缩放和并行处理
扩展和并行处理
许多批处理问题可以通过单线程、单进程作业来解决。 因此,在考虑之前正确检查这是否满足您的需求总是一个好主意 关于更复杂的实现。衡量实际作业的性能,并查看 最简单的实现首先满足您的需求。您可以读取和写入 几百兆字节的存储时间远远超过一分钟,即使使用标准硬件也是如此。
当您准备好开始通过一些并行处理实现作业时, Spring Batch 提供了一系列选项,本章将介绍这些选项,尽管一些 功能详见其他专题。在高层次上,有两种并行模式 加工:
-
单进程,多线程
-
多进程
这些也分为以下几类:
-
多线程步骤 (单进程)
-
并行步骤(单个进程)
-
步骤 的远程分块(多进程)
-
对步骤进行分区(单进程或多进程)
首先,我们回顾一下单进程选项。然后,我们回顾一下多进程选项。
多线程步骤
开始并行处理的最简单方法是将 a 添加到您的 Step
配置。TaskExecutor
例如,您可以添加 的属性 ,如下所示:tasklet
<step id="loading">
<tasklet task-executor="taskExecutor">...</tasklet>
</step>使用 java 配置时,可以在步骤中添加 a,
如以下示例所示:TaskExecutor
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
@Bean
public Step sampleStep(TaskExecutor taskExecutor) {
return this.stepBuilderFactory.get("sampleStep")
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.build();
}
在此示例中,this 是对另一个 bean 定义的引用,该
实现接口。TaskExecutor 是一个标准的 Spring 接口,因此请查阅 Spring 用户指南以了解可用的详细信息
实现。最简单的多线程是 .taskExecutorTaskExecutorTaskExecutorSimpleAsyncTaskExecutor
上述配置的结果是 execute 通过读取、处理、
并在单独的执行线程中写入每个项目块(每个提交间隔)。
请注意,这意味着要处理的项目没有固定的顺序,并且 chunk
可能包含与单线程大小写相比不连续的项目。在
除了任务执行程序设置的任何限制(例如,它是否由
thread pool),tasklet 配置中有一个限制,默认为 4。
您可能需要增加此值以确保线程池得到充分利用。Step
例如,您可以增加 throttle-limit,如以下示例所示:
<step id="loading"> <tasklet
task-executor="taskExecutor"
throttle-limit="20">...</tasklet>
</step>使用 Java 配置时,构建器提供对限制的访问,如下所示 在以下示例中:
@Bean
public Step sampleStep(TaskExecutor taskExecutor) {
return this.stepBuilderFactory.get("sampleStep")
.<String, String>chunk(10)
.reader(itemReader())
.writer(itemWriter())
.taskExecutor(taskExecutor)
.throttleLimit(20)
.build();
}
另请注意,在
您的步骤,例如 .请确保至少在这些资源中创建池
与步骤中所需的并发线程数一样大。DataSource
使用多线程实现存在一些实际限制
一些常见的 Batch 使用案例。a 中的许多参与者(如读取器和写入者)
是有状态的。如果状态不是按线程隔离的,那么这些组件不是
在多线程 .特别是,大多数现成的 Reader 和
Spring Batch 中的写入器不是为多线程使用而设计的。然而,
可以使用无状态或线程安全的读取器和写入器,并且有一个示例
(称为 ) 在春季
显示使用进程指示器进行跟踪的 Batch Samples(请参阅防止状态持久性)
数据库输入表中已处理的项目数。StepStepStepparallelJob
Spring Batch 提供了 和 的一些实现。通常
他们在 Javadoc 中说明了它们是否是线程安全的,或者您必须做些什么来避免
并发环境中的问题。如果 Javadoc 中没有信息,则可以
检查 implementation 以查看是否有任何状态。如果读取器不是线程安全的,
您可以使用提供的装饰它或自行使用
同步委托人。您可以将调用同步到
处理和写入是 chunk 中最昂贵的部分,您的步骤可能仍会
完成速度比在单线程配置中快得多。ItemWriterItemReaderSynchronizedItemStreamReaderread()
并行步骤
