoryItemReader
以下 XML 示例配置使用与 前面显示的 JDBC 读取器:
<bean id="itemReader" class="org.spr...JpaPagingItemReader">
<property name="entityManagerFactory" ref="entityManagerFactory"/>
<property name="queryString" value="select c from CustomerCredit c"/>
<property name="pageSize" value="1000"/>
</bean>以下 Java 示例配置使用与 前面显示的 JDBC 读取器:
@Bean
public JpaPagingItemReader itemReader() {
return new JpaPagingItemReaderBuilder<CustomerCredit>()
.name("creditReader")
.entityManagerFactory(entityManagerFactory())
.queryString("select c from CustomerCredit c")
.pageSize(1000)
.build();
}
此 configured 以与
,假设对象具有
正确的 JPA 注释或 ORM 映射文件。'pageSize' 属性确定
每次查询执行从数据库中读取的实体数。ItemReaderCustomerCreditJdbcPagingItemReaderCustomerCredit
数据库 ItemWriters
虽然平面文件和 XML 文件都有特定的实例,但没有完全相同的实例
在数据库世界中。这是因为交易提供了所有需要的功能。 实现对于 Files 来说是必需的,因为它们必须像事务一样运行,
跟踪写入的项目并在适当的时候进行冲洗或清理。
数据库不需要此功能,因为写入已经包含在
交易。用户可以创建自己的 DAO 来实现接口或
使用自定义中为通用处理问题编写的 ONE。也
方式,它们应该可以正常工作。需要注意的一件事是性能
以及通过批处理输出提供的错误处理功能。这是最
在使用 Hibernate 时很常见,但在使用
JDBC 批处理模式。批处理数据库输出没有任何固有的缺陷,假设我们
请小心刷新,并且数据中没有错误。但是,任何
写入可能会引起混淆,因为无法知道是哪个单独的项目引起的
异常,或者即使任何单个项目负责,如
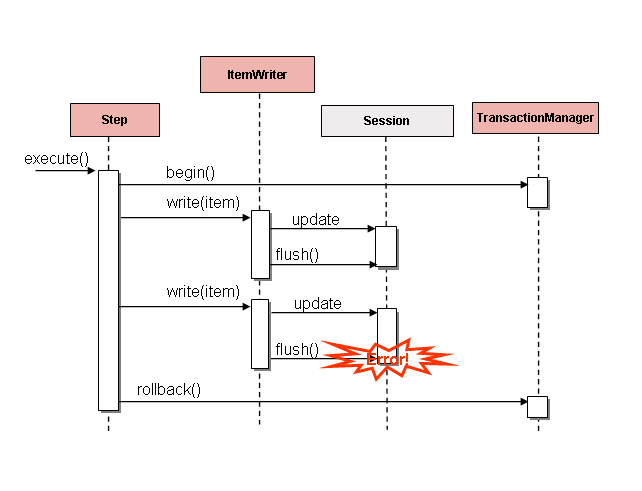
下图:ItemWriterItemWriterItemWriterItemWriterItemWriter
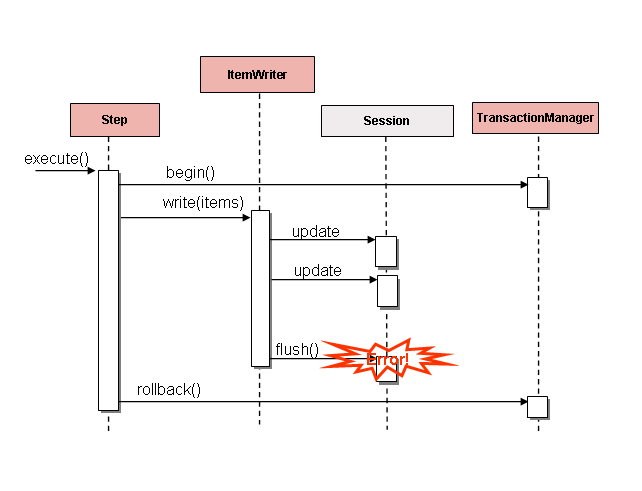
如果在写入之前缓冲了项,则在缓冲区
flushed 的 SET 文件。例如,假设每个块写入 20 个项目,
第 15 项抛出 .就 而言,所有 20 项都写入成功了,因为没有办法知道
错误会发生,直到它们被实际写入为止。调用 None 后,
buffer 被清空并命中异常。在这一点上,他们无能为力。必须回滚事务。通常,此异常可能会导致
要跳过的项目(取决于跳过/重试策略),然后不写入
再。但是,在批处理场景中,无法知道是哪个项目导致了
问题。发生故障时,正在写入整个缓冲区。唯一的方法
解决此问题是在每个项后刷新,如下图所示:DataIntegrityViolationExceptionStepSession#flush()Step
这是一个常见的用例,尤其是在使用 Hibernate 时,以及
的实现 is 在每次调用 .这样做允许
为了可靠地跳过项目,Spring Batch 在内部负责
在错误后调用 的粒度。ItemWriterwrite()ItemWriter
重用现有服务
批处理系统通常与其他应用程序样式结合使用。最
common 是一个在线系统,但它也可能支持集成甚至胖客户端
应用程序,方法是移动每个应用程序样式使用的必要批量数据。对于这个
原因,许多用户希望重用现有的 DAO 或其他服务
他们的批处理作业。Spring 容器本身通过允许任何
necessary 类。但是,在某些情况下,现有服务
需要充当 or ,以满足
另一个 Spring Batch 类,或者因为它确实是某个步骤的 main。是的
为每个需要包装的服务编写一个 Adapter 类相当简单,但是
因为它是一个常见的问题,所以 Spring Batch 提供了 implementations: 和 。这两个类都实现了标准的 Spring
方法,并且设置起来相当简单。ItemReaderItemWriterItemReaderItemReaderAdapterItemWriterAdapter
下面的 XML 示例使用 :ItemReaderAdapter
<bean id="itemReader" class="org.springframework.batch.item.adapter.ItemReaderAdapter">
<property name="targetObject" ref="fooService" />
<property name="targetMethod" value="generateFoo" />
</bean>
<bean id="fooService" class="org.springframework.batch.item.sample.FooService" />下面的 Java 示例使用 :ItemReaderAdapter
@Bean
public ItemReaderAdapter itemReader() {
ItemReaderAdapter reader = new ItemReaderAdapter();
reader.setTargetObject(fooService());
reader.setTargetMethod("generateFoo");
return reader;
}
@Bean
public FooService fooService() {