只要需要并行化的应用程序逻辑可以拆分为不同的 职责并分配给各个步骤,则可以在 单个进程。并行步骤执行易于配置和使用。
例如,并行执行步骤非常简单。
如以下示例所示:(step1,step2)step3
<job id="job1">
<split id="split1" task-executor="taskExecutor" next="step4">
<flow>
<step id="step1" parent="s1" next="step2"/>
<step id="step2" parent="s2"/>
</flow>
<flow>
<step id="step3" parent="s3"/>
</flow>
</split>
<step id="step4" parent="s4"/>
</job>
<beans:bean id="taskExecutor" class="org.spr...SimpleAsyncTaskExecutor"/>使用 Java 配置时,并行执行步骤非常简单,如以下示例所示:(step1,step2)step3
@Bean
public Job job() {
return jobBuilderFactory.get("job")
.start(splitFlow())
.next(step4())
.build() //builds FlowJobBuilder instance
.build(); //builds Job instance
}
@Bean
public Flow splitFlow() {
return new FlowBuilder<SimpleFlow>("splitFlow")
.split(taskExecutor())
.add(flow1(), flow2())
.build();
}
@Bean
public Flow flow1() {
return new FlowBuilder<SimpleFlow>("flow1")
.start(step1())
.next(step2())
.build();
}
@Bean
public Flow flow2() {
return new FlowBuilder<SimpleFlow>("flow2")
.start(step3())
.build();
}
@Bean
public TaskExecutor taskExecutor() {
return new SimpleAsyncTaskExecutor("spring_batch");
}
可配置的任务执行程序用于指定应使用哪个实施来执行各个流。默认值为 ,但需要异步才能运行
平行。请注意,该作业可确保拆分中的每个流在
聚合退出状态并进行转换。TaskExecutorSyncTaskExecutorTaskExecutor
请参阅 拆分流 以了解更多详细信息。
远程分块
在远程分块中,处理被拆分到多个进程中。
通过一些中间件相互通信。下图显示了
模式:Step
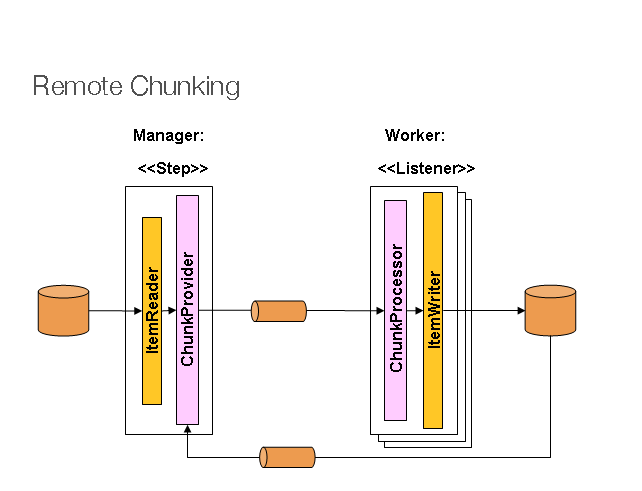
管理器组件是单个进程,而 worker 是多个远程进程。 如果管理器不是瓶颈,则此模式效果最佳,因此处理必须更多 比读取项目更昂贵(在实践中经常出现这种情况)。
管理器是 Spring Batch 的实现,其中替换了
通过知道如何将项目块发送到中间件的通用版本作为
消息。worker 是正在使用的任何中间件的标准侦听器(对于
例如,对于 JMS,它们将是实现),它们的角色是
以使用标准或加号处理项目块。使用它的好处之一
模式是 reader、processor 和 writer 组件是现成的(相同的
将用于 Step 的本地执行)。项目是动态划分的
并且工作是通过中间件共享的,因此,如果侦听器都渴望
consumer 的 Consumers,则负载平衡是自动的。StepItemWriterMessageListenerItemWriterItemProcessorItemWriterChunkProcessor
中间件必须是持久的,有保证的交付,并且每个中间件都有一个使用者 消息。JMS 是显而易见的候选者,但其他选项(例如 JavaSpaces)存在于 网格计算和共享内存产品空间。
有关更多详细信息,请参见 Spring Batch 集成 - 远程分块 部分。
分区
Spring Batch 还提供了一个 SPI 用于对执行进行分区并执行它
远程。在这种情况下,远程参与者是可以
易于配置并用于本地处理。下图显示了
模式:StepStep
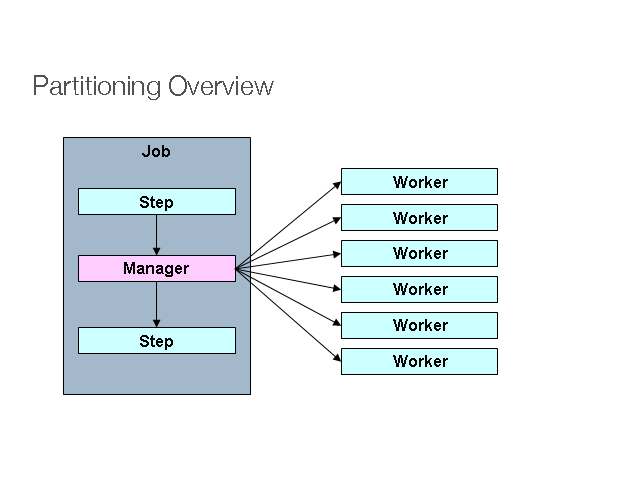
在左侧作为实例序列运行,其中一个实例被标记为 manager。这张图片中的工人都是相同的
实例,它实际上可以代替管理器,从而导致
的结果相同。worker 通常是远程服务,但
也可以是本地执行线程。Manager 发送给 worker 的消息
在这种模式中,不需要持久或有保证的交付。Spring Batch
metadata 确保每个 worker 执行一次,并且只执行一次
每次执行。JobStepStepStepJobJobRepositoryJob
Spring Batch 中的 SPI 由一个特殊的实现(称为)和两个策略接口组成,这些接口需要为特定的
环境。策略接口是 和 ,
它们的作用如下面的序列图所示:StepPartitionStepPartitionHandlerStepExecutionSplitter
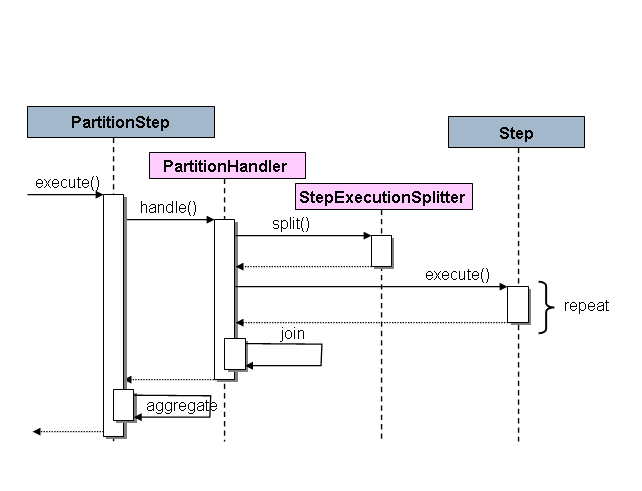
在这种情况下,右侧是 “remote” worker,因此,可能有
许多对象和/或进程扮演这个角色,并且 显示为驱动
执行。StepPartitionStep
以下示例显示了使用 XML 时的配置
配置:PartitionStep
<step id="step1.manager">
<partition step="step1" partitioner="partitioner">
<handler grid-size="10" task-executor="taskExecutor"/>
</partition>
</step>以下示例显示了使用 Java 时的配置
配置:PartitionStep
@Bean
public Step step1Manager() {
return stepBuilderFactory.get("step1.manager")
.<String, String>partitioner("step1", partitioner())
.step(step1())
.gridSize(10)
.taskExecutor(taskExecutor())
.build();
}
与多线程步骤的属性类似,该属性可以防止任务执行程序被来自单个
步。throttle-limitgrid-size
有一个简单的示例可以在 Spring 的单元测试套件中复制和扩展
Batch Samples (请参阅 配置)。partition*Job.xml
Spring Batch 为名为“step1:partition0”的分区创建步骤执行,因此
上。许多人更喜欢将管理器步骤称为 “step1:manager” 以保持一致性。您可以
为步骤使用别名(通过指定 attribute 而不是 attribute)。nameid
PartitionHandler (分区处理程序)
是了解远程处理结构的组件,或者
grid 环境。它能够向远程实例发送请求,并以某种特定于结构的格式(如 DTO)包装。它不必知道
如何拆分输入数据或如何聚合多次执行的结果。
一般来说,它可能也不需要了解弹性或故障转移。
因为在许多情况下,这些是 Fabric 的特征。无论如何,Spring Batch 始终
提供独立于结构的可重启性。失败的 A 总是可以重新启动
并且只有失败的才会重新执行。PartitionHandlerStepExecutionStepStepJobSteps
该接口可以具有各种
结构类型,包括简单的 RMI 远程处理、EJB 远程处理、自定义 Web 服务、JMS、Java
空间、共享内存网格(如 Terracotta 或 Coherence)和网格执行结构
(如 GridGain)。Spring Batch 不包含任何专有网格的实现
或远程处理结构。PartitionHandler
但是,Spring Batch 确实提供了该
使用 Spring 中的策略在单独的执行线程中本地执行实例。该实现称为 。PartitionHandlerStepTaskExecutorTaskExecutorPartitionHandler
这是使用 XML 配置的步骤
命名空间。它也可以显式配置,如
以下示例:TaskExecutorPartitionHandler
<step id="step1.manager">
<partition step="step1" handler="handler"/>
</step>
<bean class="org.spr...TaskExecutorPartitionHandler">
<property name="taskExecutor" ref="taskExecutor"/>
<property name="step" ref="step1" />
<property name="gridSize" value="10" />
</bean>可以在 java 配置中显式配置,
如以下示例所示:TaskExecutorPartitionHandler
@Bean
public Step step1Manager() {
return stepBuilderFactory.get("step1.manager")
.partitioner("step1", partitioner())
.partitionHandler(partitionHandler())
.build();
}
@Bean