return new FooService();
}
需要注意的一点是 的合同必须相同
作为 的协定 : 当用尽时,它将返回 。否则,它将返回一个 .其他任何阻止框架知道处理何时结束、
导致无限循环或错误失败,具体取决于实现
的 .targetMethodreadnullObjectItemWriter
下面的 XML 示例使用 :ItemWriterAdapter
<bean id="itemWriter" class="org.springframework.batch.item.adapter.ItemWriterAdapter">
<property name="targetObject" ref="fooService" />
<property name="targetMethod" value="processFoo" />
</bean>
<bean id="fooService" class="org.springframework.batch.item.sample.FooService" />下面的 Java 示例使用 :ItemWriterAdapter
@Bean
public ItemWriterAdapter itemWriter() {
ItemWriterAdapter writer = new ItemWriterAdapter();
writer.setTargetObject(fooService());
writer.setTargetMethod("processFoo");
return writer;
}
@Bean
public FooService fooService() {
return new FooService();
}
防止状态持久性
默认情况下,所有 和 implementations 都存储其当前的
state 中。但是,这可能并不总是如此
所需的行为。例如,许多开发人员选择将他们的数据库读取器
'rerunnable' 使用进程指示器。将额外的列添加到输入数据中,以
指示是否已处理。当正在读取特定记录时(或
written) 的 processed 标志将从 翻转为 。然后,SQL 语句可以
子句中包含额外的语句,例如 ,
从而确保在重新启动时仅返回未处理的记录。在
在这种情况下,最好不要存储任何状态,例如当前行号,
因为它在重新启动时无关紧要。因此,所有读取器和写入器都包含
'saveState' 属性。ItemReaderItemWriterExecutionContextfalsetruewherewhere PROCESSED_IND = false
下面的 Bean 定义显示了如何防止 XML 中的状态持久性:
<bean id="playerSummarizationSource" class="org.spr...JdbcCursorItemReader">
<property name="dataSource" ref="dataSource" />
<property name="rowMapper">
<bean class="org.springframework.batch.sample.PlayerSummaryMapper" />
</property>
<property name="saveState" value="false" />
<property name="sql">
<value>
SELECT games.player_id, games.year_no, SUM(COMPLETES),
SUM(ATTEMPTS), SUM(PASSING_YARDS), SUM(PASSING_TD),
SUM(INTERCEPTIONS), SUM(RUSHES), SUM(RUSH_YARDS),
SUM(RECEPTIONS), SUM(RECEPTIONS_YARDS), SUM(TOTAL_TD)
from games, players where players.player_id =
games.player_id group by games.player_id, games.year_no
</value>
</property>
</bean>以下 bean 定义显示了如何防止 Java 中的状态持久性:
@Bean
public JdbcCursorItemReader playerSummarizationSource(DataSource dataSource) {
return new JdbcCursorItemReaderBuilder<PlayerSummary>()
.dataSource(dataSource)
.rowMapper(new PlayerSummaryMapper())
.saveState(false)
.sql("SELECT games.player_id, games.year_no, SUM(COMPLETES),"
+ "SUM(ATTEMPTS), SUM(PASSING_YARDS), SUM(PASSING_TD),"
+ "SUM(INTERCEPTIONS), SUM(RUSHES), SUM(RUSH_YARDS),"
+ "SUM(RECEPTIONS), SUM(RECEPTIONS_YARDS), SUM(TOTAL_TD)"
+ "from games, players where players.player_id ="
+ "games.player_id group by games.player_id, games.year_no")
.build();
}
上面配置的不会在 for
它参与的任何执行。ItemReaderExecutionContext
创建自定义 ItemReader 和 ItemWriters
到目前为止,本章已经讨论了 Spring 中读写的基本契约
Batch 和一些常见的实现来实现。然而,这些都是公平的
generic,并且有许多可能的情况不是开箱即用的