public PartitionHandler partitionHandler() {
TaskExecutorPartitionHandler retVal = new TaskExecutorPartitionHandler();
retVal.setTaskExecutor(taskExecutor());
retVal.setStep(step1());
retVal.setGridSize(10);
return retVal;
}
该属性确定要创建的单独步骤执行的数量,因此
它可以与 .或者,它
可以设置为大于可用线程数,这使得
工作更小。gridSizeTaskExecutor
这对于 IO 密集型实例非常有用,例如
将大量文件拷贝或将文件系统复制到 Content Management 中
系统。它还可以通过提供 implementation 来用于远程执行
这是远程调用的代理(例如使用 Spring Remoting)。TaskExecutorPartitionHandlerStepStep
分区程序
它有一个更简单的职责:生成执行上下文作为 input
参数仅用于新步骤执行(无需担心重启)。它有一个
single 方法,如以下接口定义所示:Partitioner
public interface Partitioner {
Map<String, ExecutionContext> partition(int gridSize);
}
此方法的返回值将每个步骤执行 (the ) 的唯一名称与 .名称显示
稍后在 Batch 元数据中作为分区 .这只是一个名称-值对的袋子,因此它可能包含一系列
主键、行号或输入文件的位置。远程 然后
通常使用占位符绑定到上下文输入(步骤 中的后期绑定
范围),如下一节所示。StringExecutionContextStepExecutionsExecutionContextStep#{…}
步骤执行的名称(返回者 中的键 )需要
在 a 的步骤执行中是唯一的,但没有任何其他特定的
要求。执行此操作(并使名称对用户有意义)的最简单方法是
使用 prefix+suffix 命名约定,其中 prefix 是
正在执行(它本身在 中是唯一的),后缀只是一个
计数器。框架中有一个使用此约定。MapPartitionerJobJobSimplePartitioner
一个称为 available for the optional interface called can be available to provide the partition
name 与 partition 本身分开。如果 a 实现了这个
接口,则在重新启动时,仅查询名称。如果分区成本高昂,
这可能是一个有用的优化。必须提供的名称
匹配 .PartitionNameProviderPartitionerPartitionNameProviderPartitioner
将输入数据绑定到步骤
执行的步骤具有
相同的配置,并且它们的输入参数在运行时从 .使用 Spring Batch 的 StepScope 功能很容易做到这一点
(在 Late Binding 一节中有更详细的介绍)。为
例如,如果 create 实例具有属性键
called ,为每个步骤调用指向不同的文件(或目录),
输出可能类似于下表的内容:PartitionHandlerExecutionContextPartitionerExecutionContextfileNamePartitioner
Step Execution Name (key) (步骤执行名称 (key)) |
ExecutionContext (值) |
文件复制:分区 0 |
文件名=/home/data/one |
文件复制:partition1 |
文件名=/home/data/two |
文件复制:partition2 |
文件名=/home/data/three |
然后,可以使用到执行上下文的后期绑定将文件名绑定到步骤。
下面的示例演示如何在 XML 中定义后期绑定:
<bean id="itemReader" scope="step"
class="org.spr...MultiResourceItemReader">
<property name="resources" value="#{stepExecutionContext[fileName]}/*"/>
</bean>以下示例演示如何在 Java 中定义后期绑定:
@Bean
public MultiResourceItemReader itemReader(
@Value("#{stepExecutionContext['fileName']}/*") Resource [] resources) {
return new MultiResourceItemReaderBuilder<String>()
.delegate(fileReader())
.name("itemReader")
.resources(resources)
.build();
}