实现。本节通过一个简单的示例来展示如何创建自定义和实现并正确实现它们的 Contract。还实现了 ,以说明如何使 reader 或
writer 可重启。ItemReaderItemWriterItemReaderItemStream
自定义示例ItemReader
对于此示例,我们创建了一个简单的实现,该
从提供的列表中读取。我们首先实现最基本的 Contract of ,即 方法,如下面的代码所示:ItemReaderItemReaderread
public class CustomItemReader<T> implements ItemReader<T> {
List<T> items;
public CustomItemReader(List<T> items) {
this.items = items;
}
public T read() throws Exception, UnexpectedInputException,
NonTransientResourceException, ParseException {
if (!items.isEmpty()) {
return items.remove(0);
}
return null;
}
}
前面的类采用一个项目列表,并一次返回一个项目,并删除每个项目
从列表中。当列表为空时,它返回 ,从而满足最基本的
的要求,如以下测试代码所示:nullItemReader
List<String> items = new ArrayList<>();
items.add("1");
items.add("2");
items.add("3");
ItemReader itemReader = new CustomItemReader<>(items);
assertEquals("1", itemReader.read());
assertEquals("2", itemReader.read());
assertEquals("3", itemReader.read());
assertNull(itemReader.read());
使 RestartableItemReader
最后一个挑战是使 可重启。目前,如果处理是
interrupted and begin again,则必须从头开始。这是
实际上在许多情况下都有效,但有时最好使用批处理作业
从上次中断处重新开始。关键的判别因素通常是 Reader 是否是有状态的
或无状态。无状态读取器不需要担心可重启性,但
Stateful 必须尝试在 restart 时重建其最后一个已知状态。因此,
我们建议您尽可能保持自定义读取器无状态,因此您不必担心
关于可重启性。ItemReaderItemReader
如果您确实需要存储 state,则应使用该接口:ItemStream
public class CustomItemReader<T> implements ItemReader<T>, ItemStream {
List<T> items;
int currentIndex = 0;
private static final String CURRENT_INDEX = "current.index";
public CustomItemReader(List<T> items) {
this.items = items;
}
public T read() throws Exception, UnexpectedInputException,
ParseException, NonTransientResourceException {
if (currentIndex < items.size()) {
return items.get(currentIndex++);
}
return null;
}
public void open(ExecutionContext executionContext) throws ItemStreamException {
if (executionContext.containsKey(CURRENT_INDEX)) {
currentIndex = new Long(executionContext.getLong(CURRENT_INDEX)).intValue();
}
else {
currentIndex = 0;
}
}
public void update(ExecutionContext executionContext) throws ItemStreamException {
executionContext.putLong(CURRENT_INDEX, new Long(currentIndex).longValue());
}
public void close() throws ItemStreamException {}
}
每次调用该方法时,当前索引都存储在提供的 'current.index' 键中。调用该方法时,会检查 the 以查看它是否
包含具有该键的条目。如果找到该键,则当前索引将移动到
那个位置。这是一个相当微不足道的示例,但它仍然符合通用合同:ItemStreamupdateItemReaderExecutionContextItemStreamopenExecutionContext
ExecutionContext executionContext = new ExecutionContext();
((ItemStream)itemReader).open(executionContext);
assertEquals("1", itemReader.read());
((ItemStream)itemReader).update(executionContext);
List<String> items = new ArrayList<>();
items.add("1");
items.add("2");
items.add("3");
itemReader = new CustomItemReader<>(items);
((ItemStream)itemReader).open(executionContext);
assertEquals("2", itemReader.read());
大多数具有更复杂的重启逻辑。例如,将最后处理的行的行 ID 存储在
光标。ItemReadersJdbcCursorItemReader
还值得注意的是,中使用的 key 不应该是
琐碎。那是因为 same 用于
一个。在大多数情况下,只需在键前加上类名就足够了
以保证唯一性。但是,在极少数情况下,在同一步骤中使用两个相同类型的 (如果需要两个文件
output),则需要更独特的名称。出于这个原因,许多 Spring Batch 和实现都有一个属性,该属性允许 this
key name 被覆盖。ExecutionContextExecutionContextItemStreamsStepItemStreamItemReaderItemWritersetName()
自定义示例ItemWriter
实现自定义在许多方面与示例相似
但差异足以证明它自己的例子。但是,添加
可重启性本质上是相同的,因此本例不涉及。与示例一样,使用 a 是为了使示例尽可能简单,例如
可能:ItemWriterItemReaderItemReaderList
public class CustomItemWriter<T> implements ItemWriter<T> {
List<T> output = TransactionAwareProxyFactory.createTransactionalList();
public void write(Chunk<? extends T> items) throws Exception {
output.addAll(items);
}
public List<T> getOutput() {
return output;
}
}
使 RestartableItemWriter
要使 Restartable,我们将遵循与 相同的过程,添加并实现接口以同步
执行上下文。在此示例中,我们可能必须计算处理的项目数
并将其添加为页脚记录。如果需要这样做,我们可以在我们的 so 以便从执行中重新构造计数器
context 的 URL 中。ItemWriterItemReaderItemStreamItemStreamItemWriter
在许多实际情况下,custom 还会委托给另一个编写器,该编写器本身
是可重新启动的(例如,在写入文件时),否则它会写入
事务资源,因此不需要重新启动,因为它是无状态的。
当你有一个有状态的 writer 时,你可能应该确保实现为
以及 。还要记住,作者的客户端需要注意
,因此您可能需要在配置中将其注册为流。ItemWritersItemStreamItemWriterItemStream
Item Reader 和 Writer 实现
在本节中,我们将向您介绍尚未阅读的读者和作家 在前面的部分中讨论过。
装饰
在某些情况下,用户需要将专用行为附加到预先存在的 .Spring Batch 提供了一些开箱即用的装饰器,这些装饰器可以添加
其他行为到您的 和 implementations。ItemReaderItemReaderItemWriter
Spring Batch 包括以下装饰器:
SynchronizedItemStreamReader
当使用非线程安全的 that 时, Spring Batch 会提供装饰器,该装饰器可用于使线程安全。Spring Batch 提供了一个 to 构造
的 .ItemReaderSynchronizedItemStreamReaderItemReaderSynchronizedItemStreamReaderBuilderSynchronizedItemStreamReader
例如,the 不是线程安全的,不能在
多线程步骤。这个读取器可以用 a 修饰,以便在多线程步骤中安全地使用它。下面是一个如何装饰的示例
这样的读者:FlatFileItemReaderSynchronizedItemStreamReader
@Bean
public SynchronizedItemStreamReader<Person> itemReader() {
FlatFileItemReader<Person> flatFileItemReader = new FlatFileItemReaderBuilder<Person>()
// set reader properties
.build();
return new SynchronizedItemStreamReaderBuilder<Person>()
.delegate(flatFileItemReader)
.build();
}
SingleItemPeekableItemReader
Spring Batch 包含一个装饰器,该装饰器将 peek 方法添加到 .这个 peek
方法允许用户提前速览一个项目。对速览的重复调用将返回相同的结果
item,这是从该方法返回的下一项。Spring Batch 提供了一个来构造 .ItemReaderreadSingleItemPeekableItemReaderBuilderSingleItemPeekableItemReader
| SingleItemPeekableItemReader 的 peek 方法不是线程安全的,因为它不会 可以在多个线程中遵循 peek。只有一个线程偷看 将在下一次调用 READ 时获取该项目。 |
SynchronizedItemStreamWriter
当使用非线程安全的 that 时, Spring Batch 会提供装饰器,该装饰器可用于使线程安全。Spring Batch 提供了一个 to 构造
的 .ItemWriterSynchronizedItemStreamWriterItemWriterSynchronizedItemStreamWriterBuilderSynchronizedItemStreamWriter
例如,the 不是线程安全的,不能在
多线程步骤。这个编写器可以用 a 修饰,以便在多线程步骤中安全地使用它。下面是一个如何装饰的示例
这样的作家:FlatFileItemWriterSynchronizedItemStreamWriter
@Bean
public SynchronizedItemStreamWriter<Person> itemWriter() {
FlatFileItemWriter<Person> flatFileItemWriter = new FlatFileItemWriterBuilder<Person>()
// set writer properties
.build();
return new SynchronizedItemStreamWriterBuilder<Person>()
.delegate(flatFileItemWriter)
.build();
}
MultiResourceItemWriter
将 a 包装并创建一个新的
output 资源(当当前资源中写入的项目计数超过 .Spring Batch 提供了一个
构造 .MultiResourceItemWriterResourceAwareItemWriterItemStreamitemCountLimitPerResourceMultiResourceItemWriterBuilderMultiResourceItemWriter
消息传递 Readers 和 Writers
Spring Batch 为常用的消息传递系统提供了以下读取器和写入器:
AmqpItemReader
这是一个使用 an 来接收或转换
来自 Exchange 的消息。Spring Batch 提供了一个 to 构造
的 .AmqpItemReaderItemReaderAmqpTemplateAmqpItemReaderBuilderAmqpItemReader
AmqpItemWriter
这是一个使用 an 发送消息到
一个 AMQP 交易所。如果
提供的 .Spring Batch 提供了一个
构造 .AmqpItemWriterItemWriterAmqpTemplateAmqpTemplateAmqpItemWriterBuilderAmqpItemWriter
JmsItemReader
这是使用 .模板
应具有 default destination ,该 destination 用于为方法提供项目。Spring Batch 提供了一个来构造 .JmsItemReaderItemReaderJmsTemplateread()JmsItemReaderBuilderJmsItemReader
JmsItemWriter
这是使用 .模板
应具有默认目标,该目标用于发送 中的项目。Spring
Batch 提供了一个用于构造 .JmsItemWriterItemWriterJmsTemplatewrite(List)JmsItemWriterBuilderJmsItemWriter
数据库读取器
Spring Batch 提供以下数据库读取器:
Neo4jItemReader
它是一个从图形数据库 Neo4j 中读取对象的
通过使用分页技术。Spring Batch 提供了一个
构造 .Neo4jItemReaderItemReaderNeo4jItemReaderBuilderNeo4jItemReader
MongoItemReader
这是一个使用
paging 技术。Spring Batch 提供了一个来构造
的实例。MongoItemReaderItemReaderMongoItemReaderBuilderMongoItemReader
HibernateCursorItemReader
用于读取数据库记录
构建在 Hibernate 之上。它执行 HQL 查询,然后在初始化时迭代
在调用方法时,连续返回一个对象
对应于当前行。Spring Batch 提供了一个来构造 .HibernateCursorItemReaderItemStreamReaderread()HibernateCursorItemReaderBuilderHibernateCursorItemReader
数据库写入器
Spring Batch 提供以下数据库编写器:
Neo4jItemWriter
这是一个写入 Neo4j 数据库的实现。
Spring Batch 提供了一个来构造 .Neo4jItemWriterItemWriterNeo4jItemWriterBuilderNeo4jItemWriter
MongoItemWriter
这是一个写入 MongoDB 存储的实现
使用 Spring Data 的 .Spring Batch 提供了一个来构造 .MongoItemWriterItemWriterMongoOperationsMongoItemWriterBuilderMongoItemWriter
RepositoryItemWriter
这是 Spring 的 a 的包装器
数据。Spring Batch 提供了一个 to 构造
这。RepositoryItemWriterItemWriterCrudRepositoryRepositoryItemWriterBuilderRepositoryItemWriter
HibernateItemWriter
这是一个使用 Hibernate 会话来保存或
更新不属于当前 Hibernate 会话的实体。Spring Batch 提供
a 构造 .HibernateItemWriterItemWriterHibernateItemWriterBuilderHibernateItemWriter
专业读者
Spring Batch 提供了以下专用阅读器:
LdifReader
从 中读取 LDIF(LDAP 数据交换格式)记录 ,
解析它们,并为每个执行的 API 返回一个对象。Spring Batch
提供 a 来构造 的实例。LdifReaderResourceLdapAttributereadLdifReaderBuilderLdifReader
专业作家
Spring Batch 提供了以下专门的编写器